注意
此命令适用于预测分析模块。单击此处了解更多关于如何激活模块的信息。
一个研究小组收集并发布了有关影响心脏病的因素的详细信息。变量包括年龄、性别、胆固醇水平、最大心率等。本示例基于一个提供心脏病详细信息的公共数据集。原始数据来自于 archive.ics.uci.edu。
在初步探索 CART® 分类 以确定重要预测因子后,研究人员同时使用两者 TreeNet® 分类 ,并从 Random Forests® 分类 同一数据集创建更深入的模型。研究人员根据结果比较模型汇总表和 ROC 图,以评估哪个模型可提供更好的预测结果。有关其他分析的结果,请转到CART® 分类示例和Random Forests® 分类示例。
- 打开样本数据 心脏病二进制.MWX。
- 选择 。
- 从下拉列表中,选择二元响应变量。
- 在响应中,输入心脏病。
- 在响应事件中,选择 是的以指示已将患者标识为患有心脏病。
- 在 连续预测变量中,输入 年龄、 胆固醇 血压 最大心率和 。 旧峰值
- 在 类别预测变量中,输入 性别、 血糖 运动绞痛 静息心电图 斜率 疼痛类型 血管和 。 地中海贫血
- 单击 确定。
解释结果
对于此分析,Minitab 生成 300 个树,最优树数为 298。由于最优树数接近模型生成的最大树数,研究人员使用更多树重复运行分析。
模型汇总
| 总预测变量 | 13 |
|---|---|
| 重要预测变量 | 13 |
| 增长的树数 | 300 |
| 最优树数 | 298 |
| 统计量 | 训练 | 测试 |
|---|---|---|
| 负对数似然平均值 | 0.2556 | 0.3881 |
| ROC 曲线下面积 | 0.9796 | 0.9089 |
| 95% 置信区间 | (0.9664, 0.9929) | (0.8759, 0.9419) |
| 提升 | 2.1799 | 2.1087 |
| 误分类率 | 0.0891 | 0.1617 |
使用 500 个树的示例
- 在结果中选择 调整超参数 。
- 在树数中,输入 500。
- 单击 显示结果。
解释结果
对于此分析,有 500 个生成的树,最优树数是 351。最佳模型使用 0.01 的学习速率,使用 0.5 的子样本部分,并使用 6 作为最大终端节点数。
方法
| 选择最优树数量的标准 | 最大对数似然 |
|---|---|
| 模型验证 | 5 折叠交叉验证 |
| 学习速率 | 0.01 |
| 子样本选择法 | 完全随机 |
| 子样本部分 | 0.5 |
| 每个树的最大终端节点数 | 6 |
| 最小终端节点大小 | 3 |
| 为进行节点拆分而选定的预测变量数 | 预测变量总数 = 13 |
| 已使用的行数 | 303 |
二值响应信息
| 变量 | 类别 | 计数 | % |
|---|---|---|---|
| 心脏病 | 是的 (事件) | 139 | 45.87 |
| 不 | 164 | 54.13 | |
| 所有 | 303 | 100.00 |
方法
| 选择最优树数量的标准 | 最大对数似然 |
|---|---|
| 模型验证 | 5 折叠交叉验证 |
| 学习速率 | 0.001, 0.01, 0.1 |
| 子样本部分 | 0.5, 0.7 |
| 每个树的最大终端节点数 | 6 |
| 最小终端节点大小 | 3 |
| 为进行节点拆分而选定的预测变量数 | 预测变量总数 = 13 |
| 已使用的行数 | 303 |
二值响应信息
| 变量 | 类别 | 计数 | % |
|---|---|---|---|
| 心脏病 | 是的 (事件) | 139 | 45.87 |
| 不 | 164 | 54.13 | |
| 所有 | 303 | 100.00 |
超参数优化
| 模型 | 最优树数 | 负对数似然平均值 | ROC 曲线下面积 | 误分类率 | 学习速率 | 子样本部分 | 最大终端节点数 |
|---|---|---|---|---|---|---|---|
| 1 | 500 | 0.542902 | 0.902956 | 0.171749 | 0.001 | 0.5 | 6 |
| 2* | 351 | 0.386536 | 0.908920 | 0.175027 | 0.010 | 0.5 | 6 |
| 3 | 33 | 0.396555 | 0.900782 | 0.161694 | 0.100 | 0.5 | 6 |
| 4 | 500 | 0.543292 | 0.894178 | 0.178142 | 0.001 | 0.7 | 6 |
| 5 | 374 | 0.389607 | 0.906620 | 0.165082 | 0.010 | 0.7 | 6 |
| 6 | 39 | 0.393382 | 0.901399 | 0.174973 | 0.100 | 0.7 | 6 |
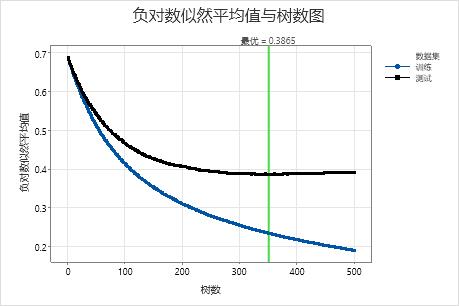
负对数似然性平均值与树数图显示生成的树数的整个曲线。当树数量为 351 时,检验数据的最佳值为 0.3865。
模型汇总
| 总预测变量 | 13 |
|---|---|
| 重要预测变量 | 13 |
| 增长的树数 | 500 |
| 最优树数 | 351 |
| 统计量 | 训练 | 测试 |
|---|---|---|
| 负对数似然平均值 | 0.2341 | 0.3865 |
| ROC 曲线下面积 | 0.9825 | 0.9089 |
| 95% 置信区间 | (0.9706, 0.9945) | (0.8757, 0.9421) |
| 提升 | 2.1799 | 2.1087 |
| 误分类率 | 0.0759 | 0.1750 |
模型汇总
| 总预测变量 | 13 |
|---|---|
| 重要预测变量 | 13 |
| 统计量 | OOB |
|---|---|
| 负对数似然平均值 | 0.4004 |
| ROC 曲线下面积 | 0.9028 |
| 95% 置信区间 | (0.8693, 0.9363) |
| 提升 | 2.1079 |
| 误分类率 | 0.1848 |
模型汇总表显示,当树数为 351 时,负对数似然性平均值对于训练数据约为 0.23,对于检验数据约为 0.39。这些统计量表明模型与 Minitab Random Forests® 创建的模型相似。此外,误分类率也相似。
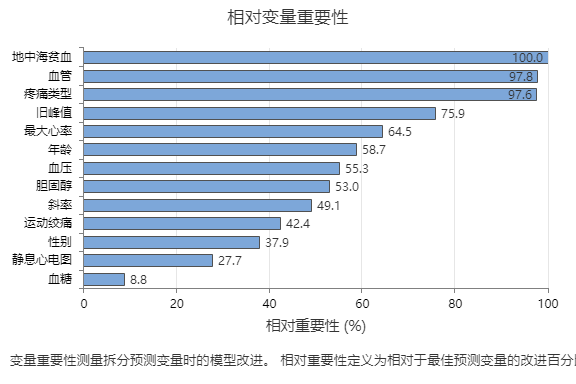
相对变量重要性图按照在对树序列上的预测变量进行拆分时预测变量对模型的改进作用的顺序,绘制预测变量的重要性图。最重要的预测变量为 Thal。如果顶部预测变量 Thal 的贡献为 100%,则下一个重要变量“主要血管”的贡献为 97.8%。这表示在此分类模型中,“主要血管”的重要性是 Thal 重要性的 97.8%。
混淆矩阵
| 预测类别(训练) | 预测类别(测试) | ||||||
|---|---|---|---|---|---|---|---|
| 实际类别 | 计数 | 是的 | 不 | 正确百分比 | 是的 | 不 | 正确百分比 |
| 是的 (事件) | 139 | 124 | 15 | 89.21 | 110 | 29 | 79.14 |
| 不 | 164 | 8 | 156 | 95.12 | 24 | 140 | 85.37 |
| 所有 | 303 | 132 | 171 | 92.41 | 134 | 169 | 82.51 |
| 统计量 | 训练 (%) | 测试 (%) |
|---|---|---|
| 真阳率(敏感度或功效) | 89.21 | 79.14 |
| 假阳率(I 类错误) | 4.88 | 14.63 |
| 假阴率(II 类错误) | 10.79 | 20.86 |
| 真阴率(特异度) | 95.12 | 85.37 |
混淆矩阵显示模型分隔类别的正确程度。在此示例中,正确预测事件的概率为 79.14%。正确预测非事件的概率为 85.37%。
误分类
| 训练 | 测试 | ||||
|---|---|---|---|---|---|
| 实际类别 | 计数 | 分类有误 | 误差百分比 | 分类有误 | 误差百分比 |
| 是的 (事件) | 139 | 15 | 10.79 | 29 | 20.86 |
| 不 | 164 | 8 | 4.88 | 24 | 14.63 |
| 所有 | 303 | 23 | 7.59 | 53 | 17.49 |
误分类率有助于指示模型是否可准确预测新观测值。对于事件预测,检验误分类错误为 20.86%。对于非事件预测,误分类错误为 14.63%,整体误分类错误为 17.49%。
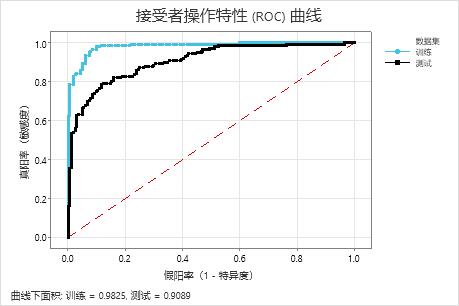
当树数为 351 时,ROC 曲线下面积对于训练数据约为 0.98,对于检验数据约为 0.91。这表明对 CART® 分类 模型有很好的改进。该 Random Forests® 分类 模型的检验 AUROC 为 0.9028,因此这两种方法给出的结果相似。
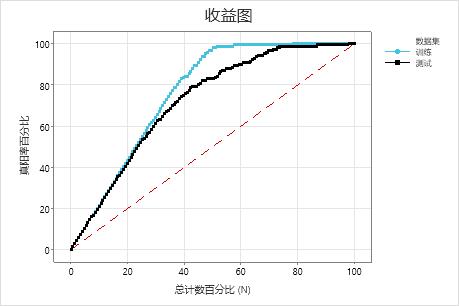
在此示例中,收益图显示参考线上方骤增,然后趋于平直。在这种情况下,大约 40% 的数据占据了大约 80% 的真阳性。这种差异是使用该模型额外获得的增益。
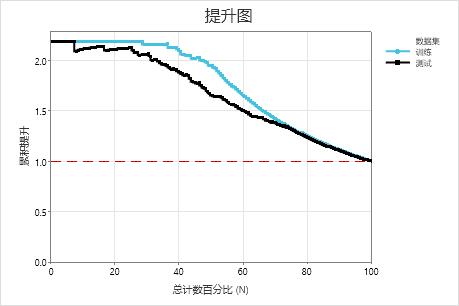
在此示例中,所显示的提升图在参考线上方大幅提升,之后逐渐下降。
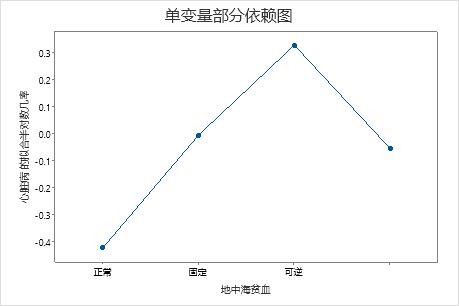
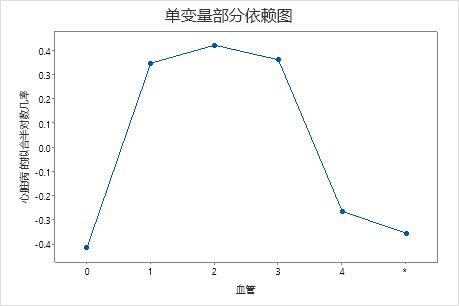
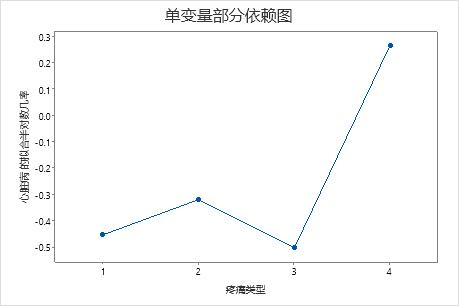
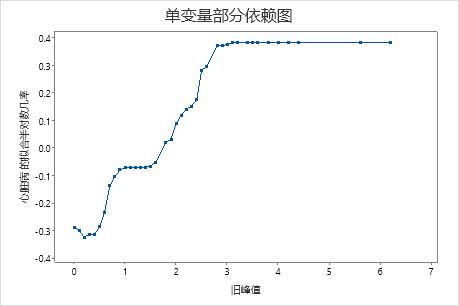
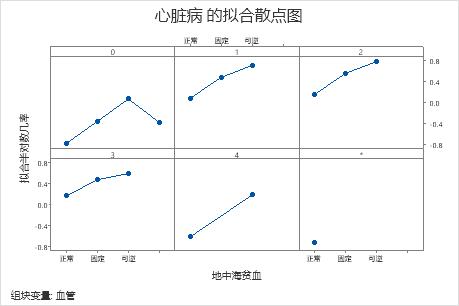
使用部分依赖图可以深入了解重要变量或变量对如何影响拟合响应值。拟合的响应值为 1/2 对数刻度。部分依赖图显示响应与变量之间的关系是线性、单调还是更复杂的关系。
例如,在胸痛类型的部分依赖图中,1/2 对数几率刚开始会发生变化,之后会急剧提升。当胸痛类型为 4 时,心脏病发病率的 1/2 对数几率从大约 −0.04 提升到 0.03。选择 或 为其他变量生成图