注意
此命令适用于 预测分析模块。单击此处了解更多关于如何激活模块的信息。
Random Forests® 模型是解决分类和回归问题的一种方法。与单个分类或回归树相比,该方法对预测变量变化的处理既更准确,又更可靠。宽泛而言,在该过程中,Minitab Statistical Software 从一个 bootstrap 样本构建一个树。Minitab 从预测变量总数中随机选择少量预测变量,以评估每个节点的最佳拆分变量。Minitab 重复这个过程,生成许多树。对于回归案例,模型的预测是来自所有单个树的预测的平均值。
要构建回归树,算法使用最小二乘标准来测量节点的不纯度。对于桌面应用程序,每棵树都会增长,直到无法拆分节点或节点达到拆分内部节点的最小事例数。最小案例数是 分析的一个选项。在 Web 应用中,分析添加了约束,即每棵树的终端节点限制为 4,000 个。有关回归树的构建的更多详细信息,请转到 节点分裂方式 - CART® 回归。下面是特定于 Random Forests® 的详细信息。
Bootstrap 样本
要构建每个树,该算法从完整的数据集中选择随机重置取样(bootstrap 样本)。通常,每个 bootstrap 样本都是不同的,可以包含与原始数据集不同数量的唯一行。如果您只使用 OOB 验证,则 bootstrap 样本的默认大小是原始数据集的大小。如果将样本划分为训练集和测试集,则 bootstrap 样本的默认大小与训练集的大小相同。无论哪种情况,您都可以选择指定 bootstrap 样本小于默认大小。平均而言,bootstrap 样本包含大约 2/3 的数据行。不在 bootstrap 样本中的唯一数据行是用于验证的 OOB 数据。
预测变量的随机选择
在树的每个节点上,算法随机选择预测变量总数的子集 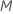 ,以作为拆分变量评估。默认情况下,算法会选择
,以作为拆分变量评估。默认情况下,算法会选择  预测变量以在每个节点进行评估。您可以选择不同数量的预测变量进行评估,从 1 到
预测变量以在每个节点进行评估。您可以选择不同数量的预测变量进行评估,从 1 到 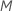 。如果您选择
。如果您选择 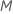 预测变量,算法则评估每个节点的每一个预测变量,从而进行一个名为“bootstrap 森林”的分析。
预测变量,算法则评估每个节点的每一个预测变量,从而进行一个名为“bootstrap 森林”的分析。
在每个节点使用预测变量子集的分析中,评估的预测变量通常在每个节点上都不同。对不同预测变量的评估使森林中的树的相互关联性降低。相关性较弱的树会产生缓慢的学习效果,因此,随着您构建更多树,预测会有所改善。
使用 OOB 数据进行验证
不属于给定树的树构建过程的唯一数据行是 OOB 数据。模型性能度量的计算使用 OOB 数据。有关更多详细信息,请转到 Random Forests® 回归中模型汇总的方法和公式。
对于森林中的给定树,对 OOB 数据中某行的预测使用单个树完成。OOB 数据中某行的预测是来自各个树的预测的平均值。
训练集中某行的预测
森林里的每个树都为训练集中的每一行完成一个单独预测。训练集中一行的预测值是森林中所有树的预测值的平均值。