注意
此命令可与 预测分析模块。单击此处了解如何激活模块。
重要变量
Minitab 统计软件通过排列方法确定变量的重要性 Random Forests®
回归 。排列方法使用袋外数据。对于给定的树, j,在分析中,预测与树的袋外数据。重复对森林中每棵树的预测。然后,计算出袋外数据中至少出现一次的每行的出袋预测的平均值。使用预测来计算袋外数据的平均平方误差:
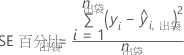
,其中
| 项 | 说明 |
|---|---|
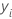 | 第 一行响应变量值 |
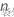 | 出现在整个森林的袋外数据中的数行 |
 | 第 一行的袋外预测 |
然后,通过袋外数据随机对变量 xm 的值进行自上而下。保持响应值和其他预测值相同。然后,使用相同的步骤来计算渗透数据的平均平方误差, 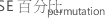 求逆。
求逆。
变量 xm 的重要性来自两个均值平方误差的差异:

小回合值小于10-7 至0。
对于分析中的每一个变量重复此过程。最重要的变量是最重要的变量。相对可变的重要性分数由最重要的变量的重要性进行缩放:
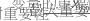
出袋和测试预测
模型精度测量的以下预测计算取决于验证方法。袋外预测只来自一排出袋的树木。对于给定的树, j,在分析中,预测与树的袋外数据。重复对森林中每棵树的预测。然后,计算出袋外数据中至少出现一次的每行的出袋预测的平均值。对于使用袋外数据对模型的评估,响应变量的平均值是袋外数据中所有行的平均值。
对于测试数据集,请使用森林中的每棵树来预测测试数据集中的每一个值。然后,平均所有树木的预测,以获得模型的预测。对于带测试集的模型的评估,平均响应是测试集中行的平均值。
R 平方
R2 的计算使用出袋数据或测试数据。这两种情况的预测不同。一般来说,R2 的公式有以下形式:

均方根误差 (RMSE)
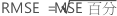
均方误 (MSE)
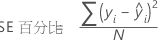
平均绝对偏差 (MAD)
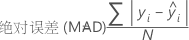
平均绝对百分比误差 (MAPE)

符号
| 项 | 说明 |
|---|---|
| yi |  观测响应值 观测响应值 |
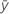 | 平均响应 |
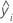 | 的预测响应值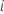 |
| N | 行数 |