准备数据
目标
在分析欺诈检测趋势之前,必须对数据集进行清理和标准化。在本节中,您将:
- 正确的数据类型
- 删除无效记录
- 标准化类别值
- 组织数据集以便分析
- 了解你的数据如何通过 Minitab Data Center
数据管道概述
它 Minitab Data Center 使用数据流水线来准备你的数据。流水线是一系列相互关联的步骤,将原始数据转换为干净、可分析的数据集。
每个数据中心项目都包含一个交互式管道图,表示数据处理步骤。典型的管道流程包含以下节点。
数据来源 → 清理 → 合并/重塑→ 输出
- 数据来源: 连接你的数据并定义其结构。
- 清理: 修正、过滤并标准化你的数据。
- 合并/重塑:合并或重新组织数据集。
- 输出: 将清理后的数据发送到 Minitab Statistical Software 或 Minitab Dashboards。
每一步都以可视化节点的形式出现在流水线中,便于理解和重复使用数据准备流程。
打开数据源
- 在主页中 Minitab Solution Center ,选择 数据准备。
- 选择 添加数据。
- 登录你的仓库。
- 打开 保险欺诈数据。
数据来源 → 清理 → 输出
理解数据中心的观点

准备数据集
- 在 中打开 Insurance Fraud Data Minitab Data Center。
- 确保您在视图中 清理 。
- 选择列并打开 数据准备选项 下拉菜单以访问列清理选项。
1.标准化标识符
-
将 claim_number 数据类型从数字改为 文本。
-
在所有索赔编号前加上 # 符号。
为什么这很重要:防止数值解释并保持格式一致性。
2.删除无效或不切实际的数值
- 过滤 age_of_driver 只包含 100 ≤数值。
- 筛选 annual_income 只包含大于1的值。
为什么这很重要:去除不切实际的年龄和可能影响结果的无效收入记录。
3.标准化类别值
- 在 性别中,替换:
- 男→男
- 女→女性
- 将 address_change 数据类型从数字改为文本。
- 在 address_change中,替换:
- 1 → 是的
- 0 → 不
为什么这很重要:标准化分类提升了可读性、分组和报告能力。
4. 正确的数据类型
- 将 zip_code 数据类型从数字改为文本。
为什么这很重要:保留前导零并防止误数值运算。
5.组织数据集
- 举报欺诈
- injury_claim
- zip_code
为什么这很重要:分类有助于高效地优先排序和审查与欺诈相关的记录。
合并或重塑数据集
使用 Minitab AI 清理数据
它 Minitab Data Center 提供了一个对话式界面,指导你在视图中 清理 的数据准备。
对于上面的示例,您可以在提示中 Minitab AI 输入以下文本以获得与独立步骤相同的结果。
将索赔编号转换为文本。将数字符号添加到索赔编号。删除超过 100 个的驱动程序。将 m 更改为男性,将 f 更改为女性。删除没有有效收入的司机。将address_change更改为文本。地址更改将 1 设置为是,将 0 设置为否。按欺诈、伤害索赔和邮政编码排序。
如需了解更多关于在 Minitab AI Data Center,请访问 使用 Minitab AI 清理数据。
重复使用你的数据准备步骤
- 导出数据准备步骤
- 要保存这些步骤,请将它们导出为 .mdcs 文件。
- 在左侧的 Steps 窗格中,从下拉菜单中进行选择 导出步骤 。
- 该文件将保存到您的下载文件夹或其他保存位置,并使用与数据文件相同的名称。相应地更改名称。
- 在左侧的 Steps 窗格中,从下拉菜单中进行选择 导出步骤 。
- 导入数据准备步骤
- 要将这些步骤应用于新的数据文件,请将它们作为 .mdcs 文件导入。
从窗格的 步骤 下拉菜单中选择 导入步骤 。
探索数据摘要
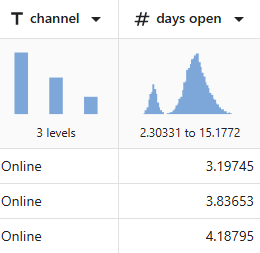
例如, 频道 有3层, 开放日 显示双峰分布。

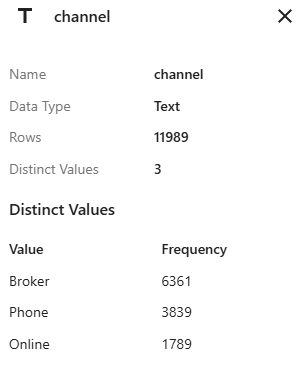
channel 的数据摘要显示了 3 个级别中每个级别的频率。
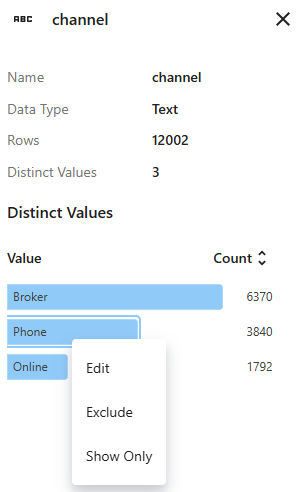
使用右键菜单编辑分组标签,排除该组,或仅显示包含该值的行。
接下来的内容
由于 打开天数 的数据指示两个分配,因此保险公司希望进一步查看此情况。转到 分析您的数据。