데이터 준비
목표
사기 탐지 추세를 분석하기 전에 데이터셋을 정리하고 표준화해야 합니다. 이 섹션에서는 다음과 같은 내용을 하게 됩니다:
- 올바른 데이터 타입
- 유효하지 않은 기록 삭제
- 범주 값 표준화
- 분석을 위해 데이터셋을 정리하세요
- 데이터가 어떻게 흐르는지 이해하세요 Minitab Data Center
데이터 파이프라인 개요
Minitab Data Center 데이터 파이프라인을 사용해 데이터를 준비합니다. 파이프라인은 원시 데이터를 깔끔하고 분석이 가능한 데이터셋으로 변환하는 연결된 단계들의 연속입니다.
모든 데이터 센터 프로젝트에는 데이터 처리 단계를 나타내는 인터랙티브 파이프라인 다이어그램이 포함되어 있습니다. 일반적인 파이프라인 흐름에는 다음과 같은 노드들이 포함됩니다.
데이터 출처 → 정리 합병/재구성→ → 출력
- 데이터 출처: 데이터에 연결하고 그 구조를 정의하세요.
- 정리: 데이터를 수정하고, 필터링하며, 표준화하세요.
- 합병/재구성: 데이터셋을 결합하거나 재구성하세요.
- 출력: 정리된 데이터를 Minitab Statistical Software 또는 Minitab Dashboards로 전송하세요.
각 단계는 파이프라인 내 시각적 노드로 나타나 데이터 준비 과정을 쉽게 이해하고 재사용할 수 있도록 합니다.
데이터 원본 열기
- Minitab Solution Center 홈 페이지에서 . 데이터 준비
- 선택 데이터 추가.
- 저장소에 로그인하세요.
- 열기 보험 사기 데이터.
데이터 출처 → 정리 → 출력
데이터 센터 관점을 이해하기
- 정리 보기
-
 전망을 정리 활용해 다음을 할 수 있습니다:
전망을 정리 활용해 다음을 할 수 있습니다:- 데이터 형식을 변경합니다
- 행 필터링
- 값을 교체하기
- 데이터 정렬
- 범주 표준화
- 데이터 출처 보기
- 데이터셋 스키마나 전체 데이터셋에 영향을 주는 설정을 변경해야 한다면, 데이터 소스 파일 아이콘을 선택해 패널을 옵션 열어보세요.

자세한 내용은 '데이터셋 스키마 관리 ' 또는 '데이터 소스 옵션 설정'으로 이동하세요.
전망을 데이터 출처 활용해 다음을 할 수 있습니다:- 데이터셋 전체 설정 조정
- 스키마 수정(열명 및 타입)
- 파일 가져오기 옵션 구성
각 뷰를 언제 사용해야 하는지:
- 데이터를 수정하는 데 사용 정리 하세요.
- 뷰를 사용해 데이터 출처 데이터셋 구조를 수정하세요.
데이터셋 준비하세요
- 에서 보험 사기 데이터를 Minitab Data Center엽니다.
- 보기에 있는지 확인하십시오. 정리
- 열을 선택하고 드롭다운 메뉴를 데이터 준비 옵션 열어 열 정리 옵션에 액세스합니다.
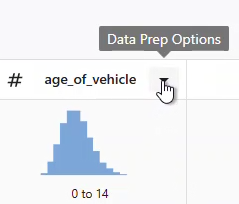
1이어야 합니다. 식별자 표준화
-
데이터 타입 claim_number 숫자에서 텍스트로 변경하세요.
-
모든 청구 번호에 # 기호를 붙이세요.
왜 이것이 중요한가: 수치 해석을 방지하고 서식의 일관성을 유지합니다.
2이어야 합니다. 부당하거나 비현실적인 값은 제거하세요
- 필터 age_of_driver 100 ≤ 값만 포함하도록 하세요.
- 필터 annual_income 1보다 큰 값만 포함하도록 합니다.
왜 이것이 중요한가: 결과를 왜곡할 수 있는 비현실적인 나이와 무효 소득 기록을 제거합니다.
3이어야 합니다. 범주 값 표준화
- 성별에서는 다음을 대체하세요:
- 남성→
- 여성→
- 데이터 타입 address_change 숫자에서 텍스트로 변경하세요.
- address_change에서 다음을 교체하세요:
- 1 → 예
- 0 → 아니야
왜 이것이 중요한가: 표준화된 범주는 가독성, 그룹화, 보고를 향상시킵니다.
4. 올바른 데이터 타입
- 데이터 타입 zip_code 숫자에서 텍스트로 변경하세요.
왜 이것이 중요한가: 선행 0을 보존하고 의도치 않은 숫자 연산을 방지합니다.
5이어야 합니다. 데이터셋을 정리하세요
- 사기 행위 신고
- injury_claim
- zip_code
왜 이것이 중요한가: 분류는 사기 관련 기록의 우선순위를 효율적으로 정하고 검토하는 데 도움을 줍니다.
데이터셋 병합 또는 재구성하기
데이터를 정리하고 표준화하는 것 외에도, 분석 전에 데이터셋을 결합하거나 재구성해야 할 수도 있습니다.
- 조인
- 하나 이상의 키 필드를 사용해 행을 매칭하여 관련 데이터셋을 결합합니다. 이렇게 하면 열이 추가되고 데이터셋이 더 넓어집니다.
자세한 내용은 'Join datasets'로 가세요.
- 결합
- 동일한 구조의 데이터셋을 하나의 데이터셋으로 쌓아둡니다. 이렇게 하면 행이 추가되고 데이터셋이 더 길어집니다.
자세한 정보는 Union datasets를 참조하세요.
- 전치
- 행과 열을 바꿉니다. 이는 데이터가 분석에 적합하지 않은 형식으로 배열되어 있을 때 유용합니다.
자세한 내용은 전관 데이터셋으로 가세요.
Minitab AI를 사용하여 데이터 정리
Minitab Data Center 뷰에서 데이터 준비 정리 를 안내하는 대화형 인터페이스를 제공합니다.
위의 예에서 프롬프트에 Minitab AI 다음 텍스트를 입력하여 개별 단계와 동일한 결과를 얻을 수 있습니다.
청구 번호를 문자로 작성하십시오. 번호를 청구하기 위해 숫자 기호를 추가합니다. 100개보다 오래된 드라이버를 제거합니다. m을 수컷으로, f를 암컷으로 변경합니다. 유효한 소득이 없는 운전자를 제거합니다. address_change 텍스트로 변경합니다. 주소 변경의 경우 1을 예로, 0을 아니오로 만드십시오. 사기, 상해 청구 및 우편번호별로 정렬합니다.
사용에 관한 Minitab AI Data Center자세한 내용은 'Minitab AI 사용법으로 데이터를 정리하기'로 안내하세요.
데이터 준비 단계를 재사용
- 데이터 내보내기 준비 단계
- 단계를 저장하려면 .mdcs 파일로 내보냅니다.
- 왼쪽의 Steps 창에서 드롭다운 메뉴를 선택합니다 단계 내보내기 .
- 파일은 다운로드 폴더 또는 다른 저장 위치에 저장되며 데이터 파일과 동일한 이름을 사용합니다. 그에 따라 이름을 변경합니다.
- 왼쪽의 Steps 창에서 드롭다운 메뉴를 선택합니다 단계 내보내기 .
- 데이터 가져오기 준비 단계
- 새 데이터 파일에 단계를 적용하려면 .mdcs 파일로 가져옵니다.
창의 드롭다운 메뉴에서 단계 선택합니다 단계 가져오기.
데이터 요약 살펴보기
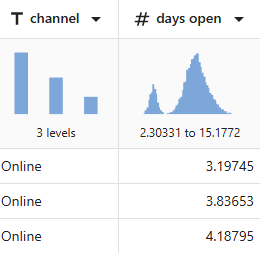
예를 들어, 채널 은 3단계로 구성되어 있고, 개봉일 은 이중분포를 보여줍니다.

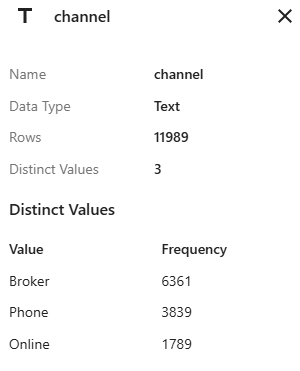
채널에 대한 데이터 요약에는 3가지 수준 각각에 대한 빈도가 표시됩니다.
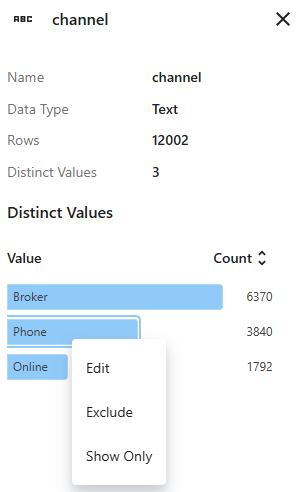
우클릭 메뉴를 사용해 그룹화 라벨을 편집하거나, 그룹을 데이터셋에서 제외하거나, 이 값을 포함하는 행만 표시하세요.
다음 단계
개봉 일수 동안의 데이터는 두 가지 분포를 나타내기 때문에 보험 회사는 이를 더 자세히 살펴보려고 합니다. 데이터 분석으로 이동하십시오.