データの準備
目的
不正検出の傾向を分析する前に、データセットをクリーンアップし標準化する必要があります。このセクションでは、以下の内容を扱います:
- 正しいデータ型
- 無効な記録を削除する
- カテゴリ別値を標準化する
- 分析のためにデータセットを整理する
- データがどのように流れているかを理解しましょう Minitab Data Center
データパイプラインの概要
Minitab Data Center はデータパイプラインを使ってデータを準備します。パイプラインとは、生データをクリーンで分析に適したデータセットに変換する一連の接続されたステップのことです。
すべてのデータセンタープロジェクトには、データ処理ステップを表すインタラクティブなパイプライン図が含まれています。典型的なパイプラインフローには以下のノードが含まれます。
データソース → クリーンアップ → 合体/形を変える→ 出力
- データソース: データに接続し、その構造を定義しましょう。
- クリーンアップ: データを修正し、フィルタリングし、標準化しましょう。
- 合流/リシェイプ: データセットを組み合わせたり再整理したりしましょう。
- 出力: クリーンデータを Minitab Statistical Software や Minitab Dashboardsに送信してください。
各ステップはパイプライン内の視覚的なノードとして現れ、データ準備プロセスを理解し再利用しやすくしています。
データ ソースを開く
- Minitab Solution Center ホームページから「 データ準備」を選択します。
- データを追加を選択します。
- リポジトリにサインインしてください。
- 開く 保険詐欺データ。
データソース → クリーンアップ → 出力
データセンターの見解を理解する
- クリーンアップ 眺める
-
 クリーンアップ ビューを使って以下を行えます:
クリーンアップ ビューを使って以下を行えます:- データ型を変更します
- 行のフィルタリング
- 値の置換
- データのソート
- カテゴリーの標準化
- データソース 眺める
- データセットスキーマやデータセット全体に影響を与える設定を変更する必要がある場合は、データソースファイルアイコンを選択して オプション パネルを開きます。

詳細については、「 データセットスキーマの管理 」または「 データソースオプションの設定」へどうぞ。
データソース ビューを使って以下を行えます:- データセット全体の設定を調整する
- スキーマの変更(列名と型)
- ファイルインポートオプションの設定
各ビューの使用タイミング:
- クリーンアップ を使ってデータを修正しましょう。
- データソース ビューを使ってデータセット構造を修正してください。
データセットを準備する
- Minitab Data Centerで 保険詐欺データ を開きます。
- クリーンアップ ビューが表示されていることを確認します。
- 列を選択し、 データ準備オプション ドロップダウンメニューを開き、列のクリーンアップオプションにアクセスします。
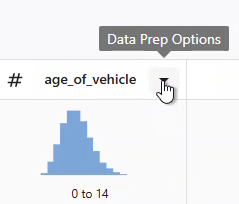
1.識別子の標準化
-
claim_number データタイプを数値から テキストに変更してください。
-
すべてのクレーム番号には # 記号を付けてください。
なぜこれが重要なのか: 数値解釈を防ぎ、フォーマットの一貫性を保ちます。
2.無効または非現実的な価値を取り除く
- フィルター age_of_driver 100≤値のみを含めるようにしてください。
- フィルター annual_income 1より大きい値のみを含みます。
なぜこれが重要なのか: 結果を歪める可能性のある非現実的な年齢や無効な収入記録を除去します。
3.カテゴリ別値を標準化する
- 性別では、置き換えてください:
- 男性→男性
- 女性→女性
- データタイプ address_change 数値からテキストに変更してください。
- address_changeでは、以下を置き換えます:
- 1 →はい
- 0 → いいえ
なぜこれが重要なのか: 標準化されたカテゴリは、可読性、グループ化、報告性を向上させます。
4. 正しいデータ型
- データ 型zip_code 数値からテキストに変更してください。
なぜこれが重要なのか: 先頭のゼロを保持し、意図しない数値演算を防ぎます。
5.データセットの整理
- 報告された詐欺
- injury_claim
- zip_code
なぜこれが重要なのか: ソーティングは詐欺関連の記録を優先順位付けし、効率的に確認するのに役立ちます。
データセットの統合や再形成
データのクリーニングや標準化に加え、分析前にデータセットをまとめたり再整理したりする必要がある場合もあります。
- 結合
- 関連するデータセットを1つ以上のキーフィールドで行を照合して組み合わせます。これにより列が追加され、データセットの幅が広がります。
詳細については、「 データセットの結合」をご覧ください。
- ユニオン
- 同じ構造のデータセットを1つのデータセットにまとめます。これにより行数が増え、データセットが長くなります。
詳細は Union datasetsをご覧ください。
- 転置
- 行と列を切り替えます。これは、データが分析に理想的でない形式で整理されている場合に有用です。
詳細は 「Transpose datasets」をご覧ください。
Minitab AIを使用してデータをクリーンアップする
Minitab Data Center は クリーンアップ ビューでデータ準備を案内する会話型インターフェースを提供します。
上記の例では、 Minitab AI プロンプトに次のテキストを入力すると、個々のステップと同じ結果が得られます。
請求番号をテキストにします。番号を請求するために番号記号を追加します。100 より古いドライバーを削除します。m を男性に、f を女性に変更します。有効な収入のないドライバーを削除します。address_changeをテキストに変更します。住所変更の場合は 1 から yes、0 から no にします。詐欺、傷害請求、郵便番号で並べ替えます。
Data Centerでの Minitab AI 使用についての詳細は、「 Minitab AIを使ってデータをクリーンアップする」をご覧ください。
データ準備の手順を再利用しました
- データ準備のエクスポート手順
- 手順を保存するには、手順を .mdcs ファイルとしてエクスポートします。
- 左側の [ステップ] ウィンドウで、ドロップダウン メニューから [ エクスポート手順 ] を選択します。
- ファイルはダウンロードフォルダまたはその他の保存場所に保存され、データファイルと同じ名前が使用されます。それに応じて名前を変更します。
- 左側の [ステップ] ウィンドウで、ドロップダウン メニューから [ エクスポート手順 ] を選択します。
- データのインポート準備手順
- 手順を新しいデータ ファイルに適用するには、手順を .mdcs ファイルとしてインポートします。
ステップ ペインのドロップダウンメニューから インポート手順 を選択します。
データサマリーの探索
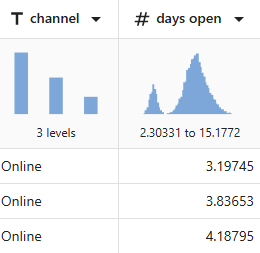
例えば、 チャンネル は3つのレベルで、 開いている日 は二峰分布を示します。

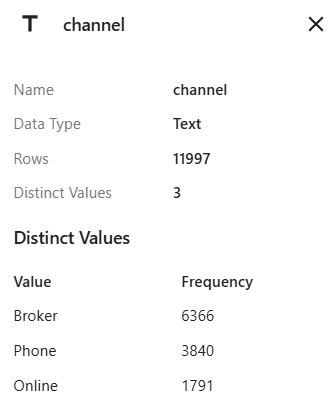
チャネル のデータ サマリーには、3 つのレベルのそれぞれの周波数が表示されます。
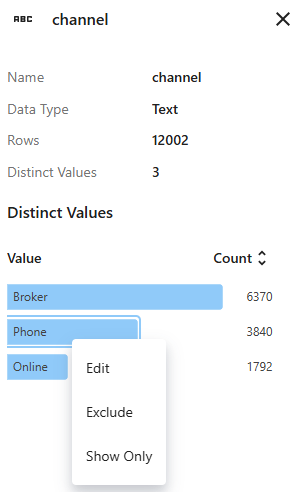
右クリックメニューを使ってグループ化ラベルを編集したり、グループをデータセットから除外したり、この値を含む行だけを表示することができます。
次の作業
オープン日数 のデータは 2 つの分布を示しているため、保険会社はこれをさらに詳しく調べたいと考えています。データの分析にアクセスします。