Nota
Este comando está disponible con el Módulo de análisis predictivo. Haga clic aquí para obtener más información sobre cómo activar el módulo.
Búsqueda del mejor tipo de modelo
Un equipo de investigadores recopila y publica información detallada sobre los factores que afectan las enfermedades cardíacas. Las variables incluyen edad, sexo, niveles de colesterol, frecuencia cardíaca máxima, y más. Este ejemplo se basa en un conjunto de datos públicos que proporciona información detallada sobre las enfermedades cardíacas. Los datos originales son de archive.ics.uci.edu.
Los investigadores quieren encontrar un modelo que realice las predicciones más precisas posibles. Los investigadores utilizan el modelo Descubrir el mejor modelo (Respuesta binaria) para comparar el rendimiento predictivo de 4 tipos de modelos: regresión logística binaria, TreeNet®, Random Forests® y CART®. Los investigadores planean explorar más a fondo el tipo de modelo con el mejor rendimiento predictivo.
- Abra los datos de muestra, CorazonDiseaseBinarioMejorModelo.MWX.
- Elija .
- En Respuesta, ingrese 'Enfermedad cardíaca'.
- En Predictores continuos, ingrese Edad, 'Descansar la presión arterial', Colesterol, 'Frecuencia cardíaca máxima' y ' Old Peak'.
- En Predictores categóricos, ingrese Sexo, ' Tipo de dolor torácico', 'Azúcar en la sangre en ayunas', 'Rest ECG', 'Ejercicio Angina', Pendiente, 'Buques principales' y Thal.
- Haga clic en Aceptar.
Interpretar los resultados
La tabla Selección de modelos compara el rendimiento de los diferentes tipos de modelos. El modelo Random Forests® tiene el valor mínimo de log-verosimilitud promedio. Los siguientes resultados son para el mejor modelo de Random Forests®.
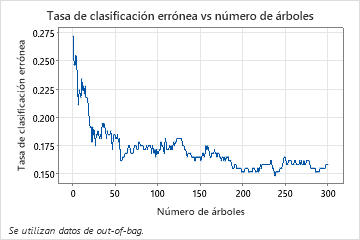
La gráfica Tasa de clasificaciones erróneas vs. número de árboles muestra toda la curva sobre el número de árboles cultivados. La tasa de clasificaciones erróneas es aproximadamente 0.16.
La tabla Resumen del modelo muestra que la log-verosimilitud negativa promedio aproximada es 0.39.
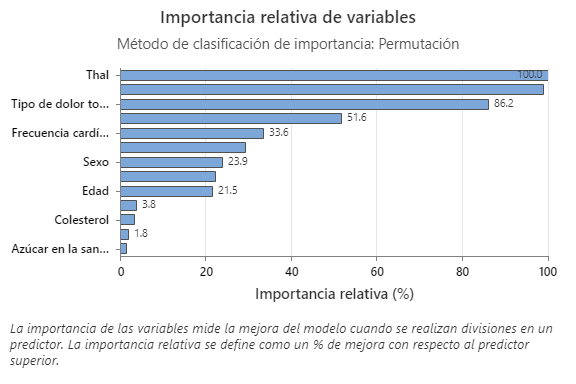
La gráfica Importancia relativa de las variables presenta los predictores en el orden de su efecto en la mejora del modelo cuando se realizan divisiones en un predictor sobre la secuencia de árboles. La variable predictora más importante es Thal. Si la contribución de la variable predictora más importante, Thal, es 100%, entonces la siguiente variable importante, Grandes vasos, tiene una contribución de 98.9%. Esto significa que Grandes vasos es 98.9% tan importante como Thal en este modelo de clasificación.
La matriz de confusión muestra qué tan efectivo es el modelo para separar las clases correctamente. En este ejemplo, la probabilidad de que un evento sea pronosticado correctamente es 87%. La probabilidad de que un no evento sea pronosticado correctamente es 81%.
La tasa de clasificación errónea ayuda a indicar si el modelo pronosticará con exactitud nuevas observaciones. Para la predicción de eventos, el error por clasificación errónea out-of-bag es aproximadamente 13%. Para la predicción de no eventos, el error de clasificación errónea es aproximadamente 19%. En general, el error de clasificación errónea para los datos de prueba es aproximadamente 16%.
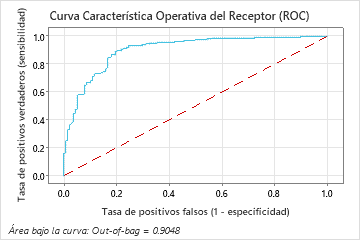
El área bajo la curva ROC para el modelo Random Forests® es aproximadamente 0.90 para los datos out-of-bag.
Método
| Ajustar un modelo de regresión logística escalonada con términos lineales y términos de orden 2. |
|---|
| Ajustar 6 modelo(s) de Clasificación TreeNet®. |
| Ajustar 3 modelo(s) de Clasificación Random Forests® con el tamaño de la muestra de bootstrap igual al tamaño de los datos de entrenamiento de 303. |
| Ajustar un modelo óptimo de clasificación CART®. |
| Seleccione el modelo con la máxima logverosimilitud de la valoración cruzada de 5 pliegues. |
| Número total de filas: 303 |
| Filas utilizadas para el modelo de regresión logística: 303 |
| Filas utilizadas para los modelos basados en árboles: 303 |
Información de respuesta binaria
| Variable | Clase | Conteo | % |
|---|---|---|---|
| Enfermedad cardíaca | 1 (Evento) | 165 | 54.46 |
| 0 | 138 | 45.54 | |
| Todo | 303 | 100.00 |
| Mejor modelo dentro del tipo | Log-verosimilitud promedio | Área bajo la curva ROC | Tasa de clasificación errónea |
|---|---|---|---|
| Random Forests®* | 0.3904 | 0.9048 | 0.1584 |
| TreeNet® | 0.3907 | 0.9032 | 0.1520 |
| Regresión logística | 0.4671 | 0.9142 | 0.1518 |
| CART® | 1.8072 | 0.7991 | 0.2080 |
Hiperparámetros para el mejor modelo Random Forests®
| Número de muestras de bootstrap | 300 |
|---|---|
| Tamaño de la muestra | Igual que el tamaño de los datos de entrenamiento de 303 |
| Número de predictores seleccionados para la división de nodos | Raíz cuadrada del número total de predictores = 3 |
| Tamaño mínimo del nodo interno | 8 |
Resumen del modelo
| Total de predictores | 13 |
|---|---|
| Predictores importantes | 13 |
| Estadísticas | Out-of-Bag |
|---|---|
| Logverosimilitud promedio | 0.3904 |
| Área bajo la curva ROC | 0.9048 |
| IC de 95% | (0.8706, 0.9389) |
| Elevación | 1.7758 |
| Tasa de clasificación errónea | 0.1584 |
Matriz de confusión
| Clase de predicción (Out-of-Bag) | ||||
|---|---|---|---|---|
| Clase real | Conteo | 1 | 0 | % Correcto |
| 1 (Evento) | 165 | 143 | 22 | 86.67 |
| 0 | 138 | 26 | 112 | 81.16 |
| Todo | 303 | 169 | 134 | 84.16 |
| Estadísticas | Out-of-Bag (%) |
|---|---|
| Tasa de positivos verdaderos (sensibilidad o potencia) | 86.67 |
| Tasa de positivos falsos (error tipo I) | 18.84 |
| Tasa de negativos falsos (error tipo II) | 13.33 |
| Tasa de negativos verdaderos (especificidad) | 81.16 |
Clasificación errónea
| Out-of-Bag | |||
|---|---|---|---|
| Conteo | Clasificado erróneamente | % Error | |
| Clase real | |||
| 1 (Evento) | 165 | 22 | 13.33 |
| 0 | 138 | 26 | 18.84 |
| Todo | 303 | 48 | 15.84 |
Selección de un modelo alternativo
Los investigadores pueden ver los resultados de otros modelos al buscar el mejor modelo. Para un modelo TreeNet®, puede seleccionar entre un modelo que formó parte de la búsqueda o especificar hiperparámetros para un modelo diferente.
- Seleccione Seleccionar modelo alternativo.
- En Tipo de modelo, seleccione TreeNet®.
- En Seleccionar un modelo existente, elija el tercer modelo, que tiene el mejor valor log-verosimilitud mínima promedio.
- Haga clic en Mostrar resultados.
Interpretar los resultados
Para este análisis, se generan 300 árboles y el número óptimo de árboles es 46. El modelo utiliza una tasa de aprendizaje de 0.1 y una fracción de submuestra de 0.5. número máximo de nodos terminales por árbol es 6.
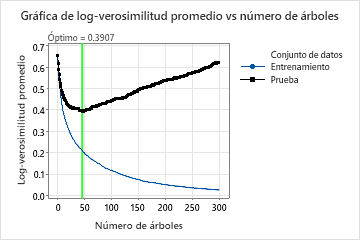
La gráfica de log-verosimilitud promedio vs número de árboles muestra toda la curva sobre el número de árboles crecidos. El valor óptimo para los datos de prueba es 0.3907 cuando el número de árboles es 46.
Resumen del modelo
| Total de predictores | 13 |
|---|---|
| Predictores importantes | 13 |
| Número de árboles cultivados | 300 |
| Número óptimo de árboles | 46 |
| Estadísticas | Entrenamiento | Prueba |
|---|---|---|
| Logverosimilitud promedio | 0.2088 | 0.3907 |
| Área bajo la curva ROC | 0.9842 | 0.9032 |
| IC de 95% | (0.9721, 0.9964) | (0.8683, 0.9381) |
| Elevación | 1.8364 | 1.7744 |
| Tasa de clasificación errónea | 0.0726 | 0.1520 |
Cuando el número de árboles es 46, la tabla de Resumen del modelo indica que la log-verosimilitud negativa promedio es aproximadamente 0.21 para los datos de entrenamiento y aproximadamente 0.39 los datos de prueba.
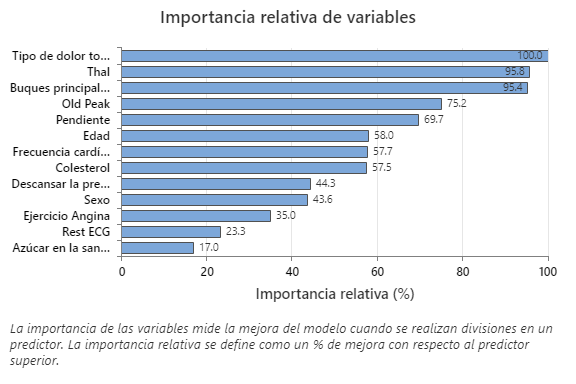
La gráfica Importancia relativa de las variables presenta los predictores en el orden de su efecto en la mejora del modelo cuando se realizan divisiones en un predictor sobre la secuencia de árboles. La variable predictora más importante es Tipo de dolor de pecho. Si la contribución de la variable predictora más importante, Tipo de dolor de pecho, es 100%, entonces la siguiente variable importante, Thal, tiene una contribución de 95.8%. Esto significa que Thal es 95.8% tan importante como Tipo de dolor de pecho en este modelo de clasificación.
Matriz de confusión
| Clase de predicción (entrenamiento) | Clase de predicción (prueba) | ||||||
|---|---|---|---|---|---|---|---|
| Clase real | Conteo | 1 | 0 | % Correcto | 1 | 0 | % Correcto |
| 1 (Evento) | 165 | 156 | 9 | 94.55 | 147 | 18 | 89.09 |
| 0 | 138 | 13 | 125 | 90.58 | 28 | 110 | 79.71 |
| Todo | 303 | 169 | 134 | 92.74 | 175 | 128 | 84.82 |
| Estadísticas | Entrenamiento (%) | Prueba (%) |
|---|---|---|
| Tasa de positivos verdaderos (sensibilidad o potencia) | 94.55 | 89.09 |
| Tasa de positivos falsos (error tipo I) | 9.42 | 20.29 |
| Tasa de negativos falsos (error tipo II) | 5.45 | 10.91 |
| Tasa de negativos verdaderos (especificidad) | 90.58 | 79.71 |
La matriz de confusión muestra qué tan efectivo es el modelo para separar las clases correctamente. En este ejemplo, la probabilidad de que un evento sea pronosticado correctamente es 89%. La probabilidad de que un no evento sea pronosticado correctamente es 80%.
Clasificación errónea
| Entrenamiento | Prueba | ||||
|---|---|---|---|---|---|
| Clasificado erróneamente | % Error | Clasificado erróneamente | % Error | ||
| Clase real | Conteo | ||||
| 1 (Evento) | 165 | 9 | 5.45 | 18 | 10.91 |
| 0 | 138 | 13 | 9.42 | 28 | 20.29 |
| Todo | 303 | 22 | 7.26 | 46 | 15.18 |
La tasa de clasificación errónea ayuda a indicar si el modelo pronosticará con exactitud nuevas observaciones. Para la predicción de eventos, el error de clasificación errónea es aproximadamente 11%. Para la predicción de no eventos, el error de clasificación errónea es aproximadamente 20%. En general, el error de clasificación errónea para los datos de prueba es aproximadamente 15%.
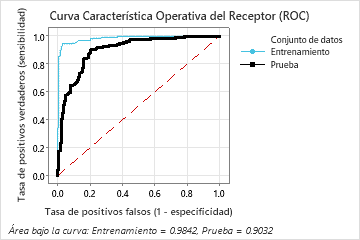
El área bajo de la curva ROC, cuando el número de árboles es 46, es aproximadamente 0.98 para los datos de entrenamiento y aproximadamente 0.90 para los datos de prueba.
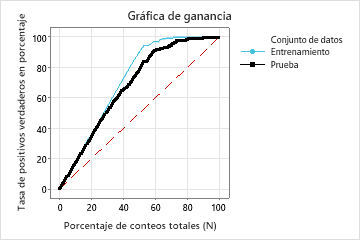
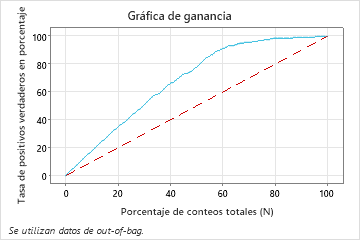
En este ejemplo, la gráfica de ganancia muestra un fuerte aumento por encima de la línea de referencia y, luego, un aplanamiento. En este caso, aproximadamente 60% de los datos representan aproximadamente 90% de los verdaderos positivos. Esta diferencia es la ganancia adicional que se obtiene al utilizar el modelo.
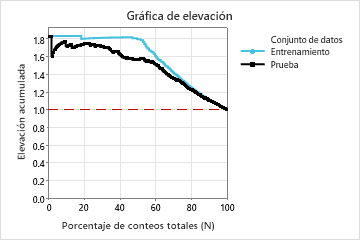
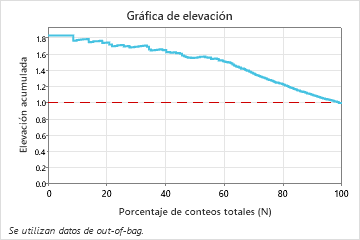
En este ejemplo, la gráfica de elevación muestra un gran incremento por encima de la línea de referencia que disminuye con mayor rapidez después de alcanzar aproximadamente 50% del recuento total.
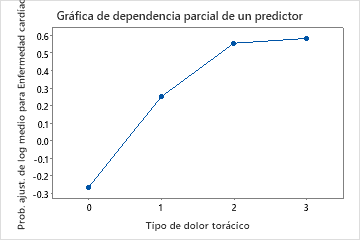
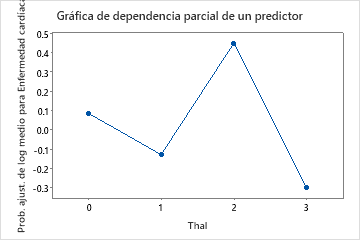
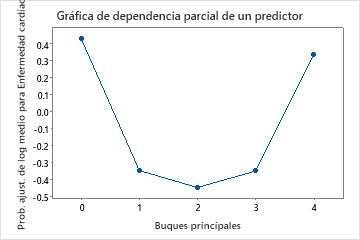
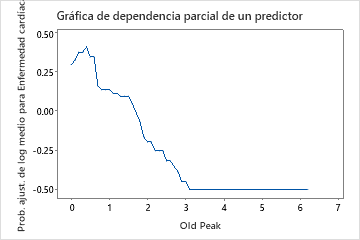
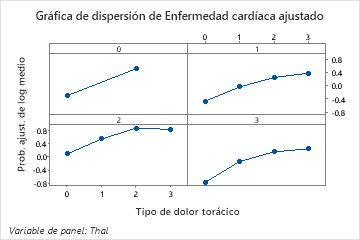
Utilice las gráficas de dependencia parcial para obtener información sobre cómo las variables o pares de variables importantes afectan los valores de respuesta ajustados. Los valores de respuesta ajustados están se encuentran en la escala semi-logarítmica. Las gráficas de dependencia parcial muestran si la relación entre la respuesta y una variable es lineal, monótona o más compleja.
Por ejemplo, en la gráfica de dependencia parcial del tipo de dolor de pecho, la probabilidad semi-logarítmica es mayor en el valor de 3. Seleccionar o producir gráficas para otras variables