Hinweis
Dieser Befehl ist mit Predictive Analytics-Modul verfügbar. Klicken Sie hier, um weitere Informationen zum Aktivieren des Moduls zu erhalten.
Ein Forscherteam erfasst und veröffentlicht detaillierte Informationen zu Faktoren, die Herzerkrankungen beeinflussen. Variablen sind Alter, Geschlecht, Cholesterinspiegel, Maximalpuls und viele weitere. Dieses Beispiel basiert auf einem öffentlichen Datensatz, der detaillierte Informationen über Herzerkrankungen liefert. Die Originaldaten stammen von der Website archive.ics.uci.edu.
Nach der ersten Untersuchung mit CART® Klassifikation zur Identifizierung der wichtigen Prädiktoren verwenden die Forscher sowohl TreeNet®-Klassifikation als auch Random Forests®-Klassifikation, um intensivere Modelle aus demselben Datensatz zu erstellen. Die Forscher vergleichen die die Tabelle mit der Zusammenfassung des Modells und das ROC-Diagramm aus den Ergebnissen, um zu bewerten, welches Modell ein besseres Prognoseergebnis liefert. Ergebnisse aus den anderen Analysen finden Sie unter Beispiel für CART® Klassifikation und Beispiel für Anpassen des Modells with TreeNet®-Klassifikation.
- Öffnen Sie die Beispieldaten Herz-Kreislauf-ErkrankungenBinar.MWX.
- Wählen Sie aus.
- Wählen Sie in der Dropdown-Liste die Option Binäre Antwort aus.
- Geben Sie im Feld Antwort die Spalte Herzkrankheiten ein.
- Wählen Sie in Antwortereignis den Wert „1“ aus, um anzugeben, dass beim Patienten eine Herzerkrankung festgestellt wurde.
- Geben Sie im Feld Stetige Prädiktoren die Spalten Alter, 'Rest Blutdruck', Cholesterin, 'Max Herzfrequenz' und 'Old Peak' ein.
- Geben Sie im Feld Kategoriale Prädiktoren die Spalten Sex, 'Brust Schmerz Typ', 'Fasten Blutzucker', 'Rest-EKG', 'Übung Angina', Steigung, Hauptblutgefäße und Thal ein.
- Klicken Sie auf OK.
Interpretieren der Ergebnisse
Für diese Analyse beträgt die Anzahl der Beobachtungen 303. Jede der 300 Bootstrap-Stichproben verwendet die 303 Beobachtungen, um einen Baum zu erstellen. Die Daten enthalten eine gute Aufteilung von Nicht-Ereignissen und Ereignissen.
Methode
| Modellvalidierung | Validierung mit Daten von außerhalb des Segments |
|---|---|
| Anzahl der Bootstrap-Stichproben | 300 |
| Stichprobenumfang | Entspricht Umfang der Trainingsdaten von 303 |
| Anzahl der für die Knotenteilung ausgewählten Prädiktoren | Quadratwurzel der Gesamtanzahl der Prädiktoren = 3 |
| Minimale interne Knotengröße | 2 |
| Verwendete Zeilen | 303 |
Informationen zur binären Antwort
| Variable | Klasse | Anzahl | % |
|---|---|---|---|
| Herzkrankheiten | 1 (Ereignis) | 139 | 45,87 |
| 0 | 164 | 54,13 | |
| Alle | 303 | 100,00 |
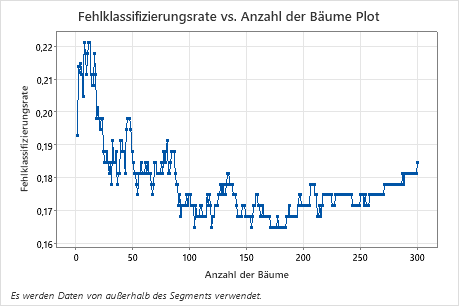
Das Diagramm der Fehlklassifizierungsrate vs. Anzahl der Bäume zeigt die gesamte Kurve über die Anzahl der aufgebauten Bäume. Die Fehlklassifizierungsrate liegt bei ca. 0,18.
Zusammenfassung des Modells
| Prädiktoren gesamt | 13 |
|---|---|
| Wichtige Prädiktoren | 13 |
| Statistiken | Außerhalb des Segments |
|---|---|
| Durchschnittliche -Log-Likelihood | 0,4004 |
| Fläche unter der ROC-Kurve | 0,9028 |
| 95%-KI | (0,8693; 0,9363) |
| Lift | 2,1079 |
| Fehlklassifizierungsrate | 0,1848 |
Zusammenfassung des Modells
| Prädiktoren gesamt | 13 |
|---|---|
| Wichtige Prädiktoren | 13 |
| Anzahl der aufgebauten Bäume | 500 |
| Optimale Anzahl von Bäumen | 351 |
| Statistiken | Trainings | Test |
|---|---|---|
| Durchschnittliche -Log-Likelihood | 0,2341 | 0,3865 |
| Fläche unter der ROC-Kurve | 0,9825 | 0,9089 |
| 95%-KI | (0,9706; 0,9945) | (0,8757; 0,9421) |
| Lift | 2,1799 | 2,1087 |
| Fehlklassifizierungsrate | 0,0759 | 0,1750 |
Die Tabelle mit der Zusammenfassung des Modells zeigt, dass die durchschnittliche negative Log-Likelihood 0,3994 beträgt. Diese Statistiken zeigen ein ähnliches Modell wie jenes, das Minitab TreeNet® beim Aufbau von 500 Bäumen erstellt. Auch die Fehlklassifizierungsraten sind ähnlich.
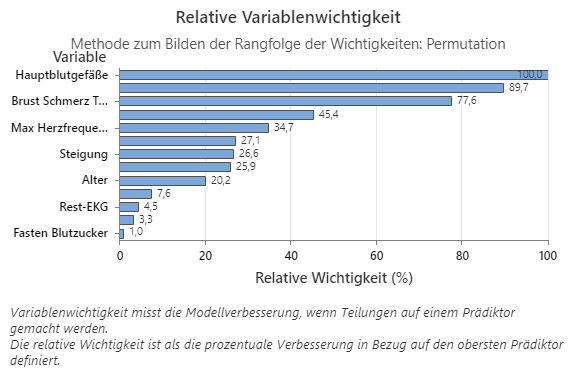
Das Diagramm „Relative Variablenwichtigkeit“ zeigt die Prädiktoren in der Reihenfolge ihrer Auswirkungen auf die Modellverbesserung, wenn Teilungen anhand eines Prädiktors über die Abfolge der Bäume hinweg vorgenommen werden. Die wichtigste Prädiktorvariable ist „Hauptgefäße“. Wenn der Beitrag der obersten Prädiktorvariablen, „Hauptgefäße“, 100 % beträgt, hat die nächstwichtige Variable, „THAL“, einen Beitrag von 89,7%. Das heißt, dass „THAL“ in diesem Klassifikationsmodell 89,7% so wichtig wie „Hauptgefäße“ ist.
Konfusionsmatrix
| Prognostizierte Klasse (außerhalb des Segments) | ||||
|---|---|---|---|---|
| Tatsächliche Klasse | ||||
| Anzahl | 1 | 0 | % Richtig | |
| 1 (Ereignis) | 139 | 109 | 30 | 78,42 |
| 0 | 164 | 26 | 138 | 84,15 |
| Alle | 303 | 135 | 168 | 81,52 |
| Statistiken | Außerhalb des Segments (%) |
|---|---|
| Richtig-Positiv-Rate (Empfindlichkeit oder Trennschärfe) | 78,42 |
| Falsch-Positiv-Rate (Fehler 1. Art) | 15,85 |
| Falsch-Negativ-Rate (Fehler 2. Art) | 21,58 |
| Richtig-Negativ-Rate (Spezifität) | 84,15 |
Die Konfusionsmatrix veranschaulicht, wie gut das Modell die Klassen korrekt trennt. In diesem Beispiel liegt die Wahrscheinlichkeit, dass ein Ereignis korrekt prognostiziert wird, bei 78,42%. Die Wahrscheinlichkeit, dass ein Nicht-Ereignis korrekt prognostiziert wird, beträgt 84,15 %.
Fehlklassifikation
| Tatsächliche Klasse | Außerhalb des Segments | ||
|---|---|---|---|
| Anzahl | Fehlklassifiziert | % Fehler | |
| 1 (Ereignis) | 139 | 30 | 21,58 |
| 0 | 164 | 26 | 15,85 |
| Alle | 303 | 56 | 18,48 |
Die Fehlklassifizierungsrate gibt an, ob das Modell neue Beobachtungen genau prognostizieren wird. Bei der Prognose von Ereignissen beträgt der Fehler bei der Fehlklassifizierung 21,58 %. Bei der Prognose von Nicht-Ereignissen beträgt der Fehler bei der Fehlklassifizierung 15,85 % und insgesamt 18,48 %.
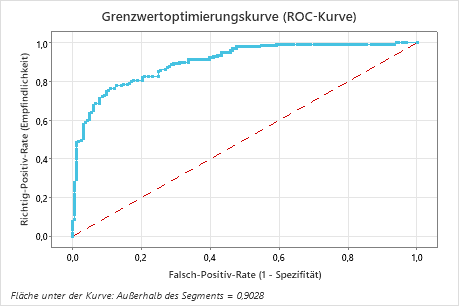
Die Fläche unterhalb der ROC-Kurve für diese Daten beträgt etwa 0,9028, was eine leichte Verbesserung gegenüber dem CART® Klassifikation-Modell zeigt. Das TreeNet®-Klassifikation-Modell hat eine Test-AUROC von 0.9089, so dass diese 2 Methoden ähnliche Ergebnisse liefern.
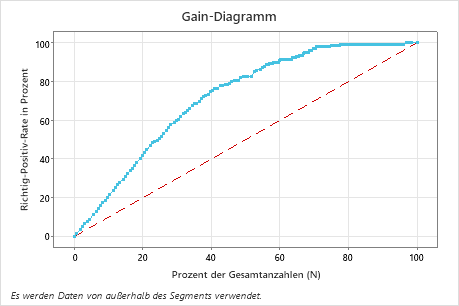
In diesem Beispiel zeigt das Gain-Diagramm einen starken Anstieg über die Referenzlinie und flacht dann ab. In diesem Fall sind rund 40 % der Daten für rund 78% der Richtig-Positiven verantwortlich. Diese Differenz entspricht dem zusätzlichen Gain, der aus der Verwendung des Modells resultiert.
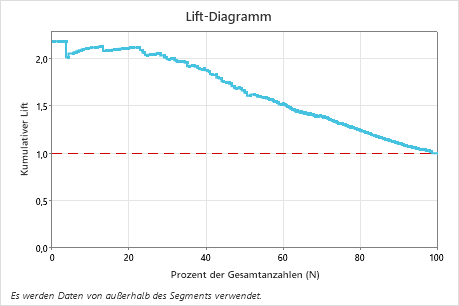
In diesem Beispiel zeigt das Lift-Diagramm einen starken Anstieg über die Referenzlinie und fällt dann ab.