关于本主题
样本统计量
公式
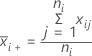
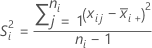
表示法
| 项 | 说明 |
|---|---|
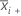 | 样本 i 的均值 |
| S2i | 样本 i 的方差 |
| Xij | 第 i 个样本的第 j 个测量值 |
| ni | 样本 i 的数量 |
使用平衡设计的 Bonett 方法检验
检验统计量的公式
当 n1 = n2 时,检验统计量为 Z2。如果原假设 ρ = ρ0 为真,则 Z2 将服从自由度为 1 的卡方分布。Z2 的计算公式如下所示:
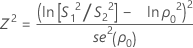
其中 se(ρ0) 是合并峰度的标准误,其计算公式如下:

其中 ri = ( ni - 3) / ni,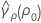 是合并峰度,其计算公式如下:
是合并峰度,其计算公式如下:
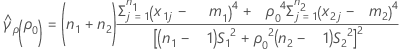
se2(ρ0) 还可以用各个样本的峰度值来表示。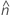 ,如下所示:
,如下所示:
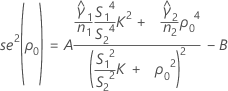
其中:
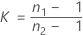

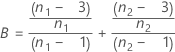
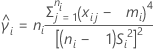
p 值的公式
假设 z2 是从数据获得的 Z2 值。在原假设(H0:ρ = ρ0)下,Z 服从标准正态分布。因此,备择假设 (H1) 的 p 值按如下公式计算。
| 假设 | P 值 |
|---|---|
| H1:ρ0 ≠ ρ0 | P = 2P(Z > |z|) |
| H1:ρ0 > ρ0 | P = P(Z > z) |
| H1:ρ0 < ρ0 | P = P(Z < z) |
表示法
| 项 | 说明 |
|---|---|
| Si | 样本 i 的标准差 |
| ρ | 总体标准差的比值 |
| ρ0 | 总体标准差的假设比值 |
| α | 检验的显著性水平 = 1 - (置信水平 / 100) |
| ni | 样本 i 中的观测值个数 |
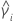 | 样本 i 的峰度值 |
| Xij | 样本 i 中的第 j 个观测值 |
| mi | 具有以下截尾比率的样本 i 的截尾均值: |
使用非平衡设计的 Bonett 方法检验
公式
当 n1 ≠ n2 时,没有检验统计量。相反,p 值是通过将置信区间过程反向来计算的。检验的 p 值的计算公式如下:
P = 2 min (αL, αU)
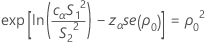
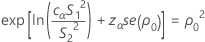
其中,cα 是下面描述的均衡器常量,se(ρ0) 是合并峰度的标准误,其计算公式如下:

其中 ri = (ni - 3) / ni,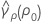 是合并峰度,其计算公式如下:
是合并峰度,其计算公式如下:
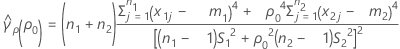
se(ρ0) 还可以用各个样本的峰度值来表示。有关更多信息,请转至“使用平衡设计的 Bonett 方法检验”。
均衡器常量
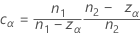
当设计达到平衡时,常量会消失,当样本数量变大时,常量的效应会变得微不足道。
查找 αL 和 αU
查找 αL 和 αU 与查找函数 L(z , n1 , n2 , S1 , S2) 和 L(z , n2 , n1 , S2 , S1) 的根等效,其中 L(z , n1 , n2 , S1 , S2) 的计算公式如下:
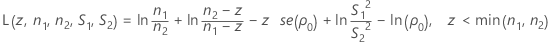
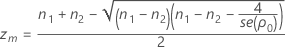
- 计算 zm 并计算 L(z, n1, n2, S1, S2)。
- 如果 L(zm)
 0,则在以下区间中查找 L(z, n1, n2, S1, S2) 的根 zL:
0,则在以下区间中查找 L(z, n1, n2, S1, S2) 的根 zL: 并计算 αL = P( Z > zL)。
并计算 αL = P( Z > zL)。 - 如果 L(zm) > 0,则函数 L(z , n1, n2, S1, S2) 无根,αL = 0。
- 如果 L(zm)
- 计算 L(0, n1, n2, S1, S2) = ln (S12 / S22)。
- 如果 L(0, n1, n2, S1, S2)
 0,则在区间 [0, n2) 中查找 L(z, n1, n2, S1, S2) 的根 z0。
0,则在区间 [0, n2) 中查找 L(z, n1, n2, S1, S2) 的根 z0。 - 如果 L(0, n1, n2, S1, S2) < 0,则在以下区间中查找根 zL:
 。
。
- 如果 L(0, n1, n2, S1, S2)
- 计算 αL = P( Z > zL)。
要计算 αU,请使用函数 L(z, n2, n1, S2, S1) 而不是函数 L(z, n1, n2, S1, S2) 应用前面的步骤。
表示法
| 项 | 说明 |
|---|---|
| Si | 样本 i 的标准差 |
| ρ | 总体标准差的比值 |
| ρ0 | 总体标准差的假设比值 |
| α | 检验的显著性水平 = 1 - (置信水平 / 100) |
| zα | 标准正态分布的 α 百分位点上限 |
| ni | 样本 i 中的观测值个数 |
| Xij | 样本 i 中的第 j 个观测值 |
| mi | 具有以下截尾比率的样本 i 的截尾均值: |
Bonett 方法的置信区间
公式
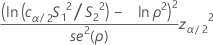
其中,cα/2 是均衡器常量(在下面描述),se(ρ) 是合并峰度的标准误(在下面描述)。通常,该方程有两个解,一个解 L < S1 / S2,另一个解 U > S1 / S2。L 是置信下限,U 是置信上限。有关更多信息,请转至 Bonett 方法(这是一本白皮书,其中包含有关 Bonett 方法的模拟和其他信息)。
方差比值的置信限值可通过对标准差比值的置信限值求平方来获得。
均衡器常量
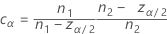
当设计达到平衡时,常量会消失,当样本数量变大时,常量的效应会变得微不足道。
合并峰度的标准误
se(ρ) 是合并峰度的标准误,其计算公式如下:
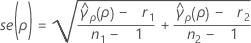
其中 ri = (ni - 3) / ni,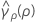 是合并峰度,其计算公式如下:
是合并峰度,其计算公式如下:
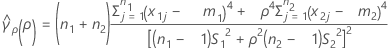
se(ρ) 还可以用各个样本的峰度值来表示。有关更多信息,请参见“使用平衡设计的 Bonett 方法检验”部分。
表示法
| 项 | 说明 |
|---|---|
| α | 检验的显著性水平 = 1 - (置信水平 / 100) |
| Si | 样本 i 的标准差 |
| ρ | 总体标准差的比值 |
| zα/2 | 标准正态分布的 α/2 百分位点上限 |
| ni | 样本 i 中的观测值个数 |
| Xij | 样本 i 中的第 j 个观测值 |
| mi | 具有以下修剪比率的样本 i 的调整比率: |
Levene 方法的检验
公式
Levene 检验适用于连续数据,但不适用于汇总数据。
为了使用 Levene 检验来检验原假设 σ1 / σ2 = ρ,Minitab 针对值 Z1j 和 ρZ2j 执行单因子方差分析(其中,j = 1, …, n1 或 n2)。
Levene 的检验统计量等于所生成的方差分析表中的 F 统计量。Levene 的检验 p 值等于此方差分析表中的 p 值。
- H. Levene (1960)。Contributions to Probability and Statistics(针对概率和统计量的贡献)。斯坦福大学出版社,CA。
- M.B. Brown 和 A.B. Forsythe (1974)。“Robust Tests for the Equality of Variance”(针对方差相等性的强大检验),Journal of the American Statistical Association(美国统计协会杂志),第 69 期,第 364 到 367 页。
自由度
在原假设下,检验统计量服从自由度为 DF1 和 DF2 的 F 分布。
DF1 = 1
DF2 = n1 + n2 – 2
表示法
| 项 | 说明 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Zij | |Xi j – η i|
| ||||||||||
| σ1 | 第一个总体的标准差 | ||||||||||
| σ2 | 第二个总体的标准差 | ||||||||||
| n1 | 第一个样本数量 | ||||||||||
| n2 | 第二个样本数量 |
Levene 方法的置信区间
公式
对于连续数据,Minitab 使用以下公式为总体标准差之间的比值 (ρ) 计算置信限值。要获得总体方差之间比值的限值,请对下面的值求平方。
-
如果
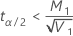 ,下限 =
,下限 = 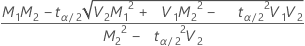
如果
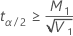 ,则下限不存在
,则下限不存在 -
如果
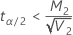 ,上限 =
,上限 = 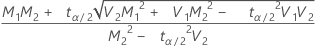
如果
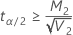 ,则上限不存在
,则上限不存在
-
如果
 ,则
,则 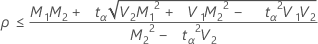
- 如果
 ,则上限不存在
,则上限不存在
-
如果
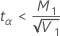 ,则
,则 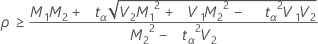
- 如果
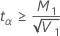 ,则下限不存在
,则下限不存在
表示法
| 项 | 说明 |
|---|---|
| t α | 自由度为 n1 + n2 – 2 的 t 分布的 α 临界值 |
| ηi | 样本 i 的中位数 |
| Zij |  其中 j = 1, 2, ... , ni, i = 1, 2,Xij 是单个观测值 其中 j = 1, 2, ... , ni, i = 1, 2,Xij 是单个观测值 |
| Mi | Zij 的均值 |
| Si2 | Zij 的样本方差 |
| vi | 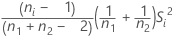 |
| ρ | σ1 / σ2 |
| n1 | 第一个样本数量 |
| n2 | 第二个样本数量 |
F 检验方法的检验
F 检验适用于正态数据。要使用 F 检验来检验原假设 (σ1 / σ2 = ρ),Minitab 使用以下公式。
检验统计量的公式
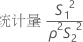
自由度的公式
在原假设下,F 统计量服从自由度为 DF1 和 DF2 的 F 分布。
DF1 = n1 – 1
DF2 = n2 – 1
p 值的公式
- 对于具有“小于”备择假设的单侧检验,p 值等于从自由度为 DF1 和 DF2 的 F 分布中获得等于或小于观测值的 F 统计量的概率。
- 对于比值小于 1 的双侧检验,p 值等于 F 曲线下方面积的两倍,小于自由度为 DF1 和 DF2 的 F 分布中的观测值。
- 对于比值大于 1 的双侧检验,p 值等于 F 曲线下方面积的两倍,大于自由度为 DF1 和 DF2 的 F 分布中的观测值。
- 对于具有“大于”备择假设的单侧检验,p 值等于从自由度为 DF1 和 DF2 的 F 分布中获得等于或大于观测值的 F 统计量的概率。
表示法
| 项 | 说明 |
|---|---|
| ρ | σ1 / σ2 |
| σ1 | 第一个总体的标准差 |
| σ2 | 第二个总体的标准差 |
| S21 | 第一个样本的方差 |
| S22 | 第二个样本的方差 |
| n1 | 第一个样本数量 |
| n2 | 第二个样本数量 |
F 检验方法的置信区间
当数据服从正态分布时,Minitab 使用以下公式为总体标准差之间的比值 (ρ) 计算置信界限。要获得总体方差之间比值的界限,请对下面的值求平方。
公式
当您指定“不等于”备择假设时,ρ 的 100(1 – α)% 置信区间的计算公式如下:
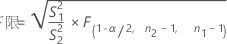
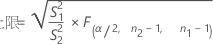
当您指定“小于”备择假设时,ρ 的 100(1 – α)% 置信上限的计算公式如下:
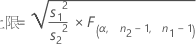
在指定“大于”备择假设时,ρ 的 100(1 – α)% 置信下限的计算公式如下:
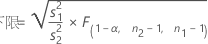
表示法
| 项 | 说明 |
|---|---|
| S1 | 第一个样本的样本标准差 |
| S2 | 第二个样本的样本标准差 |
| ρ | σ1 / σ2 |
| n1 | 第一个样本数量 |
| n2 | 第二个样本数量 |
| F(α/2, n2–1, n1–1) | 自由度为 n2–1 和 n1–1 的 F 分布中的 α/2 临界值。 |