关于本主题
原假设和备择假设
- 原假设
- 原假设声明总体参数(如均值、标准差等)等于假设值。原假设通常是基于先前分析或专业知识的初始声明。
- 备择假设
- 备择假设声明总体参数小于、大于或不同于原假设中的假设值。备择假设是可能相信为真实或有望证明为真实的内容。
解释
在输出中,原假设和备择假设可帮助您验证是否为假设比值输入了正确的值。
显著性水平
显著性水平(用 α 或 alpha 表示)是在原假设为真时否定原假设(类型 I 错误)的风险的最大可接受水平。通常,在分析数据之前选择显著性水平。在 Minitab 中,可以通过指定置信水平来选择显著性水平,因为显著性水平等于 1 减去置信水平。由于 Minitab 中的默认置信水平为 0.95,因此默认显著性水平为 0.05。
解释
通过比较显著性水平与 p 值可确定是否定原假设还是无法否定原假设 (H0)。如果 p 值小于显著性水平,则通常的解释是结果在统计意义上显著,而且可以否定 H0。
- 选择较高的显著性水平(如 0.10)可以更确定地检测到可能存在的任何差值。例如,一位质量工程师将新滚珠轴承的稳定性与当前轴承的稳定性进行比较。该工程师必须高度确信新滚珠轴承的稳定性,因为不稳定的滚珠轴承会导致灾难性后果。该工程师选择 0.10 的显著性水平,以更确定地检测到滚珠轴承稳定性方面任何可能的差异。
- 选择较低的显著性水平(如 0.01)可以更确定地仅检测到一个实际存在的差异。例如,一家制药公司的科学家必须十分确信公司的新药可以显著减轻症状的声明。该科学家选择 0.001 的显著性水平以更加确信任何显著的症状差异的确存在。
N
样本数量 (N) 是样本中的观测值总数。
标准差
标准差是离差的最常用度量,即数据从均值展开的程度。符号 σ(西格玛)通常用于表示总体的标准差,而 s 用于表示样本的标准差。对某一过程而言随机或合乎自然规律的变异通常称为噪声。对某一过程而言随机或合乎自然规律的变异通常称为噪声。
标准差与数据采用相同的单位。
解释
每个样本的标准差是对每个总体标准差的估计值。Minitab 使用标准差估计总体标准差的比值。您应该关注此比值。
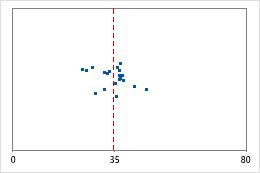
医院 1
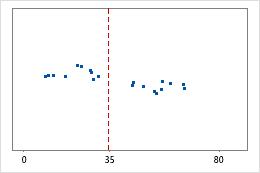
医院 2
医院出院时间
管理员对两家医院急诊部所治疗的患者的出院时间进行跟踪。尽管平均出院时间大致相同(35 分钟),但标准差显著不同。医院 1 的标准差大约为 6。平均而言,患者的出院时间大约偏离均值(虚线)6 分钟。医院 2 的标准差大约为 20。
方差
方差度量数据围绕其均值的分散程度。方差等于标准差的平方。
解释
每个样本的方差是对每个总体方差的估计值。Minitab 使用方差估计总体方差的比值。您应该关注此比值。
估计的标准差比值
标准差比值等于第一个样本的标准差除以第二个样本的标准差。
解释
样本数据标准差的估计比值是对总体标准差中比值的估计值。
由于估计的比值基于样本数据而不是整个总体,因此样本比值通常不等于总体比值。使用置信区间可以更好地估计比值。
估计的方差比值
方差比值等于第一个样本的方差除以第二个样本的方差。
解释
样本数据方差的估计比值是对总体方差中比值的估计值。
由于估计的比值基于样本数据而不是整个总体,因此样本比值通常不等于总体比值。使用置信区间可以更好地估计比值。
置信区间 (CI) 和界限
置信区间提供总体比值的可能值范围。由于样本的随机性,来自总体的两个样本不可能生成相同的置信区间。但是如果将样本重复许多次,则所获得的特定百分比的置信区间或限值会包含未知的总体比值。这些包含比值的置信区间或限值的百分比是区间的置信水平。例如,95% 置信水平表明,如果从总体中随机抽取 100 个样本,则大约 95 个样本将产生包含总体比值的区间。
上限定义可能大于总体比值的值。下限定义可能小于总体比值的值。
置信区间有助于评估结果的实际意义。使用您的专业知识可以确定置信区间是否包括对您的情形有实际意义的值。如果区间因太宽而毫无用处,请考虑增加样本数量。有关更多信息,请转到获得更加精确的置信区间的方法。
默认情况下,双方差检验将显示 Levene 方法和 Bonett 方法的结果。Bonett 方法通常比 Levene 方法更可靠。但是,对于严重偏斜和重尾的分布,Levene 方法通常比 Bonett 方法更可靠。只有当您确信数据服从正态分布时,才使用 F 检验。与正态的任何小偏差都可能会大大影响 F 检验的结果。有关更多信息,请转到对于双方差,应使用 Bonett 方法还是 Levene 方法?。
标准差比
| 估计的比值 | 使用 Bonett 的比值的 95% 置信区间 | 使用 Levene 的比值的 95% 置信区间 |
|---|---|---|
| 0.658241 | (0.372, 1.215) | (0.378, 1.296) |
在这些结果中,两家医院评分的总体标准差比值的估计值为 .658。通过使用 Bonett 方法,医院评分的总体标准差的比值介于 0.372 和 1.215 之间的可信度为 95%。
自由度
自由度 (DF) 是数据提供的信息量,您可以使用这些信息来估计未知总体参数的值并计算这些估计值的变异性。对于双方差检验,自由度由样本中的观测值个数来确定,同时还取决于 Minitab 所使用的方法。
解释
Minitab 使用自由度来确定检验统计量。自由度由样本数量确定。增加样本数量可提供有关总体的更多信息,从而增加自由度。
Bonett 方法的检验统计量
该检验统计量是 Minitab 通过将置信区间反向而计算的 Bonett 方法统计量。Bonett 方法的检验统计量对于汇总数据或非平衡数据不可用。
解释
可以通过将检验统计量与卡方分布的临界值进行比较来确定是否要否定原假设。但是,使用检验的 p 值做出相同的决定通常更实际且更方便。对于所有的大小检验来说,p 值的含义都相同,但相同的卡方统计量可能指示相反的结论,具体取决于样本数量。
- 对于双侧检验,临界值为
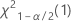 和
和 . 如果检验统计量小于第一个值或者大于第二个值,则否定原假设。如果检验统计量介于第一个值和第二个值之间,则无法否定原假设。
. 如果检验统计量小于第一个值或者大于第二个值,则否定原假设。如果检验统计量介于第一个值和第二个值之间,则无法否定原假设。 - 对于具有“小于”备择假设的单侧检验,临界值为
 . 如果检验统计量小于临界值,则否定原假设。否则,无法否定原假设。
. 如果检验统计量小于临界值,则否定原假设。否则,无法否定原假设。 - 对于“大于”单侧检验,临界值为
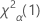 . 如果检验统计量大于临界值,则否定原假设。否则,无法否定原假设。
. 如果检验统计量大于临界值,则否定原假设。否则,无法否定原假设。
检验统计量可用于计算 p 值。
Levene 方法的检验统计量
该检验使用单因子方差分析 F 统计量,此统计量应用于观测值的绝对中位数偏差。因此,应用 Levene 方法与向观测值的绝对中位数偏差应用单因子方差分析过程等效。对于双样本问题,此方法还与向观测值的绝对中位数偏差应用双样本 t 过程等效。
解释
可以通过将检验统计量与 F 分布的临界值进行比较来确定是否要否定原假设。但是,使用检验的 p 值做出相同的决定通常更实际且更方便。
- 对于双侧检验,临界值为
 和
和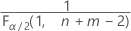 。如果检验统计量小于第一个值或者大于第二个值,则否定原假设。如果检验统计量介于第一个值和第二个值之间,则无法否定原假设。
。如果检验统计量小于第一个值或者大于第二个值,则否定原假设。如果检验统计量介于第一个值和第二个值之间,则无法否定原假设。 - 对于具有“小于”备择假设的单侧检验,临界值为
 。如果检验统计量小于临界值,则否定原假设。否则,无法否定原假设。
。如果检验统计量小于临界值,则否定原假设。否则,无法否定原假设。 - 对于“大于”单侧检验,临界值为
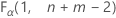 。如果检验统计量大于临界值,则否定原假设。否则,无法否定原假设。
。如果检验统计量大于临界值,则否定原假设。否则,无法否定原假设。
检验统计量可用于计算 p 值。
F 方法的检验统计量
检验统计量是 F 检验的统计量,用来度量观测方差之间的比值。
解释
可以通过将检验统计量与 F 分布的临界值进行比较来确定是否要否定原假设。但是,使用检验的 p 值做出相同的决定通常更实际且更方便。
- 对于双侧检验,临界值为
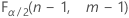 和
和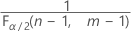 . 如果检验统计量小于第一个值或者大于第二个值,则否定原假设。如果检验统计量介于第一个值和第二个值之间,则无法否定原假设。
. 如果检验统计量小于第一个值或者大于第二个值,则否定原假设。如果检验统计量介于第一个值和第二个值之间,则无法否定原假设。 - 对于具有“小于”备择假设的单侧检验,临界值为
 . 如果检验统计量小于临界值,则否定原假设。否则,无法否定原假设。
. 如果检验统计量小于临界值,则否定原假设。否则,无法否定原假设。 - 对于“大于”单侧检验,临界值为
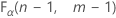 . 如果检验统计量大于临界值,则否定原假设。否则,无法否定原假设。
. 如果检验统计量大于临界值,则否定原假设。否则,无法否定原假设。
检验统计量可用于计算 p 值。
P 值
P 值是一个概率,用来度量否定原假设的证据。P 值越小,否定原假设的证据越充分。
解释
使用 p 值可确定总体标准差或方差的差值在统计意义上是否显著。
- P 值 ≤ α:标准差或方差的比值在统计意义上显著(否定 H0)
- 如果 p 值小于或等于显著性水平,则决策为否定原假设。您可以得出总体标准差或方差的比值不等于假设比值的结论。如果您没有指定假设比值,Minitab 将检验标准差或方差之间是否不存在差值(假设比值 = 1)。请使用您的专业知识确定差值在实际意义上是否显著。有关更多信息,请转到统计显著性和实际显著性。
- P 值 > α:标准差或方差的比值在统计意义上不显著(无法否定 H0)
- 如果 p 值大于显著性水平,则决策为无法否定原假设。您没有足够的证据得出总体标准差或方差的比值在统计意义上显著的结论。您应该确保检验具有足够的功效来检测到在实际意义上显著的差值。有关更多信息,请转到双方差的功效和样本数量。
- Bonett 检验对于任何连续分布都是准确的,并且不要求数据为正态数据。Bonett 检验通常比 Levene 检验更可靠。
- Levene 检验对于任何连续分布也是准确的。对于极其偏斜和重尾的分布,Levene 方法可能比 Bonett 方法更可靠。
- F 检验仅对于正态分布数据是准确的。只要稍微偏离正态性,都可能会导致 F 检验不准确,即便使用大样本也是如此。但是,如果数据很好地遵循了正态分布,则 F 检验通常比 Bonett 方法或 Levene 方法的功效更好。
有关更多信息,请转到对于双方差,应使用 Bonett 方法还是 Levene 方法?。
汇总图
摘要图显示比率的置信区间,以及每个样本的标准差或方差的置信区间。摘要图还显示样本数据的箱线图,以及假设检验的 p 值。
置信区间
置信区间提供总体比值的可能值范围。由于样本的随机性,来自总体的两个样本不可能生成相同的置信区间。但是如果将样本重复许多次,则所获得的特定百分比的置信区间或限值会包含未知的总体比值。这些包含比值的置信区间或限值的百分比是区间的置信水平。例如,95% 置信水平表明,如果从总体中随机抽取 100 个样本,则大约 95 个样本将产生包含总体比值的区间。
上限定义可能大于总体比值的值。下限定义可能小于总体比值的值。
解释
置信区间有助于评估结果的实际意义。使用您的专业知识可以确定置信区间是否包括对您的情形有实际意义的值。如果区间因太宽而毫无用处,请考虑增加样本数量。有关更多信息,请转到获得更加精确的置信区间的方法。
默认情况下,双方差检验将显示 Levene 方法和 Bonett 方法的结果。Bonett 方法通常比 Levene 方法更可靠。但是,对于严重偏斜和重尾的分布,Levene 方法通常比 Bonett 方法更可靠。只有当您确信数据服从正态分布时,才使用 F 检验。与正态的任何小偏差都可能会大大影响 F 检验的结果。有关更多信息,请转到对于双方差,应使用 Bonett 方法还是 Levene 方法?。
箱线图
箱线图提供了每个样本分布的图形汇总。通过箱线图,可以方便地比较样本的形状、集中趋势和变异性。
解释
可使用箱线图检查数据的散布,以及确定任何可能的异常值。当样本数量大于 20 时,箱线图具有最佳状态。
- 偏斜数据
-
检查数据的散布以确定数据看上去是否偏斜。当数据偏斜时,大多数数据位于图形的高或低侧。通常情况下,在直方图或箱线图中最易于检测偏度。
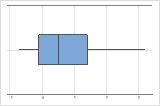
右偏斜
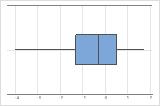
左偏斜
带右偏斜数据的箱线图显示等待时间。大部分等待时间相对较短,只有少数等待时间很长。带左偏斜数据的箱线图显示故障时间数据。有几个项目立即失败,还有其他许多项目在随后失败。
如果样本小(小于 20 个值),则严重偏斜的数据可影响 p 值的有效性。如果您的数据严重偏斜,并且样本小,请考虑增大样本数量。
- 异常值
-
异常值,是远离其他数据值的数据值,可以显著影响您的分析结果。通常情况下,在箱线图上最容易识别异常值。
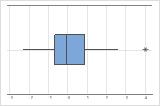
在箱线图上,星号 (*) 表示异常值。
尝试确定导致任何异常值的原因。更正任何数据输入错误或测量误差。考虑删除异常、单次事件(也称为特殊原因)的数据值。然后,重新执行分析。有关更多信息,请转到 标识异常值。
单值图
单值图显示每个样本中的单个值。通过单值图,可以很容易地比较样本。每个圆形表示一个观测值。当您具有的观测值相对较少,以及需要评估每个观测值的效果时,单值图尤其有用。
解释
可使用单值图检查数据的散布,以及确定任何可能的异常值。 当样本数量小于 50 时,单值图具有最佳状态。
- 偏斜数据
-
检查数据的散布以确定数据看上去是否偏斜。当数据偏斜时,大多数数据位于图形的高或低侧。通常情况下,在直方图或箱线图中最易于检测偏度。
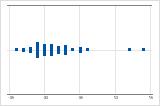
右偏斜
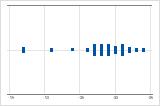
左偏斜
带右偏斜数据的单值图显示等待时间。大部分等待时间相对较短,只有少数等待时间很长。带左偏斜数据的单值图显示故障时间数据。有几个项目立即失败,还有其他许多项目在随后失败。
如果样本小(小于 20 个值),则严重偏斜的数据可影响 p 值的有效性。如果您的数据严重偏斜,并且样本小,请考虑增大样本数量。
- 异常值
-
异常值,是远离其他数据值的数据值,可以显著影响您的分析结果。通常情况下,在箱线图上最容易识别异常值。
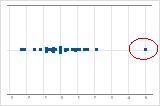
在单值图上,异常低或高的数据值表示可能的异常值。
尝试确定导致任何异常值的原因。更正任何数据输入错误或测量误差。考虑删除异常、单次事件(也称为特殊原因)的数据值。然后,重新执行分析。有关更多信息,请转到 标识异常值。
直方图
直方图将样本值分成许多区间,并使用条形表示每个区间中的数据值的频率。
解释
可使用直方图评估数据的形状和散布。 当样本数量大于 20 时,直方图具有最佳状态。
- 偏斜数据
-
检查数据的散布以确定数据看上去是否偏斜。当数据偏斜时,大多数数据位于图形的高或低侧。通常情况下,在直方图或箱线图中最易于检测偏度。
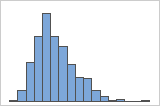
右偏斜
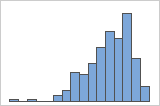
左偏斜
带右偏斜数据的直方图显示等待时间。大部分等待时间相对较短,只有少数等待时间很长。带左偏斜数据的条形图显示故障时间数据。有几个项目立即失败,还有其他许多项目在随后失败。
如果样本小(小于 20 个值),则严重偏斜的数据可影响 p 值的有效性。如果您的数据严重偏斜,并且样本小,请考虑增大样本数量。
- 异常值
-
异常值,是远离其他数据值的数据值,可以显著影响您的分析结果。通常情况下,在箱线图上最容易识别异常值。
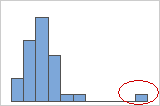
在直方图上,图形任一端上的孤立条形标识可能的异常值。
尝试确定导致任何异常值的原因。更正任何数据输入错误或测量误差。考虑删除异常、单次事件(也称为特殊原因)的数据值。然后,重新执行分析。有关更多信息,请转到 标识异常值。