Notation
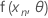
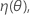
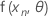 .
.
The Jacobian of η is a N X P matrix with elements that are equal to the partial derivatives of the expectation function with respect to the parameters:

Then a linear approximation for η is:
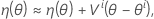
Let θ* denote the least-squares estimate.
Gauss-Newton
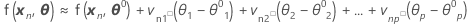
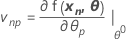
Including all N cases


where

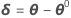
Minitab calculates the Gauss increment δ0to minimize the approximate residual sum of squares 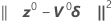 , using:
, using:


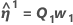
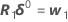 .
.
The point

should now be closer to y than η(θ0), and Minitab uses the value θ1 = θ0 + δ0 to perform another iteration by calculating new residuals z1 = y - η(θ1), a new derivative matrix V1, and a new increment. Minitab repeats this process until convergence, which is when the increment is so small that there is no useful change in the elements of the parameter vector.
Sometimes the Gauss-Newton increment produces an increase in the sum of squares. When this occurs, the linear approximation is still a close approximation to the actual surface for a sufficiently small region around η(θ0). To reduce the sum of squares, Minitab introduces a step factor λ, and calculates:
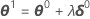
- Bates and Watts (1988). Nonlinear Regression Analysis and Its Applications. John Wiley & Sons, Inc.
Levenberg-Marquardt
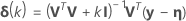
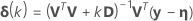
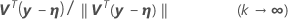 .1
.1
- Bates and Watts (1988). Nonlinear Regression Analysis and Its Applications. John Wiley & Sons, Inc.
Relative offset convergence criterion
1. Bates and Watts (1988). Nonlinear Regression Analysis and Its Applications. John Wiley & Sons, Inc.