In This Topic
Step 1: Determine whether the association between the response and the term is statistically significant
- P-value ≤ α: The association is statistically significant
- If the p-value is less than or equal to the significance level, you can conclude that there is a statistically significant association between the response variable and the term.
- P-value > α: The association is not statistically significant
- If the p-value is greater than the significance level, you cannot conclude that there is a statistically significant association between the response variable and the term. You may want to refit the model without the term.
- If a fixed factor is significant, you can conclude that not all the level means are equal.
- If a random factor is significant, you can conclude that the factor contributes to the amount of variation in the response.
- If an interaction term is significant, the relationship between a factor and the response depends on the other factors in the term. In this case, you should not interpret the main effects without considering the interaction effect.
Use the Means table to understand the statistically significant differences between the factor levels in your data. The mean of each group provides an estimate of each population mean. Look for differences between group means for terms that are statistically significant.
For main effects, the table displays the groups within each factor and their means. For interaction effects, the table displays all possible combinations of the groups. If an interaction term is statistically significant, do not interpret the main effects without considering the interaction effects.
Factor Information
| Factor | Type | Levels | Values |
|---|---|---|---|
| Time | Fixed | 2 | 1, 2 |
| Operator | Random | 3 | 1, 2, 3 |
| Setting | Fixed | 3 | 35, 44, 52 |
Analysis of Variance for Thickness
| Source | DF | SS | MS | F | P | |
|---|---|---|---|---|---|---|
| Time | 1 | 9.0 | 9.00 | 0.29 | 0.644 | |
| Operator | 2 | 1120.9 | 560.44 | 4.28 | 0.081 | x |
| Setting | 2 | 15676.4 | 7838.19 | 73.18 | 0.001 | |
| Time*Operator | 2 | 62.0 | 31.00 | 4.34 | 0.026 | |
| Time*Setting | 2 | 114.5 | 57.25 | 8.02 | 0.002 | |
| Operator*Setting | 4 | 428.4 | 107.11 | 15.01 | 0.000 | |
| Error | 22 | 157.0 | 7.14 | |||
| Total | 35 | 17568.2 |
Model Summary
| S | R-sq | R-sq(adj) |
|---|---|---|
| 2.67140 | 99.11% | 98.58% |
Error Terms for Tests
| Source | Variance component | Error term | Expected Mean Square for Each Term (using unrestricted model) | |
|---|---|---|---|---|
| 1 | Time | 4 | (7) + 6 (4) + Q[1, 5] | |
| 2 | Operator | 35.789 | * | (7) + 4 (6) + 6 (4) + 12 (2) |
| 3 | Setting | 6 | (7) + 4 (6) + Q[3, 5] | |
| 4 | Time*Operator | 3.977 | 7 | (7) + 6 (4) |
| 5 | Time*Setting | 7 | (7) + Q[5] | |
| 6 | Operator*Setting | 24.994 | 7 | (7) + 4 (6) |
| 7 | Error | 7.136 | (7) |
Error Terms for Synthesized Tests
| Source | Error DF | Error MS | Synthesis of Error MS | |
|---|---|---|---|---|
| 2 | Operator | 5.12 | 130.9747 | (4) + (6) - (7) |
Means
| Time | N | Thickness |
|---|---|---|
| 1 | 18 | 67.7222 |
| 2 | 18 | 68.7222 |
| Setting | N | Thickness |
|---|---|---|
| 35 | 12 | 40.5833 |
| 44 | 12 | 73.0833 |
| 52 | 12 | 91.0000 |
| Time*Setting | N | Thickness |
|---|---|---|
| 1 35 | 6 | 40.6667 |
| 1 44 | 6 | 70.1667 |
| 1 52 | 6 | 92.3333 |
| 2 35 | 6 | 40.5000 |
| 2 44 | 6 | 76.0000 |
| 2 52 | 6 | 89.6667 |
Key Results: P-Value, Means table
Setting is a fixed factor and this main effect is significant. This result indicates that the mean coating thickness is not equal for all machine settings.
Time*Setting is an interaction effect that involves two fixed factors. This interaction effect is significant, which indicates that the relationship between each factor and the response depends on the level of the other factor. In this case, you should not interpret the main effects without considering the interaction effect.
In these results, the Means table shows how the mean thickness varies by time, machine setting, and each combination of time and machine setting. Setting is statistically significant and the means differ between the machine settings. However, because the Time*Setting interaction term is also statistically significant, do not interpret the main effects without considering the interaction effects. For example, the table for the interaction term shows that with a setting of 44, time 2 is associated with a thicker coating. However, with a setting of 52, time 1 is associated with a thicker coating.
Operator is a random factor and all interactions that include a random factor are considered to be random. If a random factor is significant, you can conclude that the factor contributes to the amount of variation in the response. Operator is not significant at the 0.05 level, but the interaction effects that include operator are significant. These interaction effects indicate that the amount of variation that operator contributes to the response depends on the value of both time and machine setting.
Step 2: Determine how well the model fits your data
To determine how well the model fits your data, examine the goodness-of-fit statistics in the Model Summary table.
- S
-
Use S to assess how well the model describes the response. Use S instead of the R2 statistics to compare the fit of models that have no constant.
S is measured in the units of the response variable and represents how far the data values fall from the fitted values. The lower the value of S, the better the model describes the response. However, a low S value by itself does not indicate that the model meets the model assumptions. You should check the residual plots to verify the assumptions.
- R-sq
-
The higher the R2 value, the better the model fits your data. R2 is always between 0% and 100%.
R2 always increases when you add additional predictors to a model. For example, the best five-predictor model will always have an R2 that is at least as high as the best four-predictor model. Therefore, R2 is most useful when you compare models of the same size.
- R-sq (adj)
-
Use adjusted R2 when you want to compare models that have different numbers of predictors. R2 always increases when you add a predictor to the model, even when there is no real improvement to the model. The adjusted R2 value incorporates the number of predictors in the model to help you choose the correct model.
-
Small samples do not provide a precise estimate of the strength of the relationship between the response and predictors. For example, if you need R2 to be more precise, you should use a larger sample (typically, 40 or more).
-
Goodness-of-fit statistics are just one measure of how well the model fits the data. Even when a model has a desirable value, you should check the residual plots to verify that the model meets the model assumptions.
Model Summary
| S | R-sq | R-sq(adj) |
|---|---|---|
| 2.67140 | 99.11% | 98.58% |
Key Results: S, R-sq, R-sq (adj)
In these results, the model explains 99.11% of the variation in the coating thickness. For these data, the R2 value indicates the model provides a good fit to the data. If additional models are fit with different predictors, use the adjusted R2 values to compare how well the models fit the data.
Step 3: Determine whether your model meets the assumptions of the analysis
Use the residual plots to help you determine whether the model is adequate and meets the assumptions of the analysis. If the assumptions are not met, the model may not fit the data well and you should use caution when you interpret the results.
For more information on how to handle patterns in the residual plots, go to Residual plots for Fit General Linear Model and click the name of the residual plot in the list at the top of the page.
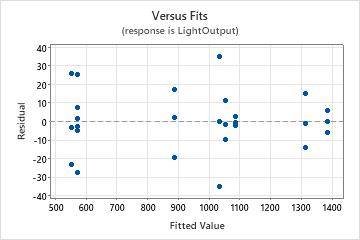
Residuals versus fits plot
Use the residuals versus fits plot to verify the assumption that the residuals are randomly distributed and have constant variance. Ideally, the points should fall randomly on both sides of 0, with no recognizable patterns in the points.
| Pattern | What the pattern may indicate |
|---|---|
| Fanning or uneven spreading of residuals across fitted values | Nonconstant variance |
| Curvilinear | A missing higher-order term |
| A point that is far away from zero | An outlier |
| A point that is far away from the other points in the x-direction | An influential point |
Residuals versus order plot
Trend
Shift
Cycle
In this residuals versus order plot, the residuals appear to fall randomly around the centerline.
There is no evidence that the residuals are not independent. 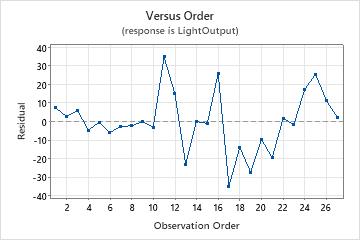
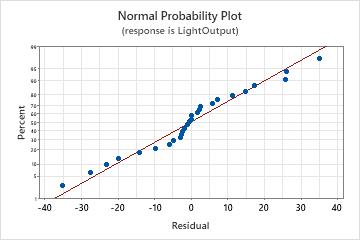
Normal probability plot
Use the normal probability plot of the residuals to verify the assumption that the residuals are normally distributed. The normal probability plot of the residuals should approximately follow a straight line.
| Pattern | What the pattern may indicate |
|---|---|
| Not a straight line | Nonnormality |
| A point that is far away from the line | An outlier |
| Changing slope | An unidentified variable |