Neste tópico
Probabilidade observada
A probabilidade observada é o número de eventos dividido pelo número de ensaios. Por exemplo, quando o número de eventos é 30 e o número de ensaios é 495, a probabilidade observada é 0,06061.
Ajuste
O valor ajustado também é chamado probabilidade do evento ou probabilidade predita. A probabilidade do evento é a chance de que o evento experimental especificado ocorra. A probabilidade do evento estima a verossimilhança de um evento ocorrer, como tirar um ás de um baralho de cartas ou de fabricar uma peça de não conformidade. A probabilidade de um evento varia de 0 (impossível) até 1 (certa).
Interpretação
A resposta experimental tem apenas dois valores possíveis, como a presença ou ausência de uma doença em particular. A probabilidade do evento é a verossimilhança de que a resposta para um dado fator ou padrão de covariável ocorra (por exemplo, a verossimilhança de que uma mulher acima de 50 irá desenvolver diabetes tipo 2).
Cada execução de um experimento é chamada ensaio. Por exemplo, se você joga uma moeda para o ar 10 vezes e registra o número de caras, você executa 10 ensaios do experimento. Se os ensaios forem independentes e igualmente prováveis, você pode estimar a probabilidade do evento dividindo o número de eventos pelo número total de ensaios. Por exemplo, se você obtiver 6 caras em 10 lançamentos da moeda, a probabilidade estimada do evento (cara) é:
Número de eventos / número de ensaios = 6 / 10 = = 0,6
EP Fit
O erro padrão do ajuste (EP fit) estima a variação no evento de probabilidade para as configurações de variável especificadas. O cálculo do intervalo de confiança para o evento de probabilidade usa o erro padrão do ajuste. Os erros padrão são sempre não negativos.
Interpretação
Use o erro padrão do ajuste para medir a exatidão da estimativa do evento de probabilidade. Quanto menor o erro padrão, mais precisa é a resposta média predita.
Por exemplo, um pesquisador estuda os fatores que afetam a inclusão em um estudo médico. Para um conjunto de fatores, a probabilidade que um paciente se qualifique para ser incluído em um estudo de um novo tratamento é 0,63, com um erro padrão de 0,05. Para um segundo conjunto de configurações de fatores, a probabilidade é a mesma, mas o erro padrão do ajuste é 0,03. O analista pode ter mais confiança que o evento de probabilidade para o segundo conjunto é próximo de 0,63.
Intervalo de confiança para ajuste (IC de 95%)
Esses intervalos de confiança (IC) são intervalos de valores que provavelmente contêm a probabilidade de evento para a população que tem os valores observados das variáveis preditoras que estão no modelo.
Como as amostras são aleatórias, é improvável que duas amostras de uma população produzam intervalos de confiança idênticos. Mas, se você extrair amostras várias vezes, uma determinada porcentagem dos intervalos de confiança resultantes conterá o parâmetro populacional desconhecido. A porcentagem destes intervalos de confiança que contém o parâmetro é o nível de confiança do intervalo.
- Estimativa de ponto
- A estimativa de ponto é a estimativa do parâmetro que é calculada a partir dos dados da amostra.
- Margem de erro
- A margem de erro define a largura do intervalo de confiança e é afetada pela faixa de probabilidades dos eventos, o tamanho da amostra e o nível de confiança.
Interpretação
Use o intervalo de confiança para avaliar a estimativa do valor ajustado para os valores observados das variáveis.
Por exemplo, com um nível de confiança de 95%, você pode ter 95% de confiança de que o intervalo de confiança contém a probabilidade de evento para os valores especificados das variáveis no modelo. O intervalo de confiança ajuda a avaliar a significância prática de seus resultados. Use seu conhecimento especializado para determinar se o intervalo de confiança inclui valores que tenham significância prática para a sua situação. Se o intervalo for muito amplo para ser útil, pense em aumentar o tamanho da amostra.
Resíd.
Um resíduo é uma medida de quão bem a observação é predita pelo modelo. Por padrão, o Minitab calcula os resíduos desvio. Observações que são mal ajustadas pelo modelo têm desvio alto e resíduos de Pearson. O Minitab calcula os resíduos para cada padrão de fator/covariável distinto.
A interpretação do resíduo é igual a quando você usa resíduos de deviance ou resíduos de Pearson. Quando o modelo utiliza a função de ligação logito, a distribuição dos resíduos de deviance é mais próxima da distribuição dos resíduos a partir de um modelo de regressão de mínimos quadrados. Os resíduos de deviance e os resíduos de Pearson se tornam mais semelhantes, pois o número de ensaios para cada combinação de configuração de preditor aumenta.
Interpretação
Represente graficamente os resíduos para determinar se seu modelo é adequado e se atende as suposições da regressão. O exame dos resíduos pode fornecer informações úteis sobre quão bem o modelo se ajusta aos dados. Em geral, os resíduos devem ser distribuídos aleatoriamente, sem padrões óbvios e nenhum valor incomum. Se o Minitab determina que os dados incluem observações incomuns, ele identifica as observações na tabela Ajustes e Diagnósticos para Observações Incomuns na saída. Para obter mais informações sobre valores incomuns, acesse Observações atípicas.
Resíd. pdr.
O resíduo padronizado é igual ao valor de um resíduo, (ei), dividido por uma estimativa de seu desvio padrão.
Interpretação
Use os resíduos padronizados para ajudar a detectar outliers. Resíduos padronizados maiores do que 2 e e menores do que -2 normalmente são considerados grandes. A tabela Ajustes e Diagnósticos para Observações Incomuns identifica essas observações com um 'R'. Quando a análise indica que há muitas observações incomuns, o modelo geralmente apresenta uma falta de ajuste significativa. Ou seja, o modelo não descreve adequadamente a relação entre os fatores e a variável de resposta. Para obter mais informações, vá para Observações atípicas.
Os resíduos padronizados são úteis porque resíduos brutos podem não ser bons indicadores de outliers. A variância de cada resíduo bruto pode diferir pelos valores-x associados a ela. Esta escala desigual torna difícil avaliar os tamanhos dos resíduos brutos. A padronização dos resíduos soluciona esse problema convertendo as diferentes variâncias a uma escala comum.
A interpretação do resíduo é igual a quando você usa resíduos de deviance ou resíduos de Pearson. Quando o modelo utiliza a função de ligação logito, a distribuição dos resíduos de deviance é mais próxima da distribuição dos resíduos a partir de um modelo de regressão de mínimos quadrados. Os resíduos de deviance e os resíduos de Pearson se tornam mais semelhantes, pois o número de ensaios para cada combinação de configuração de preditor aumenta.
Excluir resíduos
Cada resíduo estudentizado excluído é calculado com uma fórmula que é equivalente a remover sistematicamente cada observação do conjunto de dados, estimando cada equação de regressão e determinando quão bem o modelo prediz a observação removida. Cada resíduo estudentizado excluído também é padronizado dividindo-se o resíduo excluído da observação por uma estimativa de seu desvio padrão. A observação é omitida para determinar como o modelo se comporta sem essa observação. Quando uma observação possui um resíduo estudentizado deletado grande (se seu valor absoluto é maior que 2), ela pode ser um outlier nos dados.
Interpretação
Use os resíduos estudentizados excluídos para detectar outliers. Cada observação é omitida para determinar se o modelo prevê bem a resposta quando ele não está incluído no processo de ajuste do modelo. Os resíduos estudentizados excluídos maiores do que 2 ou menores do que a -2 são geralmente considerados grandes. As observações que o Minitab rotula não seguem bem a equação de regressão proposta. No entanto, espera-se que você tenha algumas observações incomuns. Por exemplo, com base nos critérios de grandes resíduos, espera-se que aproximadamente 5% das observações sejam sinalizadas como tendo um resíduo grande. Se a análise revela muitas observações incomuns, o modelo provavelmente não descreve adequadamente a relação entre os preditores e a variável de resposta. Para obter mais informações, vá para Observações atípicas.
Os resíduos padronizados e excluídos podem ser mais úteis do que resíduos brutos na identificação de outliers. Eles ajustam para possíveis diferenças na variância dos resíduos brutos devido a diferentes valores dos preditores ou fatores.
Hi (leverage)
Hi, também conhecido como leverage, mede a distância entre o valor-x de uma observação e a média dos valores de x para todas as observações em um conjunto de dados.
Interpretação
Os valores de Hi ficam entre 0 e 1. O Minitab identifica as observações com valores de leverage maiores do que 3p/n or 0,99, o que for menor, com um X na tabela Ajustes e Diagnósticos para Observações Incomuns . Em 3p/n, p é o número de coeficientes do modelo e o símbolo n representa o número de observações. As observações que os Minitab rotula com um 'X' podem ser influentes.
As observações influentes têm um efeito desproporcional sobre o modelo e podem produzir resultados enganosos. Por exemplo, a inclusão ou exclusão de um ponto influente pode mudar se um coeficiente for estatisticamente significativo ou não. As observações influentes podem ser pontos de leverage, outliers ou ambos.
Se você vir uma observação influente, determine se ela é um erro de entrada de dados ou de medição. Se a observação não não for nem um erro de entrada de dados nem um erro de medição, determine o quão influente uma observação é. Em primeiro lugar, ajustar o modelo com e sem a observação. Em seguida, compare os coeficientes, valores-p, R2, e outras informações do modelo. Se o modelo mudar significativamente quando você remover a observação influente, examine o modelo ainda mais para determinar se você especificou incorretamente o modelo. Talvez seja necessário reunir mais dados para resolver o problema.
Distância de Cook (D)
A distância de Cook (D) mede o efeito que tem uma observação sobre o conjunto de coeficientes em um modelo linear. A distância de Cook considera o valor de leverage e o resíduo padronizado de cada observação para determinar o efeito da observação.
Interpretação
As observações com um D alto podem ser consideradas influentes. Um critério habitualmente utilizado para um valor de D alto é quando D é maior do que a mediana da distribuição de F: F (0,5, p, n-p), onde p é o número de termos de modelos, incluindo a constante, e n é o número de observações. Outra maneira de examinar os valores de D é compará-los uns com os outros usando um gráfico, como um gráfico de valores individuais. As observações com valores de D alto em relação aos outros podem ser influentes.
As observações influentes têm um efeito desproporcional sobre o modelo e podem produzir resultados enganosos. Por exemplo, a inclusão ou exclusão de um ponto influente pode mudar se um coeficiente for estatisticamente significativo ou não. As observações influentes podem ser pontos de leverage, outliers ou ambos.
Se você vir uma observação influente, determine se ela é um erro de entrada de dados ou de medição. Se a observação não não for nem um erro de entrada de dados nem um erro de medição, determine o quão influente uma observação é. Em primeiro lugar, ajustar o modelo com e sem a observação. Em seguida, compare os coeficientes, valores-p, R2, e outras informações do modelo. Se o modelo mudar significativamente quando você remover a observação influente, examine o modelo ainda mais para determinar se você especificou incorretamente o modelo. Talvez seja necessário reunir mais dados para resolver o problema.
DFITS
DFITS mede o efeito que cada observação tem sobre os valores ajustados em um modelo linear. DFITS representa aproximadamente o número de desvios padrão que o valor ajustado muda quando cada observação é removida do conjunto de dados e o modelo é reajustado.
Interpretação
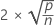
| Termo | Descrição |
|---|---|
| p | o número de termos no modelo |
| n | o número de observações |
Se você vir uma observação influente, determine se ela é um erro de entrada de dados ou de medição. Se a observação não não for nem um erro de entrada de dados nem um erro de medição, determine o quão influente uma observação é. Em primeiro lugar, ajustar o modelo com e sem a observação. Em seguida, compare os coeficientes, valores-p, R2, e outras informações do modelo. Se o modelo mudar significativamente quando você remover a observação influente, examine o modelo ainda mais para determinar se você especificou incorretamente o modelo. Talvez seja necessário reunir mais dados para resolver o problema.