참고
이 명령은 에서 사용할 수 있습니다예측 분석 모듈. 모듈을 활성화하는 방법에 대한 자세한 내용은 여기를 클릭하십시오.
이 항목의 내용
최상의 모델 유형 검색
의료 시스템 연구원은 지역 의료 클리닉에서 데이터를 수집합니다. 특히 연구팀은 아픈 환자에 대한 의사의 초기 검사 데이터에 관심이 있습니다. 초기 검사가 끝나면 의사는 각 환자에게 질병의 중증도에 대한 점수를 부여합니다. 연구원들은 의사가 검사하기 전에 가장 아픈 환자의 우선 순위를 정하는 데 도움이되는 간단한 설문지를 개발하고자합니다. 팀은 주제 전문가와의 상담과 데이터의 초기 탐색을 통해 심각도 점수를 예측하기 위해 8개의 변수를 선택합니다. 연구원들은 모델을 더 구체화하기 전에 심각도 점수를 예측하는 데 가장 적합한 모델 유형을 결정하려고 합니다.
연구원들은 다중 회귀, TreeNet®, Random Forests® CART® 및 MARS®의 5 가지 유형의 모델의 예측 성능을 비교하는 데 사용합니다 최고의 모형 검색(계량형 반응) . 팀은 예측 성능이 가장 좋은 모델 유형을 추가로 탐색할 계획입니다.
- 표본 데이터 질병.MWX를 엽니다.
- 을 선택합니다.
- 반응에 '질병 심각도 점수'을 입력합니다.
- 계량형 예측 변수에 '지금 증상의 수'을 입력합니다.
- 에 범주형 예측 변수'가래의 높은 생산'-'정상적인 활동에 대한 제한’를 입력합니다.
- 확인을 클릭합니다.
결과 해석
모델 선택 테이블은 모델 유형의 성능을 비교합니다. 다중 회귀 모델의 최대값은R2입니다. 다음 결과는 최상의 다중 회귀 모델에 대한 것입니다.
반응과 모형의 각 항 간의 연관성이 통계적으로 유의한지 여부를 확인하려면 항에 대한 p-값을 유의 수준과 비교하여 귀무 가설을 평가합니다. 귀무 가설은 항과 반응 간에 연관성이 없다는 것입니다. 일반적으로 0.05의 유의 수준(α 또는 알파로 표시됨)이 적절합니다. 0.05의 유의 수준은 실제로 연관성이 없는데 연관성이 존재한다는 결론을 내릴 위험이 5%라는 것을 나타냅니다. 이 결과에서 두 교호작용 항의 p-값이 0.05보다 큽니다. 심한 호흡 곤란*심한 두통 및 심한 두통*심한 수면 장애. 연구원이 다른 다중 회귀 모델을 탐색할 때 모델 성능 메트릭과 잔차 플롯을 사용하여 이러한 용어를 모델에 포함할 때의 효과를 탐색합니다.
모형 요약표는 훈련 R2와 검정R2 가 모두 약 91%임을 보여줍니다. 데이터 값이 적합치에서 얼마나 떨어져 있는지를 나타내는 검정 평균 제곱근 오차(RMSE)는 약 4입니다. RMSE는 질병 점수의 척도가 작기 때문에 연구자들은 적은 수의 질문이 환자의 우선 순위를 정하는 데 도움이되는 충분한 정보라고 낙관합니다.
비정상적인 정보에 대한 적합치 및 진단 표는 제안된 회귀 방정식을 잘 따르지 않는 데이터 점을 보여줍니다. 다음은 전체 데이터 집합의 적합 및 진단입니다.
문자 R은 잔차가 큰 점을 나타냅니다. 비정상적인 데이터 점을 검사하여 모형이 적합하지 않을 수 있는 예측 변수 값을 확인합니다. 문자 X는 레버리지가 높은 점을 나타냅니다. 레버리지가 높은 점에는 나머지 데이터 집합에 비해 비정상적인 예측 변수 조합이 있습니다.
큰 잔차와 높은 레버리지 포인트는 잠재적으로 영향력 있는 포인트입니다. 예를 들어, 영향력 있는 점을 포함하거나 제외함에 따라 계수가 통계적으로 유의하거나 유의하지 않은지 여부가 달라질 수 있습니다. 영향력 있는 관측치가 표시되면 관측치가 데이터 입력 오류인지 측정 오류인지 확인합니다. 관측치가 오차가 아니면 관측치가 결과에 얼마나 영향을 미치는지 확인합니다. 연구원이 모형을 더 탐색할 때 관측치가 있거나 없는 모형을 적합시킵니다. 그런 다음 계수, p-값,R2및 기타 모델 정보를 비교합니다. 영향력 있는 관측치를 제거한 경우 모형이 크게 달라지면 모형을 추가로 조사하여 모형을 잘못 지정했는지 확인합니다. 이 문제를 해결하기 위해 데이터를 추가로 수집해야 할 수도 있습니다.
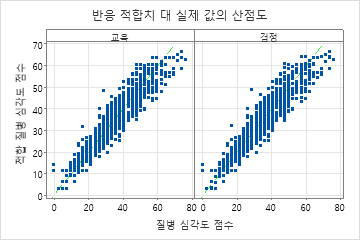
적합된 질병 점수와 실제 질병 점수의 산점도는 훈련 데이터와 검정 데이터 모두에 대한 적합치와 실제 값 간의 관계를 보여줍니다. 점들은 대략 y=x의 기준선 근처에 있으며, 이는 모형이 데이터를 잘 적합시킨다는 것을 나타냅니다.
방법
| 선형 항 및 순서 2의 항이 포함된 회귀 모델을 적합합니다. |
|---|
| 제곱 손실 함수를 사용하여 6 TreeNet® 회귀 모델을 적합합니다. |
| 교육 데이터 크기 1546과(와) 동일한 부트스트랩 표본 크기로 3 Random Forests® 분류 모델을 적합합니다. |
| 최적의 CART® 회귀 모델을 적합합니다. |
| 최적의 MARS® 회귀 모델을 적합합니다. |
| 5 접기 교차 검증에서 최대 R-제곱이 있는 모델을 선택합니다. |
| 행의 총 수: 1546 |
| 회귀 모형에 사용되는 행: 1546 |
| 트리 기반 모형에 사용되는 행: 1546 |
반응 정보
| 평균 | 표준 편차 | 최소값 | Q1 | 중위수 | Q3 | 최대값 |
|---|---|---|---|---|---|---|
| 31.0110 | 14.0820 | 0 | 19.05 | 30.95 | 40.48 | 76.19 |
| 유형 내에서 최고의 모형 | R-제곱(%) | 평균 절대 편차 |
|---|---|---|
| 다중 회귀* | 91.23 | 3.1011 |
| MARS® | 91.05 | 3.1604 |
| TreeNet® | 90.90 | 3.1613 |
| Random Forests® | 89.93 | 3.3248 |
| CART® | 86.11 | 3.9369 |
최고의 다중 회귀 모형에 대한 검증을 통한 항의 전진 선택
금 증상의 수*심한 호흡 곤란, 지금 증상의 수*심한 가슴 통증, 심한 호흡 곤란*심한 수면 장애, 전반적으로 기분이 매우 좋았습니다.*정상적인 활동에 대한 제한
회귀 방정식
| 질병 심각도 점수 | = | 1.241 + 2.5386 지금 증상의 수 + 0.0 가래의 높은 생산_0 + 3.900 가래의 높은 생산_1 + 0.0 심한 호흡 곤란_0 + 0.94 심한 호흡 곤란_1 + 0.0 심한 두통_0 + 4.094 심한 두통_1 + 0.0 심한 수면 장애_0 + 3.884 심한 수면 장애 _1 + 0.0 전반적으로 기분이 매우 좋았습니다._0 + 3.473 전반적으로 기분이 매우 좋았습니다._1 + 0.0 정상적인 활동에 대한 제한 _0 + 3.140 정상적인 활동에 대한 제한_1 + 0.0 지금 증상의 수*심한 호흡 곤란_0 + 0.373 지금 증상의 수*심한 호흡 곤란_1 + 0.0 지금 증상의 수*심한 가슴 통증_0 + 0.4765 지금 증상의 수*심한 가슴 통증_1 + 0.0 심한 호흡 곤란*심한 수면 장애_0 0 + 0.0 심한 호흡 곤란*심한 수면 장애_0 1 + 0.0 심한 호흡 곤란*심한 수면 장애_1 0 + 1.337 심한 호흡 곤란*심한 수 면 장애_1 1 + 0.0 전반적으로 기분이 매우 좋았습니다.*정상적인 활동에 대한 제한_0 0 + 0.0 전반적으로 기분이 매우 좋았습니다.*정 상적인 활동에 대한 제한_0 1 + 0.0 전반적으로 기분이 매우 좋았습니다.*정상적인 활동에 대한 제한_1 0 + 1.372 전반적으로 기분 이 매우 좋았습니다.*정상적인 활동에 대한 제한_1 1 |
|---|
계수
| 항 | 계수 | SE 계수 | T-값 | P-값 | VIF |
|---|---|---|---|---|---|
| 상수 | 1.241 | 0.385 | 3.22 | 0.001 | |
| 지금 증상의 수 | 2.5386 | 0.0593 | 42.81 | 0.000 | 1.95 |
| 가래의 높은 생산 | |||||
| 1 | 3.900 | 0.225 | 17.35 | 0.000 | 1.10 |
| 심한 호흡 곤란 | |||||
| 1 | 0.94 | 1.18 | 0.80 | 0.424 | 23.23 |
| 심한 두통 | |||||
| 1 | 4.094 | 0.253 | 16.18 | 0.000 | 1.25 |
| 심한 수면 장애 | |||||
| 1 | 3.884 | 0.284 | 13.69 | 0.000 | 1.73 |
| 전반적으로 기분이 매우 좋았습니다. | |||||
| 1 | 3.473 | 0.343 | 10.14 | 0.000 | 2.62 |
| 정상적인 활동에 대한 제한 | |||||
| 1 | 3.140 | 0.424 | 7.40 | 0.000 | 3.98 |
| 지금 증상의 수*심한 호흡 곤란 | |||||
| 1 | 0.373 | 0.133 | 2.81 | 0.005 | 26.80 |
| 지금 증상의 수*심한 가슴 통증 | |||||
| 1 | 0.4765 | 0.0312 | 15.26 | 0.000 | 1.25 |
| 심한 호흡 곤란*심한 수면 장애 | |||||
| 1 1 | 1.337 | 0.528 | 2.53 | 0.011 | 3.26 |
| 전반적으로 기분이 매우 좋았습니다.*정상적인 활동에 대한 제한 | |||||
| 1 1 | 1.372 | 0.527 | 2.61 | 0.009 | 5.73 |
모형 요약
| 통계량 | 교육 | 검정 |
|---|---|---|
| R-제곱 | 91.35% | 91.23% |
| 루트 평균 제곱 오차(RMSE) | 4.1562 | 4.1679 |
| 평균 제곱 오차(MSE) | 17.2741 | 17.3714 |
| 평균 절대 편차(MAD) | 3.0798 | 3.1011 |
| R-제곱(수정) | 91.29% | |
| R-제곱(예측) | 91.19% |
분산 분석
| 출처 | DF | Adj SS | Adj MS | F-값 | P-값 |
|---|---|---|---|---|---|
| 회귀 | 11 | 279881 | 25443.7 | 1472.94 | 0.000 |
| 지금 증상의 수 | 1 | 31655 | 31654.8 | 1832.51 | 0.000 |
| 가래의 높은 생산 | 1 | 5202 | 5201.8 | 301.14 | 0.000 |
| 심한 호흡 곤란 | 1 | 11 | 11.1 | 0.64 | 0.424 |
| 심한 두통 | 1 | 4520 | 4520.0 | 261.66 | 0.000 |
| 심한 수면 장애 | 1 | 3239 | 3238.8 | 187.50 | 0.000 |
| 전반적으로 기분이 매우 좋았습니다. | 1 | 1776 | 1775.6 | 102.79 | 0.000 |
| 정상적인 활동에 대한 제한 | 1 | 945 | 945.4 | 54.73 | 0.000 |
| 지금 증상의 수*심한 호흡 곤란 | 1 | 136 | 136.4 | 7.90 | 0.005 |
| 지금 증상의 수*심한 가슴 통증 | 1 | 4023 | 4023.4 | 232.92 | 0.000 |
| 심한 호흡 곤란*심한 수면 장애 | 1 | 111 | 110.7 | 6.41 | 0.011 |
| 전반적으로 기분이 매우 좋았습니다.*정상적인 활동에 대한 제한 | 1 | 117 | 117.3 | 6.79 | 0.009 |
| 오차 | 1534 | 26498 | 17.3 | ||
| 적합성 결여 | 484 | 9247 | 19.1 | 1.16 | 0.025 |
| 순수 오차 | 1050 | 17251 | 16.4 | ||
| 총계 | 1545 | 306379 |
비정상적 관측치에 대한 적합치 및 진단
| 관측 | 질병 심각도 점수 | 적합치 | 잔차 | 표준화 잔차 | ||
|---|---|---|---|---|---|---|
| 11 | 66.670 | 56.757 | 9.913 | 2.40 | R | |
| 13 | 52.380 | 41.177 | 11.203 | 2.71 | R | |
| 16 | 59.520 | 48.604 | 10.916 | 2.64 | R | |
| 33 | 50.000 | 60.657 | -10.657 | -2.57 | R | |
| 48 | 64.290 | 55.416 | 8.874 | 2.14 | R | |
| 52 | 61.900 | 53.369 | 8.531 | 2.06 | R | |
| 54 | 50.000 | 41.598 | 8.402 | 2.03 | R | |
| 56 | 50.000 | 58.328 | -8.328 | -2.02 | R | |
| 58 | 38.100 | 46.485 | -8.385 | -2.03 | R | |
| 106 | 59.520 | 49.028 | 10.492 | 2.53 | R | |
| 114 | 59.520 | 47.160 | 12.360 | 2.99 | R | |
| 128 | 69.050 | 58.328 | 10.722 | 2.59 | R | |
| 144 | 50.000 | 40.471 | 9.529 | 2.30 | R | |
| 173 | 47.620 | 56.757 | -9.137 | -2.21 | R | |
| 174 | 42.860 | 34.000 | 8.860 | 2.14 | R | |
| 191 | 42.860 | 52.051 | -9.191 | -2.23 | R | |
| 198 | 59.520 | 48.411 | 11.109 | 2.68 | R | |
| 202 | 73.810 | 64.046 | 9.764 | 2.36 | R | |
| 205 | 47.620 | 37.559 | 10.061 | 2.43 | R | |
| 213 | 35.710 | 34.970 | 0.740 | 0.18 | X | |
| 217 | 16.670 | 19.053 | -2.383 | -0.58 | X | |
| 239 | 47.620 | 58.328 | -10.708 | -2.59 | R | |
| 241 | 71.430 | 66.311 | 5.119 | 1.25 | X | |
| 243 | 14.290 | 24.088 | -9.798 | -2.36 | R | |
| 304 | 50.000 | 41.130 | 8.870 | 2.14 | R | |
| 307 | 14.290 | 10.920 | 3.370 | 0.83 | X | |
| 352 | 64.290 | 51.254 | 13.036 | 3.15 | R | |
| 369 | 38.100 | 49.275 | -11.175 | -2.70 | R | |
| 391 | 16.670 | 32.073 | -15.403 | -3.72 | R | |
| 392 | 0.000 | 11.395 | -11.395 | -2.75 | R | |
| 395 | 0.000 | 13.934 | -13.934 | -3.36 | R | |
| 424 | 40.480 | 52.504 | -12.024 | -2.90 | R | |
| 425 | 47.620 | 34.597 | 13.023 | 3.16 | R | |
| 474 | 47.620 | 38.538 | 9.082 | 2.21 | R | |
| 479 | 40.480 | 30.896 | 9.584 | 2.31 | R | |
| 489 | 16.670 | 25.023 | -8.353 | -2.02 | R | |
| 491 | 30.950 | 24.348 | 6.602 | 1.61 | X | |
| 493 | 57.140 | 44.339 | 12.801 | 3.09 | R | |
| 495 | 35.710 | 25.480 | 10.230 | 2.47 | R | |
| 509 | 38.100 | 26.696 | 11.404 | 2.77 | R | |
| 520 | 73.810 | 58.328 | 15.482 | 3.75 | R | |
| 537 | 38.100 | 28.358 | 9.742 | 2.35 | R | |
| 550 | 14.290 | 24.458 | -10.168 | -2.45 | R | |
| 583 | 42.860 | 53.369 | -10.509 | -2.54 | R | |
| 694 | 19.050 | 21.817 | -2.767 | -0.68 | X | |
| 720 | 59.520 | 65.602 | -6.082 | -1.49 | X | |
| 722 | 40.480 | 32.066 | 8.414 | 2.03 | R | |
| 802 | 30.950 | 42.586 | -11.636 | -2.81 | R | |
| 805 | 30.950 | 39.868 | -8.918 | -2.16 | R | |
| 814 | 40.480 | 32.073 | 8.407 | 2.03 | R | |
| 823 | 61.900 | 48.148 | 13.752 | 3.33 | R | |
| 833 | 33.330 | 44.054 | -10.724 | -2.60 | R | |
| 859 | 38.100 | 49.275 | -11.175 | -2.70 | R | |
| 868 | 47.620 | 37.789 | 9.831 | 2.38 | R | |
| 891 | 30.950 | 19.945 | 11.005 | 2.66 | R | |
| 893 | 28.570 | 48.860 | -20.290 | -4.92 | R | |
| 905 | 45.240 | 55.416 | -10.176 | -2.46 | R | |
| 924 | 54.760 | 56.019 | -1.259 | -0.31 | X | |
| 977 | 64.290 | 53.107 | 11.183 | 2.72 | R | |
| 983 | 57.140 | 47.683 | 9.457 | 2.29 | R | |
| 988 | 50.000 | 44.501 | 5.499 | 1.34 | X | |
| 993 | 73.810 | 64.046 | 9.764 | 2.36 | R | |
| 997 | 33.330 | 24.458 | 8.872 | 2.14 | R | |
| 1003 | 54.760 | 45.128 | 9.632 | 2.33 | R | |
| 1025 | 33.330 | 47.705 | -14.375 | -3.49 | R | |
| 1059 | 57.140 | 48.663 | 8.477 | 2.05 | R | |
| 1105 | 47.620 | 37.319 | 10.301 | 2.49 | R | |
| 1150 | 59.520 | 44.339 | 15.181 | 3.67 | R | |
| 1160 | 52.380 | 40.051 | 12.329 | 2.97 | R | |
| 1163 | 30.950 | 41.598 | -10.648 | -2.57 | R | |
| 1165 | 69.050 | 56.757 | 12.293 | 2.97 | R | |
| 1169 | 59.520 | 49.275 | 10.245 | 2.48 | R | |
| 1198 | 42.860 | 51.516 | -8.656 | -2.09 | R | |
| 1207 | 76.190 | 63.534 | 12.656 | 3.07 | R | |
| 1213 | 26.190 | 40.278 | -14.088 | -3.41 | R | |
| 1228 | 40.480 | 50.571 | -10.091 | -2.45 | R | |
| 1235 | 59.520 | 50.175 | 9.345 | 2.26 | R | |
| 1237 | 57.140 | 48.239 | 8.901 | 2.15 | R | |
| 1246 | 64.290 | 55.416 | 8.874 | 2.14 | R | |
| 1262 | 45.240 | 35.957 | 9.283 | 2.24 | R | |
| 1263 | 57.140 | 43.951 | 13.189 | 3.18 | R | |
| 1282 | 33.330 | 36.011 | -2.681 | -0.65 | X | |
| 1284 | 45.240 | 56.564 | -11.324 | -2.74 | R | |
| 1285 | 47.620 | 60.657 | -13.037 | -3.15 | R | |
| 1303 | 26.190 | 36.567 | -10.377 | -2.51 | R | |
| 1305 | 35.710 | 45.499 | -9.789 | -2.36 | R | |
| 1311 | 30.950 | 40.089 | -9.139 | -2.21 | R | |
| 1345 | 26.190 | 25.105 | 1.085 | 0.26 | X | |
| 1353 | 42.860 | 53.175 | -10.315 | -2.49 | R | |
| 1365 | 26.190 | 17.834 | 8.356 | 2.01 | R | |
| 1377 | 47.620 | 35.222 | 12.398 | 3.00 | R | |
| 1380 | 69.050 | 55.416 | 13.634 | 3.29 | R | |
| 1384 | 50.000 | 38.496 | 11.504 | 2.78 | R | |
| 1414 | 26.190 | 35.345 | -9.155 | -2.21 | R | |
| 1502 | 61.900 | 50.195 | 11.705 | 2.84 | R | |
| 1526 | 38.100 | 25.450 | 12.650 | 3.05 | R | |
| 1535 | 14.290 | 24.088 | -9.798 | -2.36 | R | |
| 1544 | 38.100 | 29.165 | 8.935 | 2.16 | R | |
| 1548 | 50.000 | 40.455 | 9.545 | 2.31 | R | |
| 1565 | 38.100 | 42.846 | -4.746 | -1.16 | X | |
| 1582 | 66.670 | 55.437 | 11.233 | 2.72 | R |
대체 모형 선택
연구원들은 최상의 TreeNet® 모델에 대한 결과를 조사하기로 결정합니다.
- 에 대한 최고의 모형 검색(계량형 반응)결과에서 을 선택합니다 대체 모델 선택.
- 모형 유형에서 TreeNet®를 선택합니다.
- 에서 기존 모형 선택R2의 값이 가장 좋은 6번째 모형을 선택합니다.
- 결과 표시을 클릭합니다.
결과 해석
이 분석에서는 300그루의 나무를 키우며 최적의 나무 수는 63개입니다. 이 모델은 학습률 0.1과 하위 표본 부분 0.7을 사용합니다. 최대 터미널 노드 수는 6개입니다.
방법
| 손실 함수 | 제곱 오차 |
|---|---|
| 최적 트리 수 선택 기준 | 최대 R-제곱 |
| 모형 검증 | 5-접기 교차 검증 |
| 학습률 | 0.1 |
| 하위 표본 부분 | 0.7 |
| 트리당 최대 터미널 노드 수 | 6 |
| 최소 단말 노드 크기 | 3 |
| 노드 분할을 위해 선택된 예측 변수 수 | 총 예측 변수 수 = 8 |
| 사용된 행 | 1546 |
| 사용되지 않은 행 | 70 |
반응 정보
| 평균 | 표준 편차 | 최소값 | Q1 | 중위수 | Q3 | 최대값 |
|---|---|---|---|---|---|---|
| 31.0110 | 14.0820 | 0 | 19.05 | 30.95 | 40.48 | 76.19 |
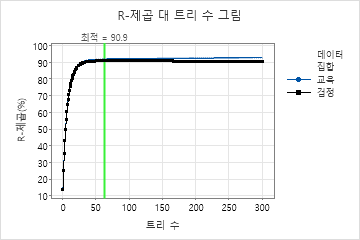
R-제곱 대 트리 수 그림은 성장한 트리 수에 대한 전체 곡선을 보여줍니다. 트리 수가 63개일 때 검정 데이터의 최적 값은 약 91%입니다.
모형 요약
| 전체 예측 변수 | 8 |
|---|---|
| 중요 예측 변수 | 8 |
| 성장한 트리 수 | 300 |
| 최적의 트리 수 | 63 |
| 통계량 | 교육 | 검정 |
|---|---|---|
| R-제곱 | 91.93% | 90.90% |
| 루트 평균 제곱 오차(RMSE) | 3.9992 | 4.2471 |
| 평균 제곱 오차(MSE) | 15.9932 | 18.0375 |
| 평균 절대 편차(MAD) | 2.9943 | 3.1613 |
| 평균 절대 백분율 오차(MAPE) | 0.1088 | 0.1130 |
모델 요약 표는 트리 수가 63개일 때 R2 값이 학습 데이터의 경우 약92%이고 검정 데이터의 경우 약 91%임을 보여줍니다.
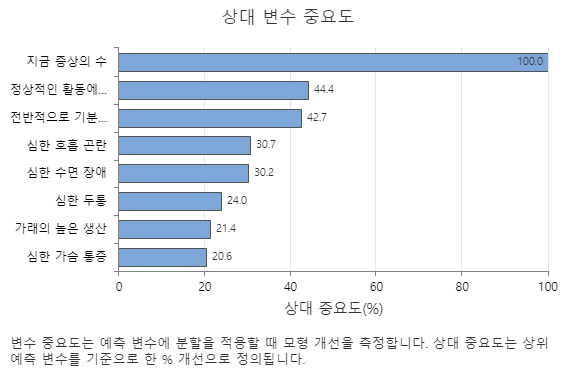
상대 변수 중요도 그래프는 트리 시퀀스에 대한 예측 변수에 분할이 이루어질 때 모형 개선에 미치는 영향 순으로 예측 변수를 표시합니다. 가장 중요한 예측 변수는 지금 증상의 수입니다. 상위 예측 변수 ,의 기여도가 100%이면 다음으로 중요한 변수 지금 증상의 수 정상적인 활동에 대한 제한인 의 기여도는 44.4%입니다. 이는 이 회귀 모델에서보다 지금 증상의 수 44.4% 더 중요하다는 것을 의미합니다 정상적인 활동에 대한 제한 .
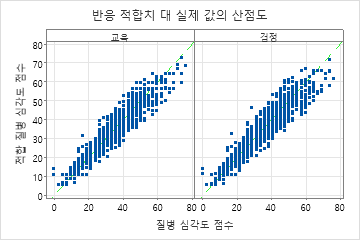
적합된 질병 점수와 실제 질병 점수의 산점도는 훈련 데이터와 검정 데이터 모두에 대한 적합치와 실제 값 간의 관계를 보여줍니다. 점들은 대략 y=x의 기준선 근처에 있으며, 이는 모형이 데이터를 잘 적합시킨다는 것을 나타냅니다.
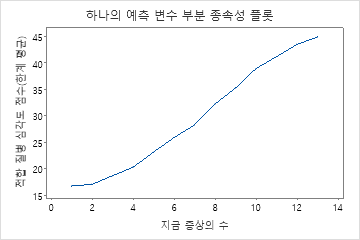
부분 종속성도를 사용하면 중요한 변수 또는 변수 쌍이 적합 반응 값에 어떤 영향을 미치는지 파악할 수 있습니다. 부분 종속성 플롯은 반응과 변수 간의 관계가 선형, 단조로움 또는 더 복잡한지 여부를 보여줍니다.
첫 번째 그림은 질병 점수와 현재 환자의 증상 수 간의 관계를 보여줍니다. 개별 데이터 포인트 위로 마우스를 가져가면 특정 x 및 y 값을 볼 수 있습니다. 예를 들어, 그래프 오른쪽의 가장 높은 지점은 환자에게 13개의 증상이 있고 적합된 질병 점수가 약 45인 경우입니다.
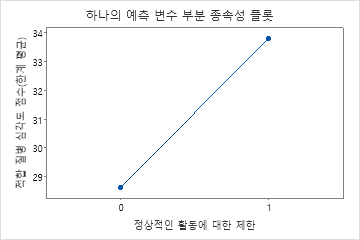
두 번째 그림은 환자가 정상적인 활동에 대한 제한을 보고할 때 적합된 질병 점수가 약 5점 증가한다는 것을 보여줍니다.
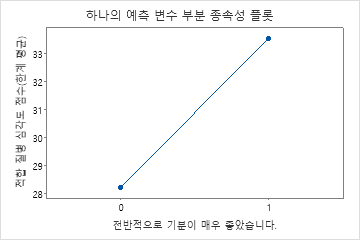
세 번째 그림은 환자가 일반적으로 매우 나쁘다고 보고할 때 적합된 질병 점수가 약 5점 증가한다는 것을 보여줍니다.
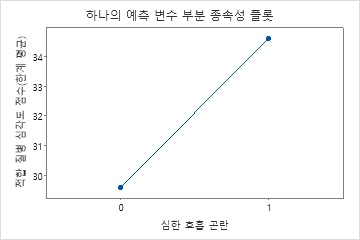
네 번째 그림은 환자가 심한 숨가쁨을 보고할 때 적합 질병 점수가 약 4점 증가한다는 것을 보여줍니다.
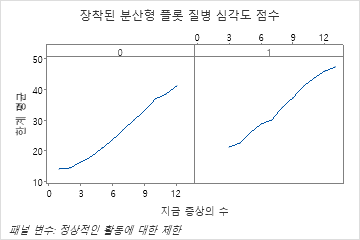
마지막 그림은 여러 증상에 대한 적합 질병 점수가 환자의 정상적인 활동에도 제한이 있는지 여부에 따라 어떻게 달라지는지 보여줍니다. 동일한 수의 증상에 대해 정상 활동에 대한 제한을보고하는 환자는 적합 질병 점수가 더 높습니다.