참고
이 명령은 예측 분석 모듈에서 사용할 수 있습니다. 모듈을 활성화하는 방법에 대한 자세한 내용은 여기를 클릭하십시오.
한 연구팀이 아이오와주 에임스에 있는 개별 주거용 부동산의 매각에서 데이터를 수집합니다. 연구원들은 판매 가격에 영향을 미치는 변수를 파악하고자 합니다. 변수에는 대지 규모와 주거용 부동산의 다양한 특징들이 포함됩니다.
팀은 중요한 예측 변수를 식별하기 위해 CART® 회귀 분석을 사용한 초기 탐색 후 Random Forests® 회귀 분석을(를) 사용하여 동일한 데이터 집합에서 보다 집중적인 모형을 만듭니다. 팀은 모형 요약 표와 결과의 R2 그림을 비교하여 어떤 모형이 더 나은 예측 결과를 제공하는지 평가합니다.
이러한 데이터는 에임스 주택 공급에 대한 정보가 포함된 공개 데이터를 기준으로 조정되었습니다. DeCock, 트루먼 주립대학의 원본 데이터.
- 표본 데이터 에임스주택.MWX를 엽니다.
- 을 선택합니다.
- 반응에 '판매 가격'을 입력합니다.
- 에 계량형 예측 변수'로트 프론트' – '년 판매’를 입력합니다.
- 에 범주형 예측 변수'유형' – '판매 조건’를 입력합니다.
- 옵션을 클릭합니다.
- 노드 분할 예측 변수 수에서 총 예측 변수 수의 K%, K =을 선택하고 30을 입력합니다. 연구원들은 이 분석을 위해 기본 예측 변수 수를 넘게 사용하고자 합니다.
- 각 대화 상자에서 확인를 클릭합니다.
결과 해석
방법
| 모형 검증 | OOB 데이터로 검증 |
|---|---|
| 부트스트랩 표본 수 | 300 |
| 표본 크기 | 학습 데이터 크기 2930과 동일 |
| 노드 분할을 위해 선택된 예측 변수 수 | 총 예측 변수 수의 30% = 23 |
| 최소 내부 노드 크기 | 5 |
| 사용된 행 | 2930 |
반응 정보
| 평균 | 표준 편차 | 최소값 | Q1 | 중위수 | Q3 | 최대값 |
|---|---|---|---|---|---|---|
| 180796 | 79886.7 | 12789 | 129500 | 160000 | 213500 | 755000 |
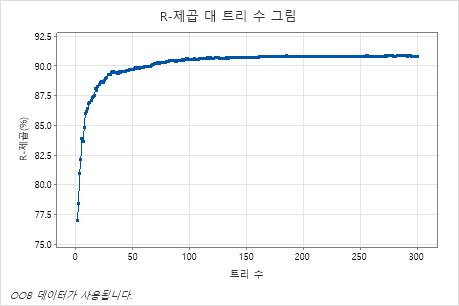
R-제곱 대 트리 수 그림은 성장한 트리 수에 대한 전체 곡선을 보여줍니다. R2 값은 트리의 수가 증가함에 따라 빠르게 증가하다가 대략 91%에서 평평해진다.
모형 요약
| 전체 예측 변수 | 77 |
|---|---|
| 중요 예측 변수 | 68 |
| 통계량 | OOB |
|---|---|
| R-제곱 | 90.90% |
| 루트 평균 제곱 오차(RMSE) | 24097.3281 |
| 평균 제곱 오차(MSE) | 5.80681E+08 |
| 평균 절대 편차(MAD) | 14746.8323 |
| 평균 절대 백분율 오차(MAPE) | 0.0895 |
모형 요약 표는 해당 CART® 분석의 R2 값에 비해 R2 값이 약간 향상되어 있음을 보여줍니다.

상대 변수 중요도 그래프는 트리 시퀀스에 대한 예측 변수에 분할이 이루어질 때 모형 개선에 미치는 영향 순으로 예측 변수를 표시합니다. 판매가를 예측하기 위한 가장 중요한 예측 변수는 품질입니다. 상위 예측 변수인 품질의 중요도가 100%이면 다음으로 중요한 변수인 생활 영역 SF의 기여도가 88.8%입니다. 이것은 생활의 평방 피트가 부동산의 전반적인 품질만큼 88.8% 중요하다는 것을 의미합니다. 다음으로 가장 중요한 변수는 52.6%의 기여도를 가진 이웃입니다.
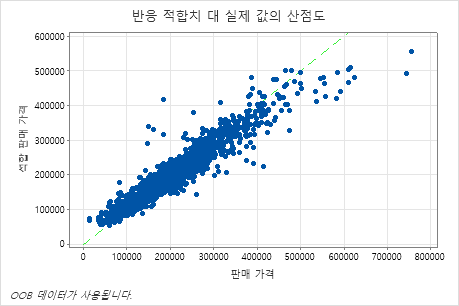
적합된 판매가 대 실제 판매가의 산점도는 OOB 데이터에 대한 적합치와 실제 값 간의 관계를 보여줍니다. 그래프의 점 위로 마우스 포인터를 옮기면 표시된 값을 보다 쉽게 볼 수 있습니다. 이 예제에서 y=x의 참조 선 부근에 많은 점이 있지만 몇 개의 점은 적합치와 실제 값 간의 불일치를 확인하기 위해 조사가 필요할 수 있습니다.