분포 모수의 ML 추정치
최대우도(ML) 방법은 각 분포에 대한 우도 함수를 최대화하는 분포 모수의 값을 추정합니다. 목표는 분포 모형과 관측된 표본 데이터 사이에 최적의 합치도"를 얻는 것입니다.
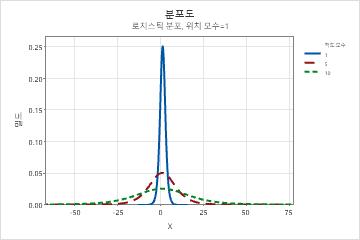
- 위치
- 이 모수는 분포 위치에 영향을 미칩니다. 예를 들어, 여러 위치 모수를 사용하면 로지스틱 분포가 수평 축을 따라 이동할 수 있습니다.
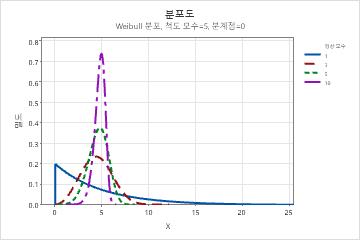
- 형상
- 이 모수는 분포 형상에 영향을 미칩니다. 예를 들어, 여러 형상 모수를 사용하면 Weibull 분포가 더 치우치거나 더 대칭적으로 보일 수 있습니다.
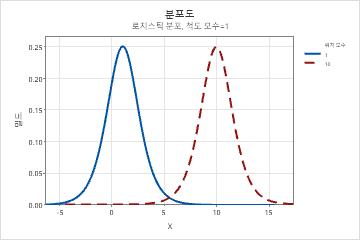
- 척도
- 이 모수는 분포 척도에 영향을 미칩니다. 예를 들어, 여러 척도 모수를 사용하면 로지스틱 분포가 더 "확장"되거나 더 압축된 것으로 보일 수 있습니다.
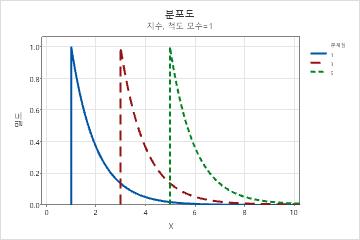
- 분계점
- 이 모수는 랜덤 변수의 최소값에 영향을 미칩니다. 예를 들어, 여러 분계점 모수를 사용하면 다른 값의 범위에서 지수 분포를 정의할 수 있습니다.
참고
Minitab에서는 불편화 모수 추정치를 사용하는 정규 분포와 대수 정규 분포를 제외한 모든 분포에 대해 최대우도 방법을 사용하여 모수 추정치를 계산합니다.
해석
데이터에 사용되는 특정 분포 모형을 확인하려면 분포 모수의 ML 추정치를 사용하십시오. 예를 들어, 한 품질 엔지니어가 과거의 공정 지식과 Anderson-Darling 및 LRT p-값을 기반으로 3-모수 Weibull 분포가 공정 데이터에 대해 최량 적합치를 제공하는 것을 확인한다고 가정합니다. 엔지니어는 데이터를 모형화하기 위해 사용되는 특정 3-모수 Weibull 분포를 이해하기 위해 분포에 대해 계산된 형상, 척도 및 분계점에 대한 ML 추정치를 조사합니다.
분포
이 분석은 일반적으로 사용되는 여러 분포에 대한 적합도 통계량과 분포 모수를 제공합니다. 이 중 대부분의 분포가 유용하며 양수 값, 음수 값, 0이 포함된 데이터 등 여러 계량형 데이터를 모형화할 수 있습니다.
- 로그 정규 분포
- 지수 분포
- Weibull 분포
- 감마
- 로그 로지스틱 분포
따라서 데이터에 음수 값이나 0이 포함된 경우 Minitab에서는 이러한 특정 분포에 대한 결과를 보고하지 않습니다. 이 경우 각 분포의 더 높은 모수 버전에 대한 결과를 사용하십시오. 예를 들어, 데이터에 음수 값이 포함된 경우 Minitab에서는 로그 정규 분포에 대한 결과를 보고하지 않습니다. 대신 3-모수 대수 정규 분포에 대한 결과를 사용하십시오.
분포에 대한 자세한 내용은 을 참조하십시오 Weibull 분포가 비정규 공정 능력 분석의 기본 분포인 이유.
참고
각 분포에 대한 PDF와 CDF를 계산하기 위해 사용되는 공식에 대한 내용은 개별 분포 식별의 분포에 대한 방법 및 공식에서 확인하십시오.
P
참고
Weibull 분포를 제외한 3-모수 분포의 경우에는 AD 검정에 대한 p-값을 사용할 수 없습니다.
해석
분포의 적합도를 평가하려면 p-값을 사용합니다.
- P ≤ α : 데이터가 분포를 따르지 않음(H0기각)
- p-값이 유의 수준보다 작거나 같으면 귀무 가설을 기각하고 데이터가 분포를 따르지 않는다는 결론을 내립니다.
- P > α: 데이터가 분포를 따르지 않는다는 결론을 내릴 수 없음(H0기각 실패)
- p-값이 유의 수준보다 크면 귀무 가설을 기각할 수 없습니다. 데이터가 분포를 따르지 않는다는 결론을 내릴 만한 충분한 증거가 없습니다. 데이터가 분포를 따른다고 가정할 수 있습니다.
- 해당 업종이나 분야에서 가장 일반적으로 사용되는 분포를 선택합니다.
- 가장 보수적인 결과를 제공하는 분포를 선택합니다. 예를 들어, 공정 능력 분석을 수행하는 경우 여러 분포를 사용하여 분석을 수행한 다음 가장 보수적인 공정 능력 지수를 산출하는 분포를 선택할 수 있습니다. 자세한 내용은 "백분율 및 백분위수"로 개별 분포 식별에 대한 분포 백분위수 이동하여 클릭하십시오.
- 데이터를 잘 적합시키는 가장 간단한 분포를 선택합니다. 예를 들어, 2-모수 및 3-모수 분포 모두 데이터를 잘 적합시키는 경우 더 간단한 2-모수 분포를 선택할 수 있습니다.
중요
매우 작거나 매우 큰 표본으로부터의 결과를 해석하는 경우 주의하십시오. 표본이 너무 작으면 적합도 검정이 분포에서 유의한 편차를 탐지하기 위한 검정력이 충분하지 않을 수도 있습니다. 표본이 너무 크면 검정의 검정력이 매우 커서 분포에서 실제적으로 유의하지 않은 작은 편차도 탐지할 수도 있습니다. 분포 적합도를 평가하려면 p-값 외에 확률도를 사용하십시오.
자동화된 공정 능력 분배 결과: 칼슘
| 분포 | 위치 | 척도 | 분계점 | 형상 | P | Ppk | Cpk |
|---|---|---|---|---|---|---|---|
| 정규 분포 | 50.7820 | 2.7648 | 0.0463827 | 1.2999 | 1.3504 | ||
| Weibull 분포 | 52.1368 | 17.825 | <0.01 | 0.7907 | |||
| 로그 정규 분포* | 3.9261 | 0.0537 | 0.0848247 | 1.4732 | |||
| 최소극단값 분포 | 52.2226 | 2.9589 | <0.01 | 0.7153 | |||
| 최대 극단값 분포 | 49.5037 | 2.1699 | >0.25 | ||||
| 감마 분포 | 0.1447 | 351.044 | 0.0706812 | 1.4275 | |||
| 로지스틱 분포 | 50.5718 | 1.5948 | 0.0339831 | 1.0023 | |||
| 로그 로지스틱 분포 | 3.9226 | 0.0312 | 0.0495201 | 1.0864 | |||
| 지수 | 50.7820 | <0.0025 | -0.0378 | ||||
| 3-모수 Weibull 분포 | 4.5365 | 46.6658 | 1.476 | >0.5 | |||
| 3-모수 로그 정규 분포 | 1.6930 | 0.4685 | 44.7401 | ||||
| 3-모수 감마 분포 | 1.6370 | 45.8838 | 2.992 | ||||
| 3-모수 로지스틱 분포 | 1.5486 | 0.3276 | 45.4618 | ||||
| 2-모수 지수 분포 | 4.0633 | 46.7187 | 0.0140796 | ||||
| Box-Cox 변환 | 0.0000 | 0.0000 | 0.324445 | 2.5062 | 2.5335 | ||
| Johnson 변환 | 0.0290 | 0.9729 | 0.985835 | 2.7129 | |||
| 비모수 | 2.8889 |
이 결과에서 로그 정규 분포는 0.05 유의 수준에서 데이터를 적합하는 첫 번째 방법입니다. 다른 분포 및 변환도 데이터에 대한 적절한 적합도를 제공합니다. 이러한 대체 방법 중 하나라도 프로세스와 더 호환되는지 여부를 고려합니다.
참고
여러 분포의 경우 Minitab에서는 추가 모수가 있는 분포에 대한 결과도 표시합니다. 예를 들어, 대수 정규 분포의 경우에는 분포의 2-모수 및 3-모수 버전 둘 다에 대한 결과를 표시합니다. 추가 파라미터가 있는 분포의 경우, 추가 파라미터가 공정에 대해 알고 있는 것과 호환되는지 여부를 고려하십시오. 예를 들어, 공정의 물리적 경계가 0이 아닌 경우 임계값 모수가 있는 분포는 공정과 호환됩니다.
Ppk
- 공정 평균과 규격 한계(규격 상한 또는 규격 하한) 간의 거리
- 전체 변동을 기반으로 한 공정의 단측 산포(3-σ 변동)
해석
공정 위치 및 공정 산포를 기반으로 공정의 전체 공정 능력을 평가하려면 Ppk를 사용합니다. 전체 공정 능력은 시간이 지남에 따라 고객이 경험하는 공정의 실제 성능을 나타냅니다.
일반적으로 Ppk 값이 높으면 공정의 공정 능력이 더 크다는 것을 나타냅니다. Ppk 값이 낮으면 공정 개선이 필요할 수도 있음을 나타냅니다.
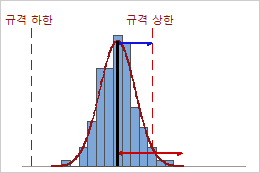
낮은 Ppk
이 예에서는 공정 평균과 가장 가까운 규격 한계(규격 상한) 간의 거리가 단측 공정 산포보다 작습니다. 따라서 Ppk가 낮고(0.66) 공정의 전체 공정 능력이 좋지 않습니다.
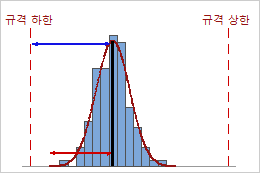
높은 Ppk
이 예에서는 공정 평균과 가장 가까운 규격 한계(규격 하한) 간의 거리가 단측 공정 산포보다 큽니다. 따라서 Ppk가 높고(1.68) 공정의 전체 공정 능력이 좋습니다.
-
Ppk를 공정에 허용되는 최소값을 나타내는 벤치마크 값과 비교합니다. 많은 업종에서 1.33을 벤치마크 값으로 사용합니다. Ppk가 벤치마크보다 낮으면 공정을 개선하는 방법을 고려해 보십시오.
-
Pp와 Ppk를 비교합니다. Pp와 Ppk가 근사적으로 같으면 공정은 규격 한계 사이에 중심화되어 있습니다. Pp와 Ppk가 서로 다르면 공정이 중심화되어 있지 않습니다.
-
Ppk와 Cpk를 비교합니다. 공정이 통계적 관리 상태에 있는 경우 Ppk와 Cpk가 근사적으로 같습니다. Ppk와 Cpk의 차이는 공정의 이동과 경향을 제거한 경우 기대할 수 있는 공정 능력의 개선을 나타냅니다.
주의
Ppk 지수는 공정 곡선의 한 쪽만 나타내며, 공정 곡선의 반대쪽에서 공정이 얼마나 잘 수행되는 지는 나타내지 않습니다.
예를 들어, 다음 그래프는 동일한 Ppk 값을 갖는 두 공정을 표시합니다. 그러나 한 공정은 두 규격 한계를 모두 위반하며 다른 공정은 규격 상한만 위반합니다.
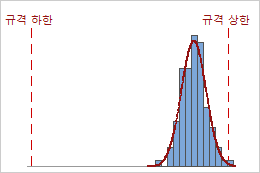
Ppk = min {PPL = 4.01, PPU = 0.64} = 0.64
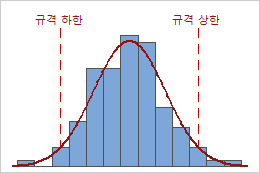
Ppk = PPL = PPU = 0.64
공정에 규격 한계의 양쪽에 모두 해당되는 불량 부품이 있을 경우 다른 지수(Z.bench 등)를 사용하여 공정 능력을 더 완전하게 평가하는 방법을 고려하십시오.
Cpk
- 공정 평균과 규격 한계(규격 상한 또는 규격 하한) 간의 거리
- 부분군 군내 표준 편차를 기반으로 한 공정의 단측 산포(3-σ 변동)
해석
공정 위치 및 공정 산포를 기반으로 공정의 잠재적 공정 능력을 평가하려면 Cpk를 사용합니다. 잠재적 공정 능력은 공정 이동과 경향이 제거된 경우 달성할 수 있는 공정 능력을 나타냅니다.
일반적으로 Cpk 값이 높으면 공정의 공정 능력이 더 크다는 것을 나타냅니다. Cpk 값이 낮으면 공정 개선이 필요할 수도 있음을 나타냅니다.
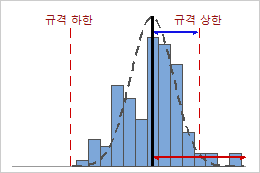
낮은 Cpk
이 예에서는 공정 평균과 가장 가까운 규격 한계(규격 상한) 간의 거리가 단측 공정 산포보다 작습니다. 따라서 Cpk가 낮고(0.80) 공정의 잠재적 공정 능력이 좋지 않습니다.
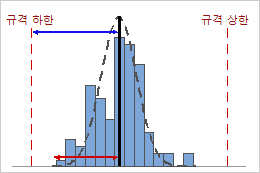
높은 Cpk
이 예에서는 공정 평균과 가장 가까운 규격 한계(규격 하한) 간의 거리가 단측 공정 산포보다 큽니다. 따라서 Cpk가 높고(1.64) 공정의 잠재적 공정 능력이 좋습니다.
Cpk를 다른 값과 비교하여 공정의 공정 능력에 대한 추가 정보를 얻을 수 있습니다.
-
Cpk를 공정에 허용되는 최소값을 나타내는 벤치마크 값과 비교합니다. 많은 업종에서 1.33을 벤치마크 값으로 사용합니다. Cpk가 벤치마크보다 낮으면 변동을 줄이거나 위치를 이동하는 등 공정을 개선하는 방법을 고려해 보십시오.
-
Cp와 Cpk를 비교합니다. Cp와 Cpk가 근사적으로 같으면 공정은 규격 한계 사이에 중심화되어 있습니다. Cp와 Cpk가 서로 다르면 공정이 중심화되어 있지 않습니다.
-
Ppk와 Cpk를 비교합니다. 공정이 통계적 관리 상태에 있는 경우 Ppk와 Cpk가 근사적으로 같습니다. Ppk와 Cpk의 차이는 공정의 이동과 경향을 제거한 경우 기대할 수 있는 공정 능력의 개선을 나타냅니다.
주의
Cpk 지수는 공정 곡선의 한 쪽만 나타내며, 공정 곡선의 반대쪽에서 공정이 얼마나 잘 수행되는 지는 나타내지 않습니다.
예를 들어, 다음 그래프는 동일한 Cpk 값을 갖는 두 공정을 표시합니다. 그러나 한 공정은 두 규격 한계를 모두 위반하며 다른 공정은 규격 상한만 위반합니다.
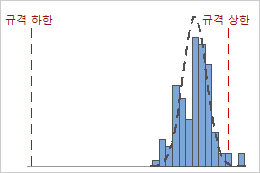
Cpk = min {CPL = 4.58, CPU = 0.93} = 0.93
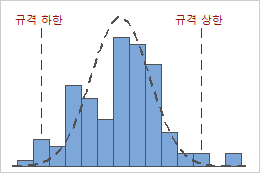
Cpk = CPL = CPU = 0.93
공정에 규격 한계의 양쪽에 모두 해당되는 불량 부품이 있을 경우 다른 지수(Z.bench 등)를 사용하여 공정 능력을 더 완전하게 평가하는 방법을 고려하십시오.
Cnpk
Cnpk는 공정의 전체 공정 능력의 측도이며 Cnpu 및 Cnpl의 최소값과 같습니다.
- 공정 중위수에서 규격 상한까지의 단측 규격 산포
- 공정 산포의 절반, 공정 중앙값에서 공정 상한의 추정치까지
- 공정 중위수에서 규격 하한까지의 단측 규격 산포
- 공정 산포의 절반, 공정 중위수에서 공정 하한의 추정치까지
해석
Cnpk를 사용하여 공정 위치와 공정 산포를 기반으로 공정의 전체 공정 능력을 평가할 수 있습니다. 전체 공정 능력은 시간이 지남에 따라 고객이 경험하는 공정의 실제 성능을 나타냅니다.
일반적으로 Cnpk 값이 높을수록 공정 능력이 더 높다는 것을 나타냅니다. Cnpk 값이 낮으면 공정 개선이 필요할 수도 있음을 나타냅니다.
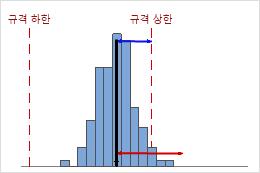
낮은 Cnpk
이 예에서는 공정이 규격 하한보다 규격 상한에 대해 더 나쁘게 수행됩니다. Cnpk 값은 Cnpu(≈ 0.40)와 같으며, 이는 낮고 공정 능력이 좋지 않음을 나타냅니다.
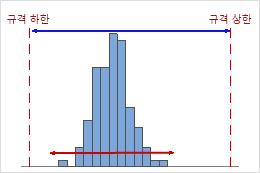
높은 Cnpk
이 예에서는 공정이 규격 상한보다 규격 하한에 대해 더 나쁘게 수행됩니다. Cnpk 값은 Cnpl(≈ 1.40)과 같으며, 이는 높고 공정 능력이 양호함을 나타냅니다.
-
Cnpk인 경우 < 1, then the specification spread is less than the process spread.
-
Cnpk를 공정에 허용되는 최소값을 나타내는 벤치마크 값과 비교합니다. 많은 업종에서 1.33을 벤치마크 값으로 사용합니다. Cnpk가 벤치마크보다 낮으면 공정을 개선할 수 있는 방법을 고려하십시오.
주의
Cnpk 지수는 공정 측정값의 "더 나쁜" 쪽, 즉 더 좋지 않은 공정 성능을 보이는 쪽에 대한 공정 능력만을 나타냅니다. 공정에 규격 한계의 양쪽에 모두 해당되는 불량 부품이 있을 경우, 공정 능력 그래프 및 두 규격 한계를 모두 벗어나는 부품의 확률을 확인하여 공정 능력을 더 완전하게 평가하십시오.