이 항목의 내용
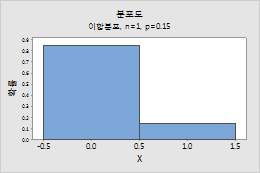
Bernoulli 분포
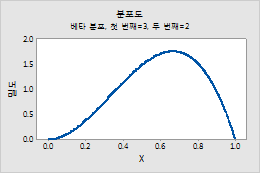
베타 분포
베타 분포에 대한 모수를 입력하려면 다음 단계를 수행하십시오.
- 첫 번째 형상 모수에 첫 번째 형상 모수에 대해 0보다 큰 숫자를 입력합니다.
- 두 번째 형상 모수에 두 번째 형상 모수에 대해 0보다 큰 숫자를 입력합니다.
예를 들어, 이 그림은 첫 번째 형상이 3, 두 번째 형상이 2인 베타 분포를 보여줍니다.
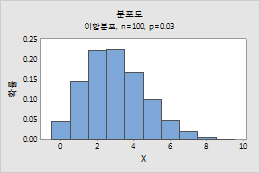
이항 분포
이항 분포에 대한 모수를 입력하려면 다음 단계를 수행하십시오.
- 시행 횟수에 표본 크기를 입력합니다.
- 사건 확률에 관심의 대상이 되는 결과가 발생하는 확률에 대해 0과 1 사이의 숫자를 입력합니다. 결과가 발생하는 것을 "사건"이라고 합니다.
예를 들어, 이 그림은 시행 횟수가 100이고 사건 확률이 0.03인 이항 분포를 보여줍니다.
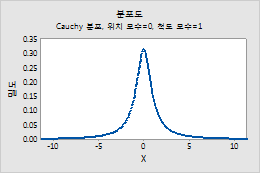
Cauchy 분포
Cauchy 분포에 대한 모수를 입력하려면 다음 단계를 수행하십시오.
- 위치에 분포의 봉우리 위치를 나타내는 값을 입력합니다.
- 척도에 분포의 산포를 나타내는 값을 입력합니다.
예를 들어, 이 그림은 위치가 0, 척도가 1인 Cauchy 분포를 보여줍니다.
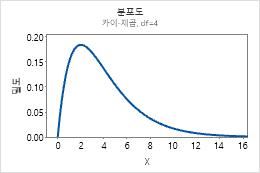
카이-제곱 분포
자유도에 카이-제곱 분포을 정의하는 자유도를 입력합니다.
예를 들어, 이 그림은 자유도가 4인 카이-제곱 분포를 보여줍니다.
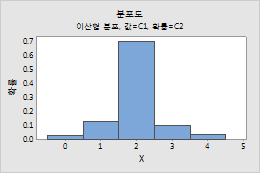
이산형 분포
이산형 분포에 대한 모수를 입력하려면 다음 단계를 수행하십시오.
- 값 위치에 분포에 포함할 값이 있는 열을 입력합니다. 일반적으로, 값은 숫자 값으로 나타내는 이산형 사건 또는 카운트입니다.
- 확률 위치에 각 값에 대한 확률이 포함된 열을 입력합니다. 확률은 0과 1 사이이고, 합이 1이어야 합니다.
이 워크시트의 값에는 분포에 포함할 카운트가 있고 확률에는 각 카운트의 확률이 있습니다.
| C1 | C2 |
|---|---|
| 값 | 확률 |
| 0 | 0.03 |
| 1 | 0.13 |
| 2 | 0.70 |
| 3 | 0.10 |
| 4 | 0.04 |
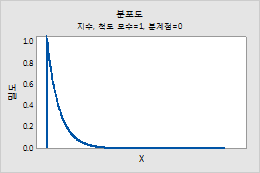
지수 분포
지수 분포에 대한 모수를 입력하려면 다음 단계를 수행하십시오.
- 척도에 척도 모수를 입력합니다. 분계점 모수가 0일 때 척도 모수는 평균과 같습니다.
- 분계점에 분포 하한을 입력합니다.
예를 들어, 이 그림은 척도가 1, 분계점이 0인 지수 분포를 보여줍니다.
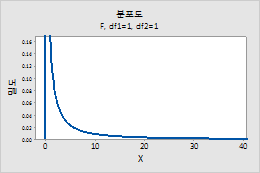
F 분포
분자 자유도 및 분모 자유도에 F-분포를 정의하기 위한 분자 및 분모 자유도를 입력합니다. 자세한 내용은 F-분포에서 확인하십시오.
예를 들어, 이 그림은 분자 자유도가 1, 분모 자유도가 1인 F-분포를 보여줍니다.
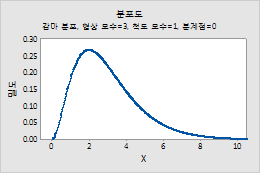
감마 분포
감마 분포에 대한 모수를 입력하려면 다음 단계를 수행하십시오.
- 형상 모수에 분포의 형상을 나타내는 값을 입력합니다.
- 척도 모수에 분포의 척도를 나타내는 값을 입력합니다.
- 분계점 모수에 분포의 하한을 입력합니다.
예를 들어, 이 그림은 형상이 3, 척도가 1, 분계점이 0인 감마 분포를 보여줍니다.
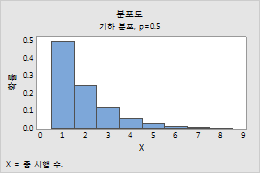
기하 분포
기하 분포에 대한 모수를 입력하려면 다음 단계를 수행하십시오.
- 사건 확률에 각 사건의 발생 확률에 대해 0과 1 사이의 숫자를 입력합니다. 결과가 발생하는 것을 "사건"이라고 합니다.
- 사용할 기하 분포의 버전을 지정하려면 옵션을 클릭하고 다음 중 하나를 선택합니다.
- 전체 시행 횟수를 모형화: 하나의 사건을 만들어내는 데 필요한 전체 시행 횟수를 모형화합니다.
- 비사건 횟수만 모형화: 하나의 사건이 발생하기 전에 발생하는 비사건 횟수를 모형화합니다.
팁
Minitab의 이후 세션에 대한 기본 설정을 변경하려면 을 선택합니다.
예를 들어, 이 그림은 총 시행 횟수를 모형화하고 사건 확률이 0.5인 기하 분포를 보여줍니다.
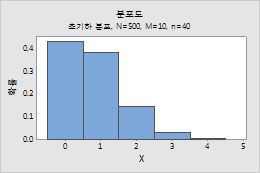
초기하 분포
초기하 분포에 대한 모수를 입력하려면 다음 단계를 수행하십시오.
- 모집단 크기(N)에 모집단의 총 항목 수(N)를 입력합니다. N이 너무 커서 알 수 없는 경우에는 이항 분포가 초기하 분포에 근사합니다.
- 모집단 내 사건 카운트(M)에 모집단의 사건 수를 나타내는 0과 N(모집단 크기) 사이의 숫자를 입력합니다.
- 표본 크기(n)에 비복원 방식으로 표본 추출되는 항목의 수를 입력합니다.
예를 들어, 이 그림은 모집단이 400, 사건 카운트가 10, 표본 크기가 40인 초기하 분포를 보여줍니다.
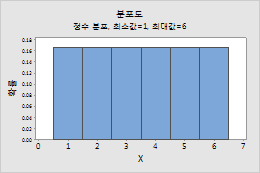
정수 분포
정수 분포에 대한 모수를 입력하려면 다음 단계를 수행하십시오.
- 최소값에 분포의 하한 끝 점을 입력합니다.
- 최대값에 분포의 상한 끝 점을 입력합니다.
예를 들어, 이 그림은 최소값이 1이고 최대값이 6인 정수 분포를 보여줍니다.
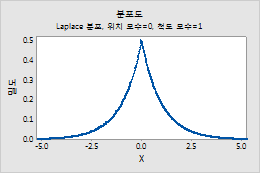
Laplace 분포
Laplace 분포에 대한 모수를 입력하려면 다음 단계를 수행하십시오.
- 위치에 분포의 봉우리 위치를 나타내는 값을 입력합니다.
- 척도에 분포의 산포를 나타내는 값을 입력합니다.
예를 들어, 이 그림은 위치가 0, 척도가 1인 Laplace 분포를 보여줍니다.
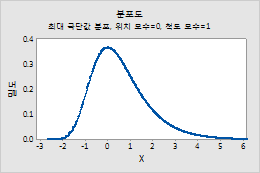
최대 극단값 분포
최대 극단값 분포에 대한 모수를 입력하려면 다음 단계를 수행하십시오. 자세한 내용은 최소 및 최대 극단값 분포에서 확인하십시오.
- 위치에 분포의 봉우리 위치를 나타내는 값을 입력합니다.
- 척도에 분포의 산포를 나타내는 값을 입력합니다.
예를 들어, 이 그림은 위치가 0, 척도가 1인 최대 극단값 분포를 보여줍니다.
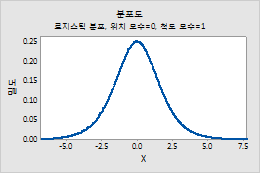
로지스틱 분포
로지스틱 분포에 대한 모수를 입력하려면 다음 단계를 수행하십시오.
- 위치에 분포의 봉우리 위치를 나타내는 값을 입력합니다.
- 척도에 분포의 산포를 나타내는 값을 입력합니다.
예를 들어, 이 그림은 위치가 0, 척도가 1인 로지스틱 분포를 보여줍니다.
로그 로지스틱 분포
로그 로지스틱 분포에 대한 모수를 입력하려면 다음 단계를 수행하십시오.
- 위치에 관련 로그 로지스틱 분포의 봉우리 위치를 나타내는 값을 입력합니다.
- 척도에 관련 로그 로지스틱 분포의 산포를 나타내는 값을 입력합니다.
- 분계점에 분포 하한을 입력합니다.
예를 들어, 이 그림은 위치가 0, 척도가 1, 분계점이 0인 로그 로지스틱 분포를 보여줍니다.
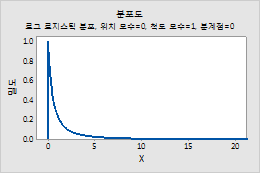
로그 정규 분포
로그 정규 분포에 대한 모수를 입력하려면 다음 단계를 수행하십시오.
- 위치에 관련된 정규 분포의 봉우리 위치를 나타내는 값을 입력합니다.
- 척도에 관련된 정규 분포의 산포를 나타내는 값을 입력합니다.
- 분계점에 분포 하한을 입력합니다.
예를 들어, 이 그림은 위치가 0, 척도가 1, 분계점이 0인 대수 정규 분포를 보여줍니다.
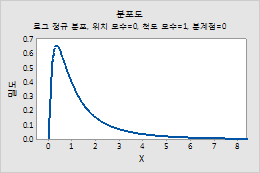
다변량 정규 분포
다변량 정규 분포에 대한 모수를 입력하려면 다음 단계를 수행하십시오.
- 평균 열에 평균 벡터가 포함되어 있는 열을 입력합니다.
- 분산-공분산 행렬에 변수의 분산과 공분산이 포함되어 있는 행렬(예: M1)을 평균 열과 같은 순서로 입력합니다.
이 예의 데이터는 상관된 변수, 정규 변수, 랜덤 변수 등 세 가지 변수에 대한 데이터입니다. 평균은 C1 열, 분산-공분산 행렬은 C2–C4 열에 있습니다.
| C1 | C2 | C3 | C4 |
|---|---|---|---|
| 2.0 | 13.0321 | 2.6544 | 0.0899 |
| 100.1 | 2.6544 | 6.5883 | 1.4438 |
| 151.3 | 0.0899 | 1.4438 | 12.2219 |
- 을 선택합니다.
- 복사될 열에 C2-C4를 입력합니다.
- 복사된 데이터 저장에서 현재 워크시트의 다음 행렬에: 아래 M1을 입력합니다.
- 확인을 클릭합니다.
이제 다변량 정규 분포에서 랜덤 데이터를 생성할 수 있습니다.
- 을 선택합니다.
- 생성할 데이터 행 수에 원하는 행 수를 입력합니다. 이 예의 경우 18을 입력합니다.
- 저장 열에 저장 열을 입력합니다. 이 예의 경우 C6-C8을 입력합니다.
- 평균 열에 평균이 포함되어 있는 열을 입력합니다. 이 예의 경우 C1을 입력합니다.
- 분산-공분산 행렬에 행렬을 입력합니다. 이 예의 경우 M1을 입력합니다.
- 확인을 클릭합니다.
팁
아래 표와 같은 표본을 얻으려면 랜덤 표본을 생성하기 전에 난수 생성기 기준값을 설정합니다. 을 선택하고 5를 입력합니다.
| C6 | C7 | C8 |
|---|---|---|
| 1.61033 | 99.192 | 148.814 |
| 0.45883 | 96.093 | 144.679 |
| −0.46745 | 101.041 | 148.936 |
| … | … | … |
음이항 분포
음이항 분포에 대한 모수를 입력하려면 다음 단계를 수행하십시오.
- 사건 확률에 각 사건의 발생 확률에 대해 0과 1 사이의 숫자를 입력합니다. 결과가 발생하는 것을 "사건"이라고 합니다.
- 필요한 사건 발생 횟수에 사건이 발생해야 하는 횟수를 나타내는 양의 정수를 입력합니다.
- 사용할 음이항 분포의 버전을 지정하려면 옵션을 클릭하고 다음 중 하나를 선택합니다.
- 전체 시행 횟수를 모형화: 지정된 횟수의 사건을 만들어내는 데 필요한 전체 시행 횟수를 모형화합니다.
- 비사건 횟수만 모형화: 지정된 횟수의 사건이 발생하기 전에 발생하는 비사건 횟수를 모형화합니다.
팁
Minitab의 이후 세션에 대한 기본 설정을 변경하려면 을 선택합니다.
예를 들어, 이 그림은 총 시행 횟수를 모형화하고 사건 확률이 0.5이며 이벤트가 5개인 음이항 분포를 보여줍니다.
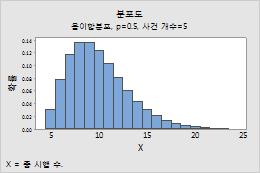
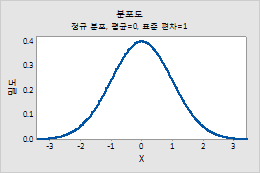
정규 분포
정규 분포에 대한 모수를 입력하려면 다음 단계를 수행하십시오.
- 평균에 분포의 중심 값을 입력합니다.
- 표준 편차에 분포의 산포 값을 입력합니다.
예를 들어, 이 그림은 평균이 0, 표준 편차가 1인 정규 분포를 보여줍니다.
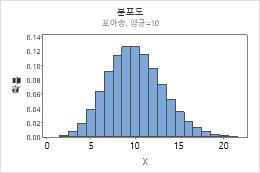
포아송 분포
평균에 평균 발생률을 입력합니다. 자세한 내용은 포아송 분포에서 확인하십시오.
예를 들어, 이 그림은 평균이 10인 포아송 분포를 보여줍니다.
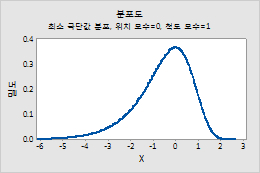
최소 극단값 분포
최소 극단값 분포에 대한 모수를 입력하려면 다음 단계를 수행하십시오. 자세한 내용은 최소 및 최대 극단값 분포에서 확인하십시오.
- 위치에 분포의 봉우리 위치를 나타내는 값을 입력합니다.
- 척도에 분포의 산포를 나타내는 값을 입력합니다.
예를 들어, 이 그림은 위치가 0, 척도가 1인 최소 극단값 분포를 보여줍니다.
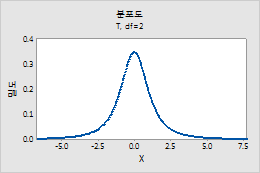
t 분포
자유도에 t-분포를 정의하기 위한 자유도를 입력합니다. 자세한 내용은 t-분포에서 확인하십시오.
예를 들어, 이 그림은 자유도가 2인 t-분포를 보여줍니다.
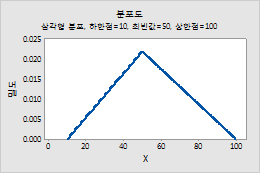
삼각형 분포
삼각형 분포에 대한 모수를 입력하려면 다음 단계를 수행하십시오.
- 하한점에 분포의 최소값을 입력합니다.
- 최빈값에 분포의 봉우리 값을 입력합니다.
- 상한점에 분포의 최대값을 입력합니다.
예를 들어, 이 그림은 하한 끝 점이 10, 최빈값이 50, 상한 끝 점이 100인 삼각형 분포를 보여줍니다.
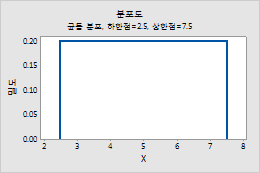
균등 분포
균등 분포에 대한 모수를 입력하려면 다음 단계를 수행하십시오.
- 하한점에 분포의 최소값을 입력합니다.
- 상한점에 분포의 최대값을 입력합니다.
예를 들어, 이 그림은 하한 끝 점이 2.5, 상한 끝 점이 7.5인 균등 분포를 보여줍니다.
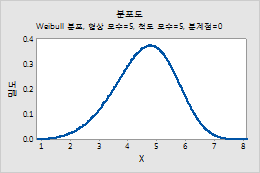
Weibull 분포
Weibull 분포에 대한 모수를 입력하려면 다음 단계를 수행하십시오.
- 형상 모수에 분포의 형상을 나타내는 값을 입력합니다.
- 척도 모수에 분포의 척도를 나타내는 값을 입력합니다.
- 분계점 모수에 분포의 하한을 입력합니다.
예를 들어, 이 그림은 위치가 5, 척도가 5, 분계점이 0인 Weibull 분포를 보여줍니다.