The standard deviation is most common measure of dispersion, or how spread out the data are from the mean. The greater the standard deviation, the greater the spread in the data.
The symbol σ (sigma) is often used to represent the standard deviation of a population, while s is used to represent the standard deviation of a sample. Variation that is random or natural to a process is often referred to as noise.
The standard deviation can be used to establish a benchmark for estimating the overall variation of a process.
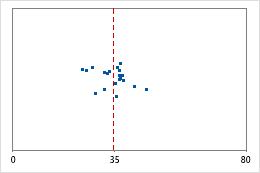
Hospital 1
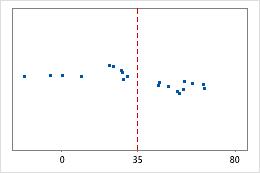
Hospital 2
Hospital discharge times
Consider the following example. Administrators track the discharge time for patients treated in the emergency departments of two hospitals. Although the average discharge times are about the same (35 minutes), the standard deviations are significantly different. The standard deviation for hospital 1 is about 6. On average, a patient's discharge time deviates from the mean (dashed line) by about 6 minutes. The standard deviation for hospital 2 is about 20. On average, a patient's discharge time deviates from the mean (dashed line) by about 20 minutes.