ステップ1:検定平均と参照平均が同等かどうかを判定する
信頼区間を同等性限界と比較します。信頼区間が同等性限界内に完全に収まっている場合、検定母集団平均は参照母集団平均と同等であると主張できます。信頼区間の一部が同等性限界から外れている場合、同等だとの主張はできません。
差: 平均(割引) - 平均(元の値)
| 差 | 標準誤差 | 95% 同等の CI | 同等性区間 |
|---|---|---|---|
| -0.12122 | 0.20324 | (-0.483449, 0.241005) | (-0.5, 0.5) |
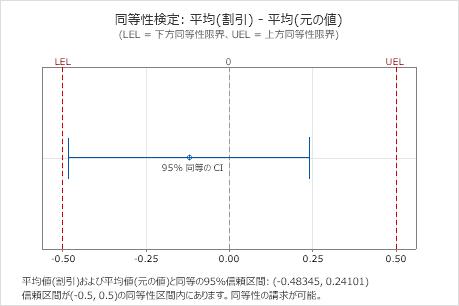
主要な結果: 95% CI、同等性区間
この結果で、95%信頼区間は下側同等性限界(LEL)と上側同等性限界(UEL)によって同等定義される区間に完全に含まれています。したがって、検定平均値は参照平均値と同等であると結論付けることができます。
注
p値を使用して同等性検定を評価することもできます。同等性を実証するには、両方の帰無仮説のp値がαよりも小さくなければなりません。
ステップ2:データに問題があるか確認する
歪みや外れ値などのデータの問題は、結果に悪影響を及ぼす可能性があります。グラフを使用して歪みを探し(データの広がりを調べて)、潜在的な外れ値を識別します。
データに歪みがあるかどうか判定する
データが歪んでいる場合、ほとんどのデータがグラフの上下に向いていることになります。箱ひげ図やヒストグラムでは歪みを識別するのが最も簡単であるケースが多いです。
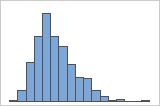
右方向の歪み
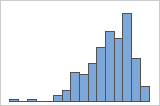
左方向の歪み
例えば、右方向に歪んだヒストグラムは、給与データを示します。多数の従業員の給与は比較的少額ですが、少数の給与は多額です。左方向に歪んだヒストグラムは、故障率を示します。少数のアイテムは早く失敗する一方で、多数のアイテムは後で失敗します。
データが大きく歪んでいると、サンプルサイズが小さい場合(20未満)に検定結果の妥当性が影響を受けます。データが大きく歪んでいて、サンプルサイズが小さい場合はサンプルサイズを増やすことを検討します。
外れ値を特定
外れ値は、他の大部分のデータから遠くに離れているデータ点のことで、結果に大きな影響を及ぼします。外れ値は、箱ひげ図で容易に識別できます。
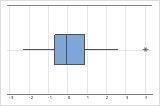
箱ひげ図では、アスタリスク(*)によって外れ値が識別されます。
外れ値がある場合は、その原因を特定してください。データ入力や測定の誤差を修正します。特定の原因に関連するデータを削除し、分析を再度実行することを検討してください。特殊原因の詳細は、管理図を使用した一般原因による変動と特殊原因による変動の検出をご覧ください。
データの広がりを比較する(オプション)
注
等分散性かどうかを正式に確認するには、2サンプルの分散の検定を使用します。
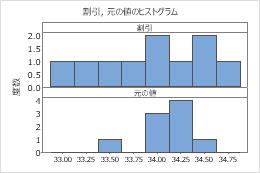
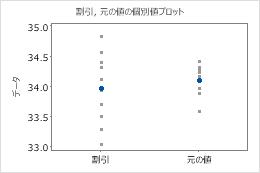
これらのグラフにおいて、データには歪みがあるようには見えず、外れ値もありません。
データの広がりは、検定グループと参照グループ、同じには見えません。従って、検定で等分散だと仮定すべきではありません。