注
このコマンドは、予測分析モジュールで使用できます。モジュールをアクティブにする方法については、ここをクリックしてください。
Random Forests®モデルは、分類と回帰の問題を解決するためのアプローチです。このアプローチは、単一の分類や回帰ツリーよりも、予測変数の変化に対してより正確で堅牢です。プロセスの広範な一般的な説明として、 Minitab統計ソフトウェアがブートストラップサンプルから単一ツリーを構築します。Minitabは、各ノードで最適な分岐を評価するために、予測変数の総数のうち、より小さな予測変数をランダムに選択します。Minitabでは、このプロセスを繰り返して、多くのツリーを成長させます。回帰の場合、モデルからの予測は、個々のすべてのツリーからの予測の平均です。
回帰ツリーを構築するために、アルゴリズムは最小二乗基準を使用してノードの不純物を測定します。デスクトップ アプリケーションの場合、各ツリーは、ノードを分割できなくなるか、ノードが内部ノードを分割するケースの最小数に達するまで成長します。最小ケース数は、 分析のオプションです。WEBアプリで分析により、各ツリーには4,000個のターミナルノードの制限があるという制約が追加されます。回帰ツリーの構築に関する詳細はにおけるノード分岐方法 CART® 回帰を参照してください。Random Forests®に固有の詳細を以下に示します。
ブートストラップサンプル
各ツリーを構築するために、アルゴリズムは、完全データセットから置換したランダムサンプル(ブートストラップサンプル)を選択します。通常、各ブートストラップサンプルは元のデータセットとは異なり、異なる数の固有の行が含まれている可能性があります。アウトオブバッグ検証のみを使用する場合、ブートストラップサンプルのデフォルトサイズは元のデータセットのサイズです。サンプルをトレーニングセットとテストセットに分割した場合、ブートストラップサンプルのデフォルトサイズはトレーニングセットのサイズと同じです。いずれの場合も、ブートストラップサンプルがデフォルトサイズよりも小さいことを指定するオプションがあります。ブートストラップサンプルには、平均して約2/3のデータ行の含まれています。ブートストラップサンプルにないデータの一意の行は、検証用のアウトオブバッグデータです。
予測変数のランダムな選択
ツリー内の各ノードで、アルゴリズムは予測変数の総数のサブセットをランダムに選択し、 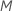 、分岐として評価します。デフォルトでは、アルゴリズムは を選択
、分岐として評価します。デフォルトでは、アルゴリズムは を選択 各ノードで評価する予測変数。評価する予測変数の数を 1 からまでで選択するオプションがあります
各ノードで評価する予測変数。評価する予測変数の数を 1 からまでで選択するオプションがあります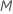 .を選択した場合
.を選択した場合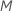 予測変数を使用すると、アルゴリズムはすべてのノードに対してそれぞれ予測変数を評価し、その結果、「ブートストラップ
フォレスト」という名前で分析を行います。
予測変数を使用すると、アルゴリズムはすべてのノードに対してそれぞれ予測変数を評価し、その結果、「ブートストラップ
フォレスト」という名前で分析を行います。
各ノードで予測変数のサブセットを使用する分析では、評価された予測変数は通常、各ノードで異なります。様々な予測変数を評価すると、フォレスト内のツリーの相互の相関関係が弱くなります。相関の弱いツリーは、より多くのツリーを構築するにつれて予測が改善される学習効果が遅くなります。
アウトオブバッグデータを使用した検証
データの一意の行が特定ツリーのツリー構築プロセスに含まれていない場合は、アウトオブバッグデータです。モデルの性能測定の計算は、アウトオブバッグデータを使用します。詳細については、Random Forests® 回帰におけるモデルの要約の方法と計算式を参照してください。
フォレスト内の特定のツリーに対して、アウトオブバッグデータの行に対する予測は、単一ツリーに由来します。アウトオブバッグデータの行の予測は、個々のツリーからの予測の平均となります。
トレーニングセット内の行の予測
フォレスト内の各ツリーは、トレーニングセット内の各行について個別の予測を行います。トレーニングセット内の行の予測値は、フォレスト内のすべてのツリーからの予測値の平均です。