自由度(DF)
合計自由度(DF)は、データに含まれる情報量のことです。分析では、その情報を使用して、未知の母集団のパラメータ値を推定します。合計自由度は、サンプルに含まれる観測値の数によって決定されます。項の自由度は、その項が使う情報量を示します。サンプルサイズを大きくすると、母集団に関して提供される情報が増え、合計自由度が高くなります。モデルに含める項の数を増やすと情報量が増え、パラメータ推定値の変動性を推定するのに使える自由度が低くなります。
- 曲面性の自由度
- 計画に中心点がある場合、1つの自由度は曲面性の検定に使用されます。中心点に対する項がモデルに含まれている場合、曲面性の行はモデルの一部です。中心点に対する項がモデルに含まれていない場合、曲面性の行はモデルに含まれる項を検定するのに使用される誤差の一部です。
- 誤差の自由度
- 2つの条件が一致すると、Minitabでは曲面性のではない誤差の自由度が分割されます。1つ目の条件は、現在のモデルには含まれていない、データと適合できる項があることです。たとえば、計画にはブロックはあるけど、そのブロックはモデルに含まれていない場合です。中心点に対する項は常に曲面性の項になるので、中心点に対する項は現在のモデルに含まれていないデータと適合できる項にはカウントされません。
調整平方和
調整平方和は、モデル内の異なる成分の変動の測度です。モデル内の予測変数の次数は、調整平方和の計算に影響を及ぼしません。分散分析表では、調整平方和は、異なる要因による変動を説明する成分に分けられます。
- 調整平方和モデル
- モデルの調整平方和は、応答の平均のみを使用するモデルと比較した場合の、モデルに含まれる全体平方和と誤差平方和の差です。モデルに含まれる項のすべての逐次平方和の合計です。
- 項のグループの調整平方和
- モデルに含まれる項のグループに対する調整平方和は、グループ内のすべての項に対する逐次平方和の合計です。項のグループにより説明される応答データの変動量を定量化します。
- 調整平方和項
- 項の調整平方和は、他の項だけを持つモデルと比較した場合のモデル平方和の増加を表します。モデルに含まれる各項によって説明される応答データの変動量を定量化します。
- 調整誤差平方和
- 調整誤差平方和は残差の平方和です。予測変数では説明できないデータの変動を定量化します。
- 曲面性調整平方和
- 曲面性の調整平方和は、モデル平方和または誤差平方和の一部です。中心点の項によって説明される応答データの変動量を定量化します。この変動量は1つ以上の2次項の組み合わせ効果を示しています。
- 純粋誤差の調整平方和
- 調整純粋誤差平方和は誤差平方和の一部です。純粋誤差平方和は、純粋誤差の自由度があるときに存在します。詳細は、自由度(DF)セクションを参照してください。同じ値の因子、ブロック、共変量を持つ観測値におけるデータの変動量を定量化します。
- 調整全体平方和
- 全体調整平方和は、モデルの平方和と誤差の平方和の合計です。データの変動全体を定量化します。
解釈
Minitabは調整平方和を使用して分散分析表のp値を計算します。また、平方和を使用してR2の統計量も計算します。通常は、平方和ではなく、p値とR2統計量を解釈します。
調整平均平方
調整平均平方は、項やモデルによってどれだけの変動を説明できるかを測定するものです。このとき、その他のすべての項は、入力された順序にかかわらずモデル内に含まれると仮定します。調整平方和と異なり、調整平均平方では、自由度が考慮されます。
調整平均平方誤差(MSEまたはs2)は適合値からの分散です。
解釈
Minitabは調整平均平方を使用して分散分析表のp値を計算します。また、調整平均平方を使用して調整済みR2の統計量も計算します。通常は、調整平均平方ではなく、p値と調整済みR2の統計量を解釈します。
逐次平方和
逐次平方和は、モデル内の異なる成分の変動の測度です。調整平方和と異なり、逐次平方和は項がモデルに追加された順序に依存します。分散分析表では、逐次平方和は、異なる要因による変動を説明する成分に分けられます。
- 逐次平方和モデル
- モデルに対する逐次平方和は、全体平方和と誤差平方和の差です。モデルに含まれる項のすべての平方和の合計です。
- 項のグループの逐次平方和
- モデルに含まれる項のグループに対する逐次平方和は、グループ内のすべての項に対する平方和の合計です。項のグループにより説明される応答データの変動量を定量化します。
- 逐次平方和項
- 項の逐次平方和は、分散分析表のモデル上に他の項だけを持つモデルと比較した場合のモデル平方和の増加を表します。上位にある項のみを持つモデルに項を追加した場合のモデル平方和の増加を定量化します。
- 逐次誤差平方和
- 逐次誤差平方和は残差の平方和です。予測変数では説明できないデータの変動を定量化します。
- 曲面性の逐次平方和
- 曲面性の逐次平方和は、モデル平方和または誤差平方和の一部です。中心点の項によって説明される応答データの変動量を定量化します。この変動量は1つ以上の2次項の組み合わせ効果を示しています。
- 逐次平方和純粋誤差
- 逐次純粋誤差平方和は誤差平方和の一部です。純粋誤差平方和は、純粋誤差の自由度があるときに存在します。詳細は、自由度(DF)セクションを参照してください。同じ値の因子、ブロック、共変量を持つ観測値におけるデータの変動量を定量化します。
- 全体逐次平方和
- 全体逐次平方和は、モデルの平方和と誤差の平方和の合計です。データの変動全体を定量化します。
解釈
計画分析時にp値を計算するためには逐次平方和は使用しませんが、回帰モデルの適合または一般線形モデルの適合を使用するときに逐次平方和を使用できます。通常、調整平方和を基に、p値とR2統計量を解釈します。
寄与度
寄与度は、分散分析表の各要因が合計逐次平方和(Seq SS)に寄与する割合を示しています。
解釈
割合が高いほど、要因がより応答の変動の原因になっていることを示しています。
F値
F値は分散分析表の各検定に表示されます。
- モデルのF値
- F値は、共変量、ブロック、因子項、曲面性を含め、モデルに含まれる項が応答と関係があるかどうかを判断するために使用する検定統計量です。
- グループとしての共変量のF値
- F値は、いずれかの共変量が応答に同時に関連付けられているかを判断する検定統計量です。
- 個別共変量のF値
- F値は、個別共変量が応答に関連付けられているかを判断する検定統計量です。
- ブロックのF値
- F値は、ブロック内のさまざまな条件が応答と関連付けられているかを判断する検定統計量です。
- 因子項の種類のF値
- F値は、項のグループが応答に関連付けられているかを判断する検定統計量です。項グループは例えば、線形効果や二元交互作用などです。
- 個々の項のF値
- F値は項が応答に関連付けられているかを判断する検定統計量です。
- 曲面性のF値
- F値は、いずれかの因子が応答と曲線的な関係にないかを判断する検定統計量です。
- 不適合度検定におけるF値
- F値は、モデルが実験に因子が含まれる欠損している項かを判断する検定統計量です。ステップワイズ手順でモデルからブロックまたは共変量が削除される場合、不適合検定には、これらの項も含まれます。
解釈
F値を使用してMinitabで計算されるp値に基づいて、検定の統計的有意性に関する決定を下すことができます。p値は帰無仮説を棄却するための証拠を測定する確率です。確率が低いほど、帰無仮説を棄却する強力な証拠となります。F値が十分に大きい場合、統計的有意性を示します。
F値から帰無仮説を棄却するかどうかを判断するには、F値を棄却限界値と比較します。Minitabで棄却限界値を計算することも、ほとんどの統計に関する書籍に掲載されているF分布表で棄却値を見つけることもできます。Minitabでの棄却限界値の計算方法については、 逆累積分布関数(ICDF)の使用に進み、「逆累積分布関数で棄却限界値を計算する」をクリックします。
p値~モデル
p値は帰無仮説を棄却するための証拠を測定する確率です。確率が低いほど、帰無仮説を棄却する強力な証拠となります。
解釈
モデルによって応答の変動を説明できるかどうかを判断するには、モデルのp値と有意水準を比較して帰無仮説を評価します。モデルの帰無仮説は、モデルでは応答の変動は説明できないという仮定です。通常は、有意水準(αまたはアルファとも呼ばれる)として0.05が適切です。0.05の有意水準は、実際にはモデルによって応答の変動は説明できないにも関わらず、説明できると結論付ける可能性が5%であることを示しています。
- p値 ≤ α:モデルにより応答での変動が説明されます
- p値が有意水準以下の場合は、そのモデルにより応答での変動が説明されると結論付けます。
- p値 > α:応答での変動はモデルによって説明されると結論付けるだけの十分な証拠はありません
- p値が有意水準より大きい場合、そのモデルにより応答での変動が説明されると結論することはできません。新しいモデルを適合することができます。
p値~共変量
p値は帰無仮説を棄却するための証拠を測定する確率です。確率が低いほど、帰無仮説を棄却する強力な証拠となります。
実験計画において、共変量は測定可能であるが制御が困難な変数を説明します。たとえば、病院ネットワークの品質チームは、膝関節置換手術で入院した患者の入院日数を研究する実験を計画しました。この実験では、チームは術前指示のフォーマットなどの因子はコントロール可能です。偏りを避けるため、チームはコントロールできない共変量、たとえば患者の年齢など、にデータを記録します。
解釈
応答と共変量の間の関係が統計的に有意かどうか判断するには、共変量のp値と有意水準を比較して帰無仮説を評価します。この帰無仮説は、共変量の係数は0に等しく、共変量と応答に関連性がないという仮定です。
通常は、有意水準(αまたはアルファとも呼ばれる)として0.05が適切です。0.05の有意水準は、実際には実行における異なる条件は応答に影響しないにもかかわらず、影響すると結論付ける可能性が5%であることを示しています。
共変量を持つモデルに対する項の統計的な有意性を評価する場合、分散拡大係数(VIF)を検討してください。
- p値 ≤ α: 関連性は統計的に有意です
- p値が有意水準以下の場合は、応答変数と共変量の関連性は統計的に有意であると結論付けることができます。
- p値 > α: その関連性は統計的に有意ではありません
- p値が有意水準より大きい場合は、応答変数と共変量の関連性は統計的に有意であると結論付けることができません。その共変量なしでモデルを適合してみてください。
注
ほとんどの要因計画においてすべてのVIF値は1で、これは統計的有意性の決定を簡単にします。モデルの共変量の包含や、データ収集時の不備のある実行は、VIF値が大きくなる2つの一般的な理由で、これにより統計的有意性の解釈が複雑化します。VIF値は係数表に含まれています。詳細については、要因計画の分析の係数表を参照し、VIFをクリックします。
p値~ブロック
p値は帰無仮説を棄却するための証拠を測定する確率です。確率が低いほど、帰無仮説を棄却する強力な証拠となります。
ブロックは、異なる条件下で実験が実行された場合に起こりうる差を説明します。たとえば、ある技師が溶接を分析する実験を計画し、すべてのデータを一日では収集できないとします。溶接の質は、相対湿度などの技師では制御できない、日々変わる複数の不確定要素に影響されます。これらの制御できない変数を説明するため、各日で行われた実験を個別のブロックにグループ化します。ブロックは、制御できない変数の効果とエンジニアが分析したい因子の効果が混同されないよう、制御できない変数からの変動性を説明します。Minitabで実行をブロックに割り当てる方法についての詳細は、ブロックとはを参照してください。
解釈
実行間で異なる条件により応答が変化するかを判断するには、ブロックのp値と有意水準を比較して帰無仮説を評価します。この帰無仮説は、異なる条件によって応答は変化しないという仮定です。
通常は、有意水準(αまたはアルファとも呼ばれる)として0.05が適切です。0.05の有意水準は、実際には実行における異なる条件は応答に影響しないにもかかわらず、影響すると結論付ける可能性が5%であることを示しています。
- p値 ≤ α: 条件が異なることで応答が変化します
- p値が有意水準以下の場合は、条件が異なることによって応答が変化すると結論付けます。
- p値 > α: 条件が異なることで応答が変化すると結論付けるだけの十分な証拠はありません
- p値が有意水準より大きい場合は、条件が異なることによって応答が変化すると結論付けることはできません。ブロックなしでモデルを適合してみてください。
p値~因子、交互作用、項グループ
p値は帰無仮説を棄却するための証拠を測定する確率です。確率が低いほど、帰無仮説を棄却する強力な証拠となります。
解釈
- 共変量が有意な場合は、共変量の係数は0ではないと結論付けることができます。
- カテゴリ因子が有意な場合は、複数の水準に渡るすべての標準偏差が等しいとは限らないと結論付けることができます。
- 交互作用項が有意な場合は、因子と応答の間の関係がその項の他の因子に依存すると結論付けることができます。
項グループの検定項グループの検定
項のグループが統計的に有意な場合、グループ内の少なくとも1つの項が応答に対して影響力を持つと結論付けることができます。モデルに残す項を統計的有意性によって決定する場合、通常は一度に項のグループ全体を取り除くことはしません。個々の項の統計的有意性は、モデルに含まれる項によって変わることがあるためです。
分散分析
| 要因 | 自由度 | 調整平方和 | 調整平均平方 | F値 | p値 |
|---|---|---|---|---|---|
| モデル | 10 | 447.766 | 44.777 | 17.61 | 0.003 |
| 線形 | 4 | 428.937 | 107.234 | 42.18 | 0.000 |
| 材料 | 1 | 181.151 | 181.151 | 71.25 | 0.000 |
| 射出圧力 | 1 | 112.648 | 112.648 | 44.31 | 0.001 |
| 射出温度 | 1 | 73.725 | 73.725 | 29.00 | 0.003 |
| 冷却温度 | 1 | 61.412 | 61.412 | 24.15 | 0.004 |
| 2元交互作用 | 6 | 18.828 | 3.138 | 1.23 | 0.418 |
| 材料*射出圧力 | 1 | 0.342 | 0.342 | 0.13 | 0.729 |
| 材料*射出温度 | 1 | 0.778 | 0.778 | 0.31 | 0.604 |
| 材料*冷却温度 | 1 | 4.565 | 4.565 | 1.80 | 0.238 |
| 射出圧力*射出温度 | 1 | 0.002 | 0.002 | 0.00 | 0.978 |
| 射出圧力*冷却温度 | 1 | 0.039 | 0.039 | 0.02 | 0.906 |
| 射出温度*冷却温度 | 1 | 13.101 | 13.101 | 5.15 | 0.072 |
| 誤差 | 5 | 12.712 | 2.542 | ||
| 合計 | 15 | 460.478 |
このモデルにおいては、二元交互作用は水準0.05において統計的に有意ではありません。また、すべての二元交互作用の検定も統計的に有意ではありません。
分散分析
| 要因 | 自由度 | 調整平方和 | 調整平均平方 | F値 | p値 |
|---|---|---|---|---|---|
| モデル | 5 | 442.04 | 88.408 | 47.95 | 0.000 |
| 線形 | 4 | 428.94 | 107.234 | 58.16 | 0.000 |
| 材料 | 1 | 181.15 | 181.151 | 98.24 | 0.000 |
| 射出圧力 | 1 | 112.65 | 112.648 | 61.09 | 0.000 |
| 射出温度 | 1 | 73.73 | 73.725 | 39.98 | 0.000 |
| 冷却温度 | 1 | 61.41 | 61.412 | 33.31 | 0.000 |
| 2元交互作用 | 1 | 13.10 | 13.101 | 7.11 | 0.024 |
| 射出温度*冷却温度 | 1 | 13.10 | 13.101 | 7.11 | 0.024 |
| 誤差 | 10 | 18.44 | 1.844 | ||
| 合計 | 15 | 460.48 |
最大のp値の二元交互作用から初めて、モデルから項を1つずつ除外して縮約する場合、最後の二元交互作用は水準0.05において統計的に有意です。
p値~曲面性
p値は帰無仮説を棄却するための証拠を測定する確率です。確率が低いほど、帰無仮説を棄却する強力な証拠となります。
計画に中心点がある場合、Minitabでは曲面性の検定が行われます。モデル項と応答の関係が線形である場合、検定では平均の期待値と比較して中心点にある応答の適合平均が使用されます。曲面性をグラフ化するには、要因計画プロットを使用します。
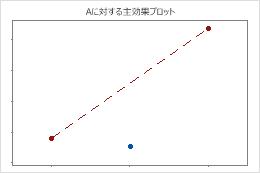
中心点は頂点の平均と交わる線から遠く離れており、曲線関係にあることを示しています。曲面性の統計的有意性をp値を用いて確認します。
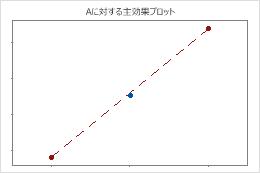
中心点は頂点の平均と交わる線の近くに配置されています。曲面性はおそらく統計的に有意ではありません。
解釈
少なくとも1つの因子が応答と曲線関係にあるかどうかを判断するには、曲面性のp値を有意水準と比較して帰無仮説を評価します。この帰無仮説は、因子と応答のすべての関係が線形であるという仮定です。
通常は、有意水準(αまたはアルファとも呼ばれる)として0.05が適切です。0.05の有意水準は、実際には実行における異なる条件は応答に影響しないにもかかわらず、影響すると結論付ける可能性が5%であることを示しています。
- p値 ≤ α: 少なくとも1つの因子が応答と曲線関係にあります
- p値が有意水準以下の場合は、少なくとも1つの因子が応答と曲線関係にあると結論付けます。曲面性をモデル化するために、計画に軸点を追加してみてください。
- p値 > α: 因子が応答と曲線関係にあると結論付けるだけの十分な証拠はありません
- p値が有意水準より大きい場合、どの因子も応答と曲線関係にあると結論付けることは出来ません。曲面性がモデルの一部である場合、曲面性が誤差の一部になるように中心点の項を抜いた状態でモデルを再適合してみてください。
注
通常、曲面性が統計的に有意でない場合は中心点の項を取り除きます。中心点をモデルに残しておくと、Minitabは要因計画で適合できない曲面性がモデルに含まれているとみなします。不適切な適合のため、等高線プロット、曲面プロット、重ね合わせ等高線プロットは利用できません。また、Minitabは応答の最適化機能による計画内に含まれる因子水準間の補完は行いません。モデルの使用方法に関する詳細は、保存モデルの概要を参照してください。
p値~不適合度
p値は帰無仮説を棄却するための証拠を測定する確率です。確率が低いほど、帰無仮説を棄却する強力な証拠となります。
解釈
- p値 ≤ α:その不適合は統計的に有意です
- p値が有意水準以下の場合は、そのモデルでは関係が正しく指定されないと結論付けます。モデルを改善するには、項を追加するか、またはデータを変換する必要があります。
- p値 > α:その不適合は統計的に有意ではありません
-
p値が有意水準より大きい場合は、検定で何の不適合も検出されません。