目的の方法または計算式を選択してください。
プロットされた点
サブグループデータ
データがサブグループにある場合、 T2 は次のように計算されます。
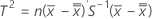
ここで、
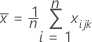
 は の平均ベクトルである。
は の平均ベクトルである。 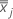 ( xjk 値の平均) は、次のように計算されます。
( xjk 値の平均) は、次のように計算されます。
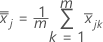
S = サンプル共分散行列
サンプル共分散行列 Sは、次のように計算されます。

ここで、
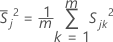
ここで、
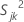 では、 k番目のサンプルにおける j番目の 特性のサンプル分散は、次のように計算されます。
では、 k番目のサンプルにおける j番目の 特性のサンプル分散は、次のように計算されます。
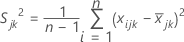
ここで、
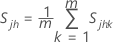
ここで、
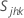 、共分散、=
、共分散、=
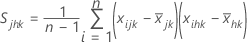
S行列の平均は、工程が正常に管理されているときの分散の不偏推定値です。 n は p より大きくなければならず、サンプル共分散行列が特異にならないように、変数間に強い相関があってはなりません。
データがサブグループにある場合、管理図には、個々の観測値であるサブグループの欠損値が表示されます。
個々の観測値の場合
データが個々の観測値の場合、 T2 は次のように計算されます。
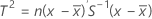
ここで、
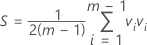
ここで、

表記
| 用語 | 説明 |
|---|---|
| n | サンプルサイズ |
 | サンプル平均ベクトル |
| xijk | k番目の 試料における j番目の特性に関する i番目の 観察 |
| m | サンプル数 |
T2の計算例
管理図にT2統計量をプロットします。プロットされた点が管理限界を超える場合、工程はこの点で管理外になります。Minitabの計算については、表とサンプルの式を参考にしてください。
次のデータは、洗浄液の開発処理から発生します。クエン酸ナトリウムとグリセリンの量は、洗浄液の効能に影響を与えます。
| サブグループ平均 | 分散と共分散 | T2統計量 | ||||
| サブグループ | クエン酸ナトリウム(X1) | グリセリン(X2) | S 1 2 | S2 2 | S 1 2 k | T2 |
| 1 | 125 | 025 | 7292 | 8692 | 5791 | 5708 |
| 2 | 625 | 4 | 2292 | 2333 | 3333 | 1429 |
| 3 | 4 | 875 | 1467 | 0625 | 8000 | 9528 |
| 4 | 2 | 2 | 2933 | 7600 | 6667 | 8073 |
| 5 | 25 | 225 | 2500 | 2692 | 7917 | 7548 |
| 6 | 4 | 45 | 6667 | 9567 | 3333 | 2711 |
| 7 | 275 | 025 | 3692 | 4692 | 7108 | 7785 |
| 8 | 6 | 65 | 4333 | 7700 | 6933 | 6183 |
| 9 | 625 | 325 | 7892 | 5558 | 1325 | 3592 |
| 10 | 3 | 5 | 2867 | 9467 | 2600 | 4942 |
| 11 | 25 | 5 | 1767 | 1200 | 9000 | 3279 |
| 12 | 1 | 625 | 1467 | 1692 | 4033 | 0277 |
| 平均 | 7875 | 2333 | 7931 | 9318 | 3003 | |
- X1とX2の変数ごとにサブグループ平均を計算します。この場合、サブグループごとに4つのサンプルがあります。
- 個々の観測値がある場合、すべての計算でサブグループ平均の代わりにそれらの観測値が使用されます。
- S1 2とS2 2のサブグループ分散を計算します。
- S1 2 kのサブグループ共分散を計算します。
- サブグループ平均の平均、サブグループ分散の平均、共分散の平均を計算します。
- 共分散行列のサンプルSと平均ベクトルを指定します。
- 以下で与えられるCT2を計算します。
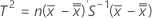
T2管理図にT2をプロットして、管理限界と比較して個々の点が管理外かどうかを判断します。
中心線
T2管理図の中心線はKXです。KとXの計算は、最大サンプルサイズ、およびMinitabでデータから共分散行列が推定されるかどうかによって異なります。
サブグループデータ
サブグループデータの場合、KXは次のように計算されます。
- 与えられた共分散行列
-


- 推定される共分散行列
-


個々の観測値
データが個々の観測値の場合、KXは次のように計算されます。
- 与えられた共分散行列
-
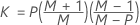
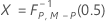
- 推定される共分散行列
-
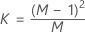
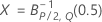
ここで、
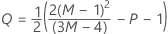
表記
| 用語 | 説明 |
|---|---|
| P | 変数の数 |
| M | サブグループ数 |
| N | サンプルサイズ |
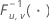 | 分子の自由度がu、分母の自由度がvの逆累積F分布 |
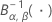 | 第1形状パラメータがα、第2形状パラメータがβの逆累積ベータ分布 |
管理限界
サブグループデータ
パラメータを指定しない場合の上側管理限界:
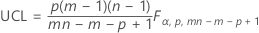
パラメータを指定した場合の上側管理限界:
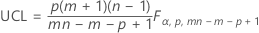
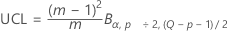
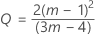
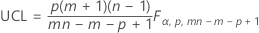
表記
| 用語 | 説明 |
|---|---|
| α | 固定値0.00134989803156746 |
| p | 特性の数 |
| m |
サブグループデータでパラメータ推定値を指定しない場合、mはサンプルの数です。パラメータ推定値を指定した場合、mは共分散行列の作成に使用されたサンプルの数です。 個々のデータの場合、mは観測値の数です。 |
| n | 各サンプルのサイズ |
| F | F分布が使用されていることを示します。 |
| B | ベータ分布が使用されていることを示します。 |
分解されたT2統計量
分解されたT2統計量:
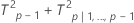
ここで、

ここで、
xi(p − 1)は分解された平均ベクトル
SxxはSの(p – 1) × (p – 1)主小行列
T2p|1,..., p−1は、フェーズ、およびサブグループまたは個々の観測値を持つかどうかによって異なる近似値です。
データのフェーズ1は次のサブグループです。
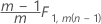
データのフェーズ2は次のサブグループです。
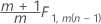
個々の観測値のフェーズ1:
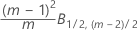
個々の観測値のフェーズ2:
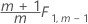
パラメータ推定値を指定しない場合はフェーズ1の管理限界が計算され、指定する場合はフェーズ2の管理限界が計算されます。
分解されたT2統計量の詳細は、Masonらの2を参照してください。
表記
| 用語 | 説明 |
|---|---|
| m | サンプル数 |
| F | F分布が使用されていることを示します |
| B | ベータ分布が使用されていることを示します |
Box-Coxの方法と計算式
Box-coxの計算式
Box-Cox変換を使用する場合、Minitabでは、次の計算式に従って元のデータ値(Yi)を変換します。


ここでλは、変換のパラメータです。次にMinitabでは、変換されたデータ値(Wi)の管理図を作成します。Minitabでλの最適値を選択する方法については、Box-Cox変換の方法と計算式を参照してください。
共通のλ値
| λ | 変換 |
|---|---|
| 2 | 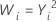 |
| 0.5 |  |
| 0 |  |
| −0.5 | 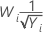 |
| −1 | 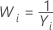 |