Calculating power
Calculating power
- Power
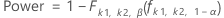
- Degrees of freedom for error
-
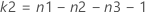
- Non-centrality parameter
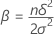
Notation
| Term | Description |
|---|---|
| k1 | k – 1 |
| k | number of levels for the factor with the largest number of levels |
| α | significance level |
| f k1, k2, s | inverse CDF at s for a central F distribution with k1 and k2 degrees of freedom |
| k2 | degrees of freedom for error |
| n1 | total number of experimental runs |
| n2 | unblocked design: 0 blocked design: number of blocks – 1 |
| n3 | sum of degrees of freedom for all factorial terms in the model |
| β | non-centrality parameter |
| n | sample size at each level of the factor with the largest number of levels |
| δ | maximum difference |
| σ | standard deviation |
Calculating replicates and maximum difference
If you provide values for power and maximum difference, Minitab calculates the number of replicates. If you provide values for power and replicates, Minitab calculates the maximum difference. Minitab reports the results for the factor with the largest number of levels to provide conservative results.
For these two cases, Minitab uses an iterative algorithm with the power equation. At each iteration, Minitab evaluates the power for a value that you specified for the number of replicates or the value of the maximum difference. For the value that you did not specify, Minitab selects a value to evaluate. The algorithm stops when the value that you specify and the value that Minitab selects achieve the target power.
Target power and actual power
When you provide a power value, Minitab may find that no integer number of replicates yields your target power. In such cases, Minitab displays the target value for power alongside the actual power attainable given your specifications. The actual power is a value nearest to, yet greater than, the target power.