In This Topic
Squared distance
Squared Mahalanobis distance - General form
The squared distance (also called the Mahalanobis distance) of observation x to the center (mean) of group t for linear discriminant is given by the following general form:

Squared Mahalanobis distance - Quadratic function
The squared Mahalanobis distance from x to group t for the quadratic discriminant function is calculated as follows:

Generalized squared distance - Linear function
The generalized squared distance from x to group t for the linear discriminant function is calculated as follows:
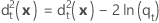
Generalized squared distance - Quadratic function
The generalized squared distance from x to group t for the quadratic discriminant function is calculated as follows:

Posterior probability
The posterior probability for x belonging to group t is calculated as follows:
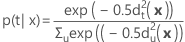
Linear discriminant scores
The linear discriminant scores are calculated as follows:

Notation
| Term | Description |
|---|---|
| x | column vector of length p containing the values of the predictors for this observation (this column vector is stored as one row) |
| p | number of predictors |
| n | total number of observations |
| t | group subscript |
| nt | number of observations in group t |
| qt | the prior probability of group t, which equals nt/n |
| Sp | pooled covariance matrix for linear discriminant analysis |
| Si | covariance matrix of group i for quadratic discriminant analysis |
| mt | column vector of length p containing the means of the predictors calculated from the data in group t |
| St | covariance matrix of group t |
| |St| | determinant of St |
Linear discriminant function

For a given x, this rule allocates x to the group with largest linear discriminant function.
Notation
| Term | Description |
|---|---|
| x | column vector of length p containing the values of the predictors for this observation (this column vector is stored as one row) |
| mi | column vector of length p containing the means of the predictors calculated from the data in group i |
| Sp | pooled covariance matrix |
| ln pi | natural log of the prior probability for group i |
Generalized squared distance

Notation
| Term | Description |
|---|---|
| x | column vector of length p containing the values of the predictors for this observation (this column vector is stored as one row) |
| mi | column vector of length p containing the means of the predictors calculated from the data in group i |
| Sp | pooled covariance matrix f |
| ln pi | natural log of the prior probability for group i |
Posterior probability
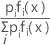
The largest posterior probability is equivalent to the largest value of ln [pi fi (x)]


Notation
| Term | Description |
|---|---|
| pi | prior probability of group i |
| fi(x) | the joint density for the data in group i (with the population parameters replaced by the sample estimates) |