Remarque
Cette commande est disponible avec le Module d'analyse prédictive. Cliquez ici pour plus d'informations sur l'activation du module.
Une équipe de chercheurs recueille et publie des informations détaillées sur les facteurs ayant une influence sur les maladies cardiaques. Les variables incluent l’âge, le sexe, les niveaux de cholestérol, la fréquence cardiaque maximale et plus encore. Cet exemple utilise un ensemble de données publiques comprenant des informations détaillées sur les maladies cardiaques. Les données d’origine proviennent du site archive.ics.uci.edu.
Après une première exploration à l'aide de la fonction Classification CART® pour identifier les prédicteurs importants, les chercheurs utilisent les fonctions Classification TreeNet® et Classification Random Forests® afin de créer des modèles plus avancés à partir du même ensemble de données. Les chercheurs comparent le tableau récapitulatif du modèle et la courbe ROC dans les résultats pour évaluer quel modèle fournit un meilleur résultat de prédiction. Pour consulter les résultats des autres analyses, accédez à Exemple de Classification CART® et à Exemple de Ajuster le modèle avec Classification TreeNet®.
- Ouvrez les données échantillons, MaladieCardiaqueBinaire.MWX.
- Sélectionnez .
- Dans la liste déroulante, sélectionnez Réponse binaire.
- Dans Réponse, saisissez 'Maladies cardiaques'.
- Dans Evénement de réponse, sélectionnez Oui pour indiquer qu'une maladie cardiaque a été détectée chez le patient.
- Dans Prédicteurs continus, saisissez Âge, 'Pression artérielle de repos', Cholestérol, 'Fréquence cardiaque maximale' et 'Vieux pic'.
- Dans Prédicteurs de catégorie, saisissez Sexe, 'Type de douleur thoracique', 'Sucre de sang de jeûne', 'Repos ECG', 'Exercice Angina', Pente, 'Principaux navires' et Thal.
- Cliquez sur OK.
Interpréter les résultats
Pour cette analyse, le nombre d'observations est de 303. Chacun des 300 échantillons bootstrap utilise les 303 observations pour créer un arbre. Les données incluent une division correcte des non-événements et des événements.
Méthode
| Validation de modèle | Validation avec données out-of-bag |
|---|---|
| Nombre d'échantillons bootstrap | 300 |
| Effectif d'échantillon | Identique à la taille des données d'apprentissage de 303 |
| Nombre de prédicteurs sélectionnés pour la partition des nœuds | Racine carrée du nombre total de prédicteurs = 3 |
| Taille minimale du nœud interne | 2 |
| Lignes utilisées | 303 |
Informations de réponse binaire
| Variable | Classe | Dénombrement | % |
|---|---|---|---|
| Maladies cardiaques | Oui (Événement) | 139 | 45,87 |
| Non | 164 | 54,13 | |
| Tous | 303 | 100,00 |
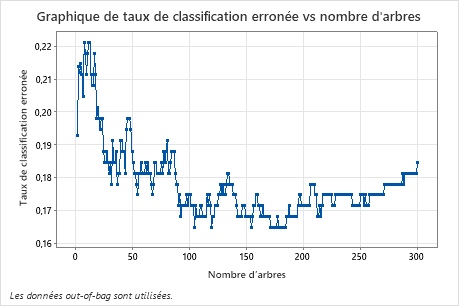
Le diagramme du taux de mauvais classement par rapport au nombre d'arbres montre toute la courbe sur le nombre d'arbres cultivés. Le taux de mauvais classement est d'environ 0,18.
Récapitulatif du modèle
| Nombre total de prédicteurs | 13 |
|---|---|
| Prédicteurs importants | 13 |
| Statistiques | Out-of-Bag |
|---|---|
| Log de vraisemblance de moyenne | 0,4004 |
| Zone située sous la courbe ROC | 0,9028 |
| IC à 95 % | (0,8693; 0,9363) |
| Lift | 2,1079 |
| Taux de mauvaise classification | 0,1848 |
Récapitulatif du modèle
| Nombre total de prédicteurs | 13 |
|---|---|
| Prédicteurs importants | 13 |
| Nombre d'arbres développés | 500 |
| Nombre optimal d'arbres | 351 |
| Statistiques | Apprentissage | Test |
|---|---|---|
| Log de vraisemblance de moyenne | 0,2341 | 0,3865 |
| Zone située sous la courbe ROC | 0,9825 | 0,9089 |
| IC à 95 % | (0,9706; 0,9945) | (0,8757; 0,9421) |
| Lift | 2,1799 | 2,1087 |
| Taux de mauvaise classification | 0,0759 | 0,1750 |
Le tableau récapitulatif du modèle montre que la moyenne du log de vraisemblance négatif est de 0,3994. Ces statistiques indiquent un modèle semblable à celui que Minitab TreeNet® crée en développant 500 arbres. De plus, les taux de mauvais classement sont similaires.
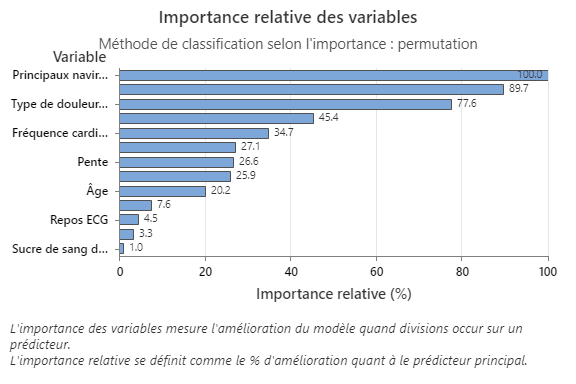
La courbe d'importance relative des variables trace les prédicteurs dans l'ordre de leur effet sur l'amélioration du modèle lorsqu'un prédicteur est divisé sur la séquence des arbres. La variable de prédiction la plus importante est Principaux vaisseaux. Si la contribution de la principale variable de prédiction, Principaux vaisseaux, est de 100 %, alors la variable importante suivante, Thal, a une contribution de 89,7 %. Ainsi, Thal est à 89,7 % aussi importante que Principaux vaisseaux dans ce modèle de classification.
Matrice de confusion
| Catégorie prévue (Out-of-Bag) | ||||
|---|---|---|---|---|
| Classe réelle | Dénombrement | Oui | Non | % correct |
| Oui (Événement) | 139 | 109 | 30 | 78,42 |
| Non | 164 | 26 | 138 | 84,15 |
| Tous | 303 | 135 | 168 | 81,52 |
| Statistiques | Out-of-Bag (%) |
|---|---|
| Taux de vrai positif (sensibilité ou puissance) | 78,42 |
| Taux de faux positif (erreur de type I) | 15,85 |
| Taux de faux négatif (erreur de type II) | 21,58 |
| Taux de vrai négatif (spécificité) | 84,15 |
La matrice de confusion montre la capacité du modèle à séparer correctement les classes. Dans cet exemple, la probabilité qu'un événement soit correctement prédit est de 78,42%. La probabilité qu'un non-événement soit correctement prédit est de 84,15%.
Mauvais classement
| Out-of-Bag | |||
|---|---|---|---|
| Classe réelle | Dénombrement | Mal classé | % erreur |
| Oui (Événement) | 139 | 30 | 21,58 |
| Non | 164 | 26 | 15,85 |
| Tous | 303 | 56 | 18,48 |
Le taux de mauvais classement permet d'indiquer si le modèle prédira avec précision les nouvelles observations. L'erreur de mauvais classement est de 21,58% pour la prédiction des événements. L'erreur de mauvais classement de test est de 15,85% pour la prédiction des non-événements et de 18,48% pour l'ensemble.
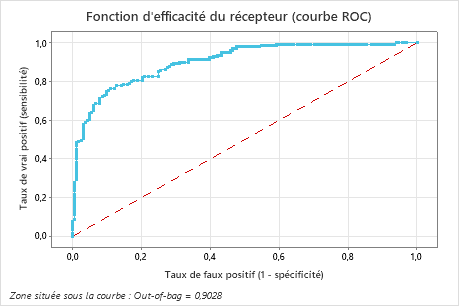
La zone située sous la courbe ROC pour ces données est d'environ 0,9028, ce qui montre une légère amélioration par rapport au modèle de la fonction Classification CART®. Le modèle de la fonction Classification TreeNet® présente une valeur AUROC de test de 0,9089, ces deux méthodes donnent donc des résultats similaires.
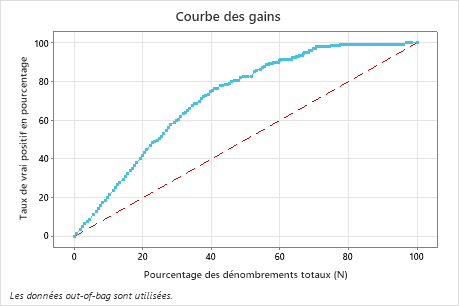
Dans cet exemple, la courbe des gains augmente fortement au-dessus de la ligne de référence, puis s'aplatit. Dans ce cas, environ 40 % des données représentent environ 78% des vrais positifs. Cette différence est le gain supplémentaire dû à l'utilisation du modèle.
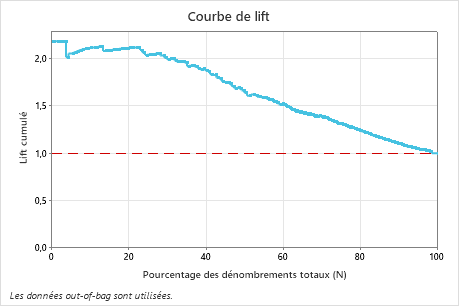
Dans cet exemple, la courbe de lift augmente fortement au-dessus de la ligne de référence, puis redescend progressivement.