Remarque
Cette commande est disponible avec la commande Module d'analyse prédictive. Cliquez ici pour plus d’informations sur la façon d’activer le module.
Une équipe de chercheurs recueille et publie des informations détaillées sur les facteurs qui affectent les maladies cardiaques. Les variables comprennent l’âge, le sexe, le taux de cholestérol, la fréquence cardiaque maximale, etc. Cet exemple est basé sur un ensemble de données publiques qui fournit des informations détaillées sur les maladies cardiaques. Les données originales proviennent de archive.ics.uci.edu.
Après une exploration initiale pour Classification CART® identifier les prédicteurs importants, les chercheurs utilisent les deux Classification TreeNet® et Classification Random Forests® pour créer des modèles plus intensifs à partir du même ensemble de données. Les chercheurs comparent le tableau récapitulatif du modèle et le graphique ROC à partir des résultats pour évaluer quel modèle fournit un meilleur résultat de prédiction. Pour obtenir les résultats des autres analyses, reportez-vous sur Exemple de Classification Random Forests® et Exemple de Classification CART®.
- Ouvrez les données d’échantillonnage, MaladieCardiaqueBinaire.MWX.
- Choisissez .
- Dans la liste déroulante, sélectionnez Réponse binaire.
- Dans Réponse, entrez 'Maladies cardiaques'.
- Dans Evénement de réponse, sélectionnez Oui pour indiquer qu’une maladie cardiaque a été identifiée chez le patient.
- Dans Prédicteurs continus, entrez Âge, 'Pression artérielle de repos', Cholestérol, 'Fréquence cardiaque maximale' et 'Vieux pic'.
- Dans Prédicteurs de catégorie, entrez Sexe, 'Type de douleur thoracique', 'Sucre de sang de jeûne', 'Repos ECG', '', 'Exercice Angina', Pente 'Principaux navires', et Thal.
- Cliquez sur OK.
Interpréter des résultats
Pour cette analyse, Minitab cultive 300 arbres et le nombre optimal d’arbres est de 298. Étant donné que le nombre optimal d’arbres est proche du nombre maximal d’arbres que le modèle cultive, les chercheurs répètent l’analyse avec plus d’arbres.
Récapitulatif du modèle
| Nombre total de prédicteurs | 13 |
|---|---|
| Prédicteurs importants | 13 |
| Nombre d'arbres développés | 300 |
| Nombre optimal d'arbres | 298 |
| Statistiques | Apprentissage | Validation croisée |
|---|---|---|
| Log de vraisemblance de moyenne | 0,2556 | 0,3881 |
| Zone située sous la courbe ROC | 0,9796 | 0,9089 |
| IC à 95 % | (0,9664; 0,9929) | (0,8759; 0,9419) |
| Lift | 2,1799 | 2,1087 |
| Taux de mauvaise classification | 0,0891 | 0,1617 |
Exemple avec 500 arbres
- Sélectionnez Régler les hyperparamètres dans les résultats.
- Dans Nombre d'arbres, entrez 500.
- Cliquez sur Afficher les résultats.
Interpréter des résultats
Pour cette analyse, il y avait 500 arbres cultivés et le nombre optimal d’arbres est de 351. Le meilleur modèle utilise un taux d’apprentissage de 0,01, utilise une fraction de sous-échantillon de 0,5 et utilise 6 comme nombre maximal de nœuds terminaux.
Méthode
| Critères de sélection du nombre d'arbres optimal | Log de vraisemblance maximale |
|---|---|
| Validation de modèle | Validation croisée pour 5 ensemble(s) |
| Taux d'apprentissage | 0,01 |
| Méthode de sélection de sous-échantillon | Complètement aléatoire |
| Fraction de sous-échantillon | 0,5 |
| Nombre maximal de nœuds terminaux par arbre | 6 |
| Taille minimale du nœud terminal | 3 |
| Nombre de prédicteurs sélectionnés pour la partition des nœuds | Nombre total de prédicteurs = 13 |
| Lignes utilisées | 303 |
Informations de réponse binaire
| Variable | Classe | Dénombrement | % |
|---|---|---|---|
| Maladies cardiaques | Oui (Événement) | 139 | 45,87 |
| Non | 164 | 54,13 | |
| Tous | 303 | 100,00 |
Méthode
| Critères de sélection du nombre d'arbres optimal | Log de vraisemblance maximale |
|---|---|
| Validation de modèle | Validation croisée pour 5 ensemble(s) |
| Taux d'apprentissage | 0,001; 0,01; 0,1 |
| Fraction de sous-échantillon | 0,5; 0,7 |
| Nombre maximal de nœuds terminaux par arbre | 6 |
| Taille minimale du nœud terminal | 3 |
| Nombre de prédicteurs sélectionnés pour la partition des nœuds | Nombre total de prédicteurs = 13 |
| Lignes utilisées | 303 |
Informations de réponse binaire
| Variable | Classe | Dénombrement | % |
|---|---|---|---|
| Maladies cardiaques | Oui (Événement) | 139 | 45,87 |
| Non | 164 | 54,13 | |
| Tous | 303 | 100,00 |
Optimisation des hyperparamètres
| Modèle | Nombre optimal d'arbres | Log de vraisemblance de moyenne | Zone située sous la courbe ROC | Taux de classification erronée | Taux d'apprentissage |
|---|---|---|---|---|---|
| 1 | 500 | 0,542902 | 0,902956 | 0,171749 | 0,001 |
| 2* | 351 | 0,386536 | 0,908920 | 0,175027 | 0,010 |
| 3 | 33 | 0,396555 | 0,900782 | 0,161694 | 0,100 |
| 4 | 500 | 0,543292 | 0,894178 | 0,178142 | 0,001 |
| 5 | 374 | 0,389607 | 0,906620 | 0,165082 | 0,010 |
| 6 | 39 | 0,393382 | 0,901399 | 0,174973 | 0,100 |
| Modèle | Fraction de sous-échantillon | Nombre maximal de nœuds terminaux |
|---|---|---|
| 1 | 0,5 | 6 |
| 2* | 0,5 | 6 |
| 3 | 0,5 | 6 |
| 4 | 0,7 | 6 |
| 5 | 0,7 | 6 |
| 6 | 0,7 | 6 |
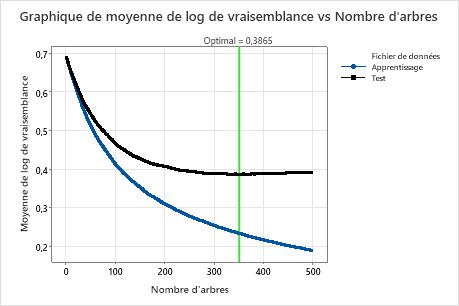
Le graphique Moyenne –Logvraisemblance en fonction du nombre d’arbres montre la courbe entière sur le nombre d’arbres cultivés. La valeur optimale issue de la validation croisée est de 0,3865 lorsque le nombre d’arbres est 351.
Récapitulatif du modèle
| Nombre total de prédicteurs | 13 |
|---|---|
| Prédicteurs importants | 13 |
| Nombre d'arbres développés | 500 |
| Nombre optimal d'arbres | 351 |
| Statistiques | Apprentissage | Validation croisée |
|---|---|---|
| Log de vraisemblance de moyenne | 0,2341 | 0,3865 |
| Zone située sous la courbe ROC | 0,9825 | 0,9089 |
| IC à 95 % | (0,9706; 0,9945) | (0,8757; 0,9421) |
| Lift | 2,1799 | 2,1087 |
| Taux de mauvaise classification | 0,0759 | 0,1750 |
Récapitulatif du modèle
| Nombre total de prédicteurs | 13 |
|---|---|
| Prédicteurs importants | 13 |
| Statistiques | Out-of-Bag |
|---|---|
| Log de vraisemblance de moyenne | 0,4004 |
| Zone située sous la courbe ROC | 0,9028 |
| IC à 95 % | (0,8693; 0,9363) |
| Lift | 2,1079 |
| Taux de mauvaise classification | 0,1848 |
Le tableau résumé du modèle montre que la log-vraisemblance négative moyenne lorsque le nombre d’arbres est de 351 est d’environ 0,23 pour les données d’entraînement et d’environ 0,39 pour les résultats de validation croisée. Ces statistiques indiquent un modèle similaire à celui créé par Minitab Random Forests®. De plus, les taux d’erreurs de classification sont similaires.
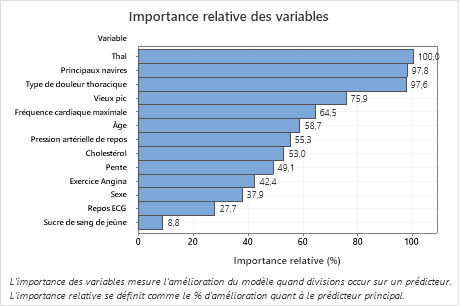
Le graphique Importance relative des variables trace les prédicteurs dans l’ordre de leur effet sur l’amélioration du modèle lorsque des divisions sont effectuées sur un prédicteur au cours de la séquence d’arbres. La variable prédictive la plus importante est Thal. Si la contribution de la variable prédictive principale, Thal, est de 100 %, la variable importante suivante, Major Vessels, a une contribution de 97,8 %. Cela signifie que Major Ships est 97,8 % aussi important que Thal dans ce modèle de classification.
Matrice de confusion
| Classe prévue (apprentissage) | Classe prévue (Validation croisée) | ||||||
|---|---|---|---|---|---|---|---|
| Classe réelle | Dénombrement | Oui | Non | % correct | Oui | Non | % correct |
| Oui (Événement) | 139 | 124 | 15 | 89,21 | 110 | 29 | 79,14 |
| Non | 164 | 8 | 156 | 95,12 | 24 | 140 | 85,37 |
| Tous | 303 | 132 | 171 | 92,41 | 134 | 169 | 82,51 |
| Statistiques | Apprentissage (%) | Validation croisée (%) |
|---|---|---|
| Taux de vrai positif (sensibilité ou puissance) | 89,21 | 79,14 |
| Taux de faux positif (erreur de type I) | 4,88 | 14,63 |
| Taux de faux négatif (erreur de type II) | 10,79 | 20,86 |
| Taux de vrai négatif (spécificité) | 95,12 | 85,37 |
La matrice de confusion montre dans quelle mesure le modèle sépare correctement les classes. Dans cet exemple, la probabilité qu’un événement soit prédit correctement est de 79,14 %. La probabilité qu’un non-événement soit prédit correctement est de 85,37 %.
Mauvais classement
| Apprentissage | Validation croisée | ||||
|---|---|---|---|---|---|
| Classe réelle | Dénombrement | Mal classé | % erreur | Mal classé | % erreur |
| Oui (Événement) | 139 | 15 | 10,79 | 29 | 20,86 |
| Non | 164 | 8 | 4,88 | 24 | 14,63 |
| Tous | 303 | 23 | 7,59 | 53 | 17,49 |
Le taux d’erreurs de classification permet d’indiquer si le modèle prédira avec précision les nouvelles observations. Pour la prédiction des événements, l’erreur de mauvaise classification pour les résultats de validation croisée est de 20,86 %. Pour la prédiction des non-événements, l’erreur de classification erronée est de 14,63 % et pour l’ensemble, l’erreur de classification erronée est de 17,49 %.
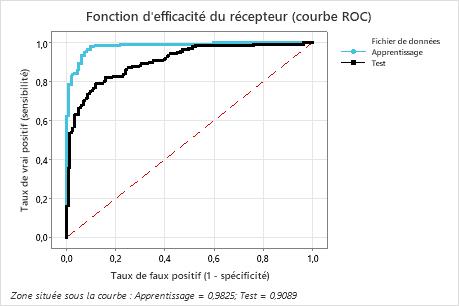
La surface sous la courbe ROC lorsque le nombre d’arbres est de 351 est d’environ 0,98 pour les données d’entraînement et d’environ 0,91 pour les résultats de validation croisée. Ces données indiquent une amélioration significative par rapport au modèle Classification CART®. Le Classification Random Forests® modèle a un AUROC de validation croisée de 0,9028, donc ces deux méthodes donnent des résultats similaires.
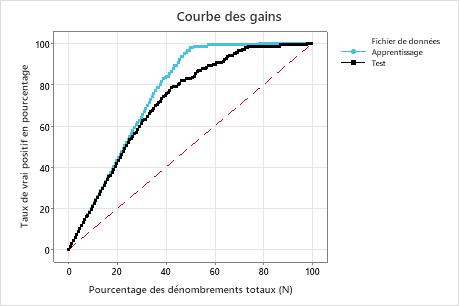
Dans cet exemple, le graphique de gain montre une forte augmentation au-dessus de la ligne de référence, puis un aplatissement. Dans ce cas, environ 40 % des données représentent environ 80 % des vrais positifs. Cette différence est le gain supplémentaire lié à l’utilisation du modèle.
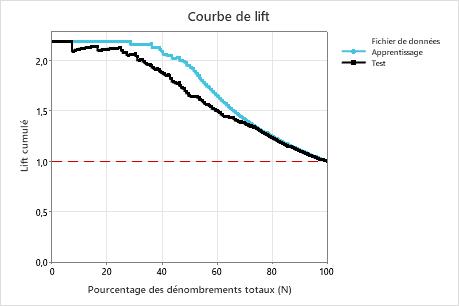
Dans cet exemple, le graphique d’élévation montre une forte augmentation au-dessus de la ligne de référence qui diminue progressivement.
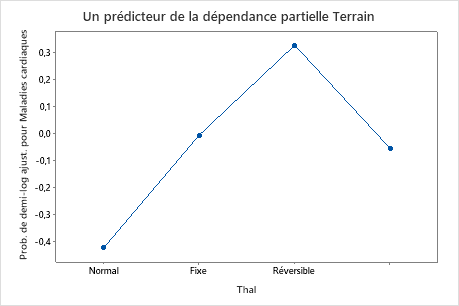
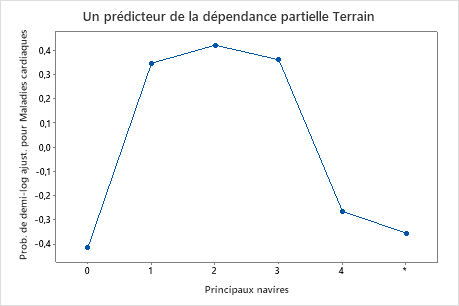
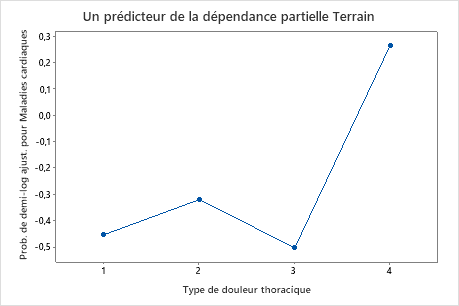
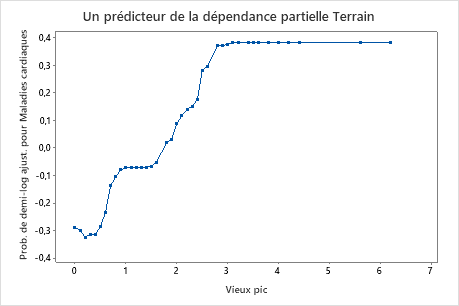
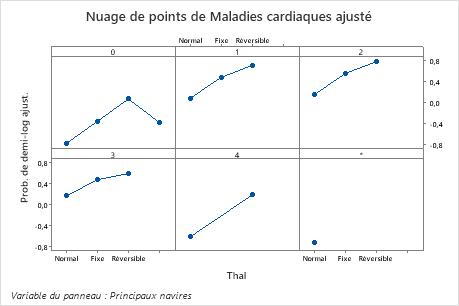
Utilisez les tracés de dépendances partielles pour obtenir des informations sur la façon dont les variables importantes ou les paires de variables affectent les valeurs de réponse ajustées. Les valeurs de réponse ajustées sont sur l’échelle 1/2 log. Les graphiques de dépendance partielle montrent si la relation entre la réponse et une variable est linéaire, monotone ou plus complexe.
Par exemple, dans le graphique de dépendance partielle du type de douleur thoracique, les cotes logarithmiques de 1/2 varient, puis augmentent fortement. Lorsque le type de douleur thoracique est de 4, la probabilité logarithmique de 1/2 d’incidence de maladie cardiaque augmente d’environ -0,04 à 0,03. Sélectionnez ou pour produire des tracés pour d’autres variables