Note
This command is available with the Predictive Analytics add-on module. Click here for more information about how to activate the module.
For the percent of error statistics, the value depends on the percentage of the largest residuals in the calculation. In the following formulas, the calculations assume that the residuals are in order by absolute value, such that i = 1 represents the residual with the greatest absolute value and i = N represents the residual with the least absolute value.
When you use k-fold cross validation, the training statistics include the fitted values from the final tree for the full data set. The test statistics use fitted values from the validation process that can have different trees for each fold.
When you use a test data set for validation, the test statistics use fitted values for the test data set only.
% MSE
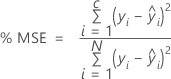
% MAD
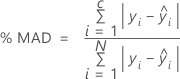
% MAPE
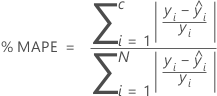
Notation
| Term | Description |
|---|---|
| c | count of largest residuals for the percentage |
| yi | 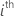 observed response value
observed response value |
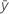 | mean response |
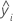 | 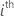 fitted response
fitted response |
| N | number of rows |