Cuando usted desea determinar información acerca de una característica particular de la población (por ejemplo, la media), generalmente toma una muestra aleatoria de esa población porque no es factible medir toda la población. Utilizando esa muestra, usted calcula la característica de la muestra correspondiente, que se usa para resumir información acerca de la característica desconocida de la población. La característica de interés de la población se conoce como parámetro y la característica correspondiente de la muestra es el estadístico de la muestra o la estimación de parámetro. Debido a que el estadístico es un resumen de información acerca de un parámetro obtenido a partir de la muestra, el valor de un estadístico depende de la muestra específica que fue extraída de la población. Sus valores cambian aleatoriamente de una muestra aleatoria a la siguiente, por lo que un estadístico es una cantidad aleatoria (variable). La distribución de probabilidad de esta variable aleatoria se denomina distribución de muestreo. La distribución de muestreo de un estadístico (de muestra) es importante porque permite sacar conclusiones acerca del parámetro de población correspondiente con base en una muestra aleatoria.
Por ejemplo, cuando tomamos una muestra de una población distribuida normalmente, la media de la muestra es un estadístico. El valor de la media de la muestra basado en la muestra en cuestión es una estimación de la media de la población. Este valor estimado cambiará aleatoriamente si se toma otra muestra de la misma población normal. La distribución de probabilidad que describe esos cambios es la distribución de muestreo de la media de la muestra. La distribución de muestreo de un estadístico especifica todos los valores posibles de un estadístico y con qué frecuencia ocurre un rango de valores del estadístico. En aquellos casos en los que la población de origen es normal, la distribución de muestreo de la media de la muestra también es normal.
Las siguientes secciones proporcionan más información sobre los parámetros, las estimaciones de parámetros y las distribuciones de muestreo.
Acerca de los parámetros
Los parámetros son medidas descriptivas de una población completa que se pueden utilizar como las entradas para que una función de distribución de probabilidad (PDF, por sus siglas en inglés) genere curvas de distribución. Los parámetros generalmente se representan con letras griegas para distinguirlos de los estadísticos de muestra. Por ejemplo, la media de la población se representa con la letra griega mu (μ) y la desviación estándar de la población, con la letra griega sigma (σ). Los parámetros son constantes fijas, es decir, no varían como las variables. Sin embargo, sus valores por lo general se desconocen, porque es poco factible medir una población entera.
| Distribución | Parámetro 1 | Parámetro 2 | Parámetro 3 |
|---|---|---|---|
| Chi-cuadrada | Grados de libertad | ||
| Normal | Media | Desviación estándar | |
| Gamma de 3 parámetros | Forma | Escala | Valor umbral |
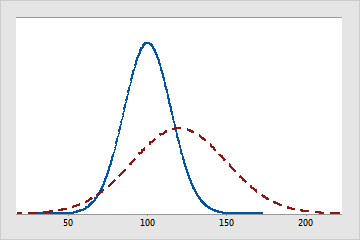
La línea continua representa una distribución normal con una media de 100 y una desviación estándar de 15. La línea discontinua también es una distribución normal, pero tiene una media de 120 y una desviación estándar de 30.
Acerca de las estimaciones de parámetros (también conocidas como estadísticos de muestra)
Los parámetros son medidas descriptivas de toda una población. Sin embargo, sus valores por lo general se desconocen, porque es poco factible medir una población entera. Por eso, usted puede tomar una muestra aleatoria de la población para obtener estimaciones de los parámetros. Un objetivo del análisis estadístico es obtener estimaciones de los parámetros de la población, junto con la cantidad de error asociada con estas estimaciones. Estas estimaciones se conocen también como estadísticos de muestra.
- Las estimaciones de punto son el valor individual más probable de un parámetro. Por ejemplo, la estimación de punto de la media de la población (el parámetro) es la media de la muestra (la estimación del parámetro).
- Los intervalos de confianza son un rango de valores que probablemente contienen el parámetro de población.
Para un ejemplo de estimaciones de parámetros, supongamos que usted trabaja para un fabricante de bujías que estudia un problema en la separación entre electrodos. Sería demasiado costoso medir cada bujía que se fabrica. En lugar de ello, toma una muestra aleatoria de 100 bujías y mide la separación en milímetros. La media de la muestra es 9.2. Esta es la estimación de punto para la media de la población (μ). Igualmente crea un intervalo de confianza de 95% para μ que es (8.8, 9.6). Esto significa que puede estar 95% seguro de que el valor verdadero de la separación promedio de todas las bujías se encuentra entre 8.8 y 9.6.
Acerca de las distribuciones de muestreo
| Calabaza | 1 | 2 | 3 | 4 | 5 | 6 |
| Peso | 19 | 14 | 15 | 12 | 16 | 17 |
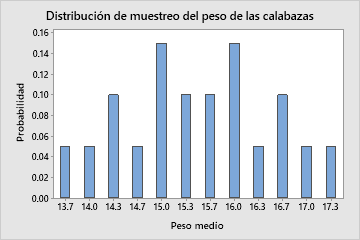
Incluso si se conoce toda la población, con fines ilustrativos, tomamos todas las muestras aleatorias posibles de la población que contengan 3 calabazas (20 muestras aleatorias). Luego, calculamos la media de cada muestra. La distribución de muestreo de las medias de las muestras es descrita por todas las medias de muestra de cada muestra aleatoria posible de 3 calabazas, lo cual se refleja en la siguiente tabla.
| Muestra | Pesos | Peso medio | Probabilidad |
|---|---|---|---|
| 2, 3, 4 | 14, 15, 12 | 13.7 | 1/20 |
| 2, 4, 5 | 14, 12, 16 | 14 | 1/20 |
| 2, 4, 6 | 14, 12, 17 | 14.3 | 2/20 |
| 3, 4, 5 | 15, 12, 16 | ||
| 3, 4, 6 | 15, 12, 17 | 14.7 | 1/20 |
| 1, 2, 4 | 19, 14, 12 | 15 | 3/20 |
| 2, 3, 5 | 14, 15, 16 | ||
| 4, 5, 6 | 12, 16, 17 | ||
| 2, 3, 6 | 14, 15, 17 | 15.3 | 2/20 |
| 1, 3, 4 | 19, 15, 12 | ||
| 1, 4, 5 | 19, 12, 16 | 15.7 | 2/20 |
| 2, 5, 6 | 14, 16, 17 | ||
| 1, 2, 3 | 19, 14, 15 | 16 | 3/20 |
| 3, 5, 6 | 15, 16, 17 | ||
| 1, 4, 6 | 19, 12, 17 | ||
| 1, 2, 5 | 19, 14, 16 | 16.3 | 1/20 |
| 1, 2, 6 | 19, 14, 17 | 16.7 | 2/20 |
| 1, 3, 5 | 19, 15, 16 | ||
| 1, 3, 6 | 19, 15, 17 | 17 | 1/20 |
| 1, 5, 6 | 19, 16, 17 | 17.3 | 1/20 |
En la práctica, es prohibitivo y poco factible tabular la distribución de la distribución de muestreo como en el ejemplo ilustrativo anterior. Incluso en el mejor escenario, cuando usted conoce la población de origen de las muestras, quizás no pueda determinar la distribución de muestreo exacta del estadístico de muestra de interés. Sin embargo, en algunos casos probablemente pueda aproximar la distribución de muestreo del estadístico de la muestra. Por ejemplo, si toma una muestra de la población normal, entonces la media de la muestra tiene exactamente la distribución normal.
Pero si usted toma una muestra de una población que no es normal, es probable que no pueda determinar la distribución exacta de la media de la muestra. Sin embargo, debido al teorema del límite central, la media de la muestra se distribuye aproximadamente como una distribución normal, siempre y cuando sus muestras sean lo suficientemente grandes. Entonces, si no se conoce la población y las muestras son lo suficientemente grandes, usted podría afirmar, por ejemplo, que existe aproximadamente un 85% de certeza de que la media de la muestra esté dentro de un cierto número de desviaciones estándar de la media de la población.