En este tema
Media
Una medida frecuentemente utilizada del centro de un lote de números. La media también se denomina promedio. Es la suma de todas las observaciones dividida entre el número de observaciones (presentes).
Fórmula
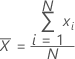
Notación
| Término | Description |
|---|---|
| xi | i ésima observación |
| N | número de observaciones presentes |
Desviación estándar (Desv.Est.)
La desviación estándar de la muestra proporciona una medida de la dispersión de los datos. Es igual a la raíz cuadrada de la varianza de la muestra.
Fórmula
 , entonces la desviación estándar de la muestra es:
, entonces la desviación estándar de la muestra es:
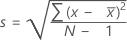
Notación
| Término | Description |
|---|---|
| x i | i ésima observación |
 | media de las observaciones |
| N | número de observaciones presentes |
N
Anderson-Darling
A2 mide el área entre la línea ajustada (que se basa en la distribución elegida) y la función escalón no paramétrica (que se basa en los puntos de la gráfica). El estadístico es una distancia elevada al cuadrado que tiene mayor ponderación en las colas de la distribución. Un valor pequeño de Anderson-Darling indica que la distribución se ajusta mejor a los datos.
La prueba de normalidad de Anderson-Darling se define de la siguiente manera:
H0: Los datos siguen una distribución normal
H1: Los datos no siguen una distribución normal
Fórmula

Otra medida cuantitativa para informar del resultado de la prueba de normalidad es el valor p. Un valor p pequeño es una indicación de que la hipótesis nula es falsa.

- Si 13 >A'2 > 0,600 entonces p = exp(1,2937 - 5,709 * A'2 + 0,0186(A'2)2)
- Si 0,600 >A'2 > 0,340 entonces p = exp(0,9177 - 4,279 * A'2 – 1,38(A'2)2)
- Si 0,340 >A'2 > 0,200 entonces p = 1 – exp(–8,318 + 42,796 * A'2 – 59,938(A'2)2)
- Si A'2 <0.200 then p = 1 – exp(–13.436 + 101.14 * A'2 – 223,73(A'2)2)
Notación
| Término | Description |
|---|---|
| F(Yi) |  , que es la función de distribución acumulada de la distribución normal estándar , que es la función de distribución acumulada de la distribución normal estándar |
| Yi | datos ordenados |
Ryan-Joiner
La prueba de Ryan-Joiner proporciona un coeficiente de correlación, que indica la correlación entre tus datos y las puntuaciones normales de las estadísticas de orden de los datos. Si el coeficiente de correlación está cerca de 1, los datos se encuentran cerca de la gráfica de probabilidad normal. Si es menor que el valor crítico adecuado, usted rechazará la hipótesis nula de normalidad.
Fórmula
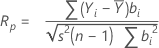

- Si n ≥ 50
-
- Si n < 50
-
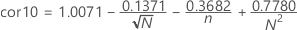





- Si Rp > cor10, entonces p > 0,10.
- Si cor05 < Rp ≤ cor10, entonces:

- Si cor01 < Rp ≤ cor05, entonces:

- Si Rp ≤ cor01, entonces p < 0.01.
Notación
| Término | Description |
|---|---|
| Yi | observaciones ordenadas |
| bi | Estadísticas normales de puntuaciones del orden |
| s2 | Varianza de la muestra |
| n | tamaño de la muestra |
| i | Rango de los datos ordenados |
Kolmogorov-Smirnov
Fórmula
- H0: Los datos siguen una distribución normal
- H1: Los datos no siguen una distribución normal
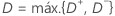
Para determinar el valor p, Minitab utiliza una estadística ajustada (d*) que tiene en cuenta el tamaño de la muestra (n).

Compara d* con los siguientes valores críticos para determinar el valor p:
- Si d* < 0.775, entonces p > 0,15.
- Si 0,775 ≤ d* < 0.819, entonces:
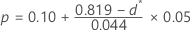
- Si 0,819 ≤ d* < 0.895, entonces:

- Si 0,895 ≤ d* < 0.995, entonces:

- Si 0,995 ≤ d* < 1.035, entonces:
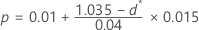
- Si d* ≥ 1,035, entonces p < 0.01.
Notación
| Término | Description |
|---|---|
| D+ | maxi {i / n – Z (i)} |
| D– | maxi {Z (i) – (i – 1) / n)} |
| Z | F(X(i)) |
| F(x) | función de distribución de probabilidad de la distribución normal |
| X(i) | i-ésimo orden estadístico de una muestra aleatoria, 1 ≤ i ≤ n |
| n | tamaño de la muestra |
Puntos de la gráfica
En general, mientras más cerca se encuentren los puntos de la línea ajustada, mejor será el ajuste. Minitab provee dos medidas de bondad de ajuste que ayudan a evaluar la forma en que la distribución se ajusta a los datos.
Fórmula
| Distribución | coordenada x | coordenada y |
|---|---|---|
| Normal | x | Φ–1 norm |
Notación
| Término | Description |
|---|---|
| Φ–1 norm | valor devuelto para p por la cdf inversa para la distribución normal estándar |
Gráficas de probabilidad
Los datos de entrada se grafican como los valores de X. Minitab calcula la probabilidad de ocurrencia sin presuponer una distribución. La escala Y de la gráfica se asemeja a la escala Y incluida en el artículo sobre probabilidad normal donde las probabilidades se grafican como una línea recta, como si los datos provinieran de una distribución normal.