En este tema
Media estimada
Fórmula
La media para la distribución de Poisson se calcula de la siguiente manera:
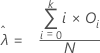
Cálculo
| Datos | 2 2 3 3 2 4 4 2 1 1 1 4 4 3 0 4 3 2 3 3 4 1 3 1 4 3 2 2 1 2 0 2 3 2 3 |
| Categoría (i) | Observado (Oi) | Media estimada | Probabilidad de Poisson (pi) |
|---|---|---|---|
| 0 | 2 | 0 * 2 = 0 | p0 = e -2.4 = 0.090718 |
| 1 | 6 | 1 * 6 = 6 | p1 = e-2.4 * 2.4 = 0.217723 |
| 2 | 10 | 2 * 10 = 20 | p2 = e-2.4 * (2.4)2/ 2! = 0.261268 |
| 3 | 10 | 3 * 10 = 30 | p3 = e-2.4 * (2.4)3/ 3! = 0.209014 |
 |
7 | 4 * 7 = 28 | p4 = 1 - (p0 + p1 +p2 + p3) = 0.221267 |
N = 35
Σ (i * Oi) = 84
Media estimada = 
Notación
| Término | Description |
|---|---|
| N | suma de todos los valores observados (O0 + O1 + ...+ Ok) |
| k | (el número de categorías) - 1 |
| Oi | el número observado de eventos en la iésima categoría |
| pi | Probabilidad de Poisson |
Número de categorías
Minitab determina las categorías utilizando los siguientes métodos iterativos:
Definición de la primera categoría
Sea pi = P(X  xi )
xi )
Sea i = 1: si N*pi  2, entonces la primera categoría se define como "
2, entonces la primera categoría se define como " x 1". Si N*pi < 2, entonces aumente i en uno y repita: si N*p 2
x 1". Si N*pi < 2, entonces aumente i en uno y repita: si N*p 2  2, entonces la primera categoría se define como "
2, entonces la primera categoría se define como " x 2". Si N*pi < 2, aumente i en uno y repita hasta N*pi
x 2". Si N*pi < 2, aumente i en uno y repita hasta N*pi  2. Detenga las iteraciones cuando esta condición sea satisfecha por primera vez o cuando xi sea el tercer valor de datos más grande, y defina la primera categoría como "
2. Detenga las iteraciones cuando esta condición sea satisfecha por primera vez o cuando xi sea el tercer valor de datos más grande, y defina la primera categoría como " xi ". Si el valor de la primera categoría es cero, entonces la primera categoría se define como "0" sin el signo "menor que o igual a". La probabilidad y el valor esperado asociado con la primera categoría son pi y N*pi , respectivamente. El valor observado para la primera categoría es el número de todos los valores de datos
xi ". Si el valor de la primera categoría es cero, entonces la primera categoría se define como "0" sin el signo "menor que o igual a". La probabilidad y el valor esperado asociado con la primera categoría son pi y N*pi , respectivamente. El valor observado para la primera categoría es el número de todos los valores de datos  xi .
xi .
Definición de la última categoría
Conceptualmente, definir la última categoría es similar a definir la primera categoría, pero Minitab trabaja hacia atrás comenzando desde el valor de datos más grande.
La última categoría es " xj ", donde xj es el valor de datos más grande mayor que (1 + el valor de los datos de la primera categoría), de modo que la categoría tenga un valor esperado mayor que 2. La probabilidad y el valor esperado para la última categoría son pj y N*pj , respectivamente, y el valor observado es el número de valores de datos
xj ", donde xj es el valor de datos más grande mayor que (1 + el valor de los datos de la primera categoría), de modo que la categoría tenga un valor esperado mayor que 2. La probabilidad y el valor esperado para la última categoría son pj y N*pj , respectivamente, y el valor observado es el número de valores de datos  xj .
xj .
Definición de las categorías intermedias
Después de determinar la primera y la última categorías, Minitab determina las categorías intermedias. Sea "X  k" la primera categoría y "X
k" la primera categoría y "X  m" es la última categoría. Si todos los enteros entre (k, m) tienen valores esperados
m" es la última categoría. Si todos los enteros entre (k, m) tienen valores esperados  2, entonces todos ellos constituyen una categoría intermedia. De lo contrario, Minitab utiliza un bucle recursivo para agrupar múltiples enteros adyacentes en categorías con valores esperados
2, entonces todos ellos constituyen una categoría intermedia. De lo contrario, Minitab utiliza un bucle recursivo para agrupar múltiples enteros adyacentes en categorías con valores esperados  2. Hay ciertas situaciones, como un conjunto de datos con pocas observaciones, en las que el valor esperado de una categoría es menor que 2.
2. Hay ciertas situaciones, como un conjunto de datos con pocas observaciones, en las que el valor esperado de una categoría es menor que 2.
Notación
| Término | Description |
|---|---|
| N | el número total de observaciones |
| xi | el i ésimo valor en el conjunto de datos después de ordenarlo de menor a mayor |
| pi | Probabilidad de Poisson |
Probabilidad de Poisson
Fórmula
La probabilidad de Poisson de la i ésima categoría (i < k) es

La probabilidad de Poisson para la última categoría, donde i = k,
pi = 1 – (p0 + p1 + ...+ pk-1)
Notación
| Término | Description |
|---|---|
| k | el número de categorías |
| λ | la media estimada de su muestra |
Número esperado
Fórmula
El número esperado de observaciones en la i ésima categoría es N * pi .
Notación
| Término | Description |
|---|---|
| N | tamaño de la muestra |
| pi | la probabilidad de Poisson asociada con la i ésima categoría |
Contribución a chi-cuadrada
Fórmula
La contribución de la Iésima categoría al valor de chi-cuadrada se calcula de la siguiente manera
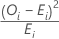
Notación
| Término | Description |
|---|---|
| OI | el número observado de observaciones en la Iésima categoría |
| EI | el número esperado de observaciones en la Iésima categoría |
Estadístico de prueba
Fórmula
El estadístico de la prueba de chi-cuadrada de bondad de ajuste se calcula de la siguiente manera,
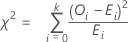
Notación
| Término | Description |
|---|---|
| k | (el número de categorías) - 1 |
| Oi | el número observado de observaciones en la iésima categoría |
| Ei | el número esperado de observaciones en la iésima categoría |
Valor p y grados de libertad
El valor p es:
Prob (X > Estadístico de prueba)
donde X sigue una distribución de chi-cuadrada con k - 1 grados de libertad si usted utiliza el subcomando MEAN o k- 2 grados de libertad si no utiliza el subcomando MEAN.
Cálculo
| Datos | 2 2 3 3 2 4 4 2 1 1 1 4 4 3 0 4 3 2 3 3 4 1 3 1 4 3 2 2 1 2 0 2 3 2 3 |
| Categoría (i) | Observado (Oi) | Media estimada | Probabilidad de Poisson (pi) |
|---|---|---|---|
| 0 | 2 | 0 * 2 = 0 | p0 = e -2.4 = 0.090718 |
| 1 | 6 | 1 * 6 = 6 | p1 = e -2.4 * 2.4 = 0.217723 |
| 2 | 10 | 2 * 10 = 20 | p2 = e -2.4 * (2.4)2/ 2! = 0.261268 |
| 3 | 10 | 3 * 10 = 30 | p3 = e -2.4 * (2.4)3/ 3! = 0.209014 |
 |
7 | 4 * 7 = 28 | p4 = 1 - (p0 + p1 +p2 + p3 ) = 0.221267 |
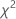 = ( 0.43492 + 0.344527 + 0.080058 + 0.985114 + 0.071545) = 1.91622
= ( 0.43492 + 0.344527 + 0.080058 + 0.985114 + 0.071545) = 1.91622
k = 5= el número de categorías
GL = 5- 2 = 3
valor p = P (X > 1.91622) = 0.590
Notación
| Término | Description |
|---|---|
| k | el número de categorías |
| Oi | el número observado de observaciones en la iésima categoría. |
| Ei | el número esperado de observaciones en la iésima categoría. |
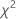 | estadístico de la prueba de chi-cuadrada de bondad de ajuste |
| GL | grados de libertad |