En este tema
Paso 1: Determinar un intervalo de confianza para la diferencia en las medias de población
Primero, considere la diferencia en las medias de las muestras y luego examine el intervalo de confianza.
La diferencia es una estimación de la diferencia en las medias de las poblaciones. Puesto que la diferencia se basa en los datos de una muestra y no en toda la población, es improbable que la diferencia en las muestras sea igual a la diferencia en las poblaciones. Para estimar mejor la diferencia en las poblaciones, utilice el intervalo de confianza de la diferencia.
El intervalo de confianza proporciona un rango de valores probables para la diferencia entre las medias de dos poblaciones. Por ejemplo, un nivel de confianza de 95% indica que si usted toma 100 muestras aleatorias de la población, podría esperar que aproximadamente 95 de las muestras contengan la diferencia de población. El intervalo de confianza ayuda a evaluar la significancia práctica de los resultados. Utilice su conocimiento especializado para determinar si el intervalo de confianza incluye valores que tienen significancia práctica para su situación. Si el intervalo es demasiado amplio para ser útil, considere aumentar el tamaño de la muestra. Para obtener más información, vaya a Maneras de obtener un intervalo de confianza más preciso.
Estimación de la diferencia
| Diferencia | IC de 95% para la diferencia |
|---|---|
| 21.00 | (14.22, 27.78) |
Resultados clave: Estimación para la diferencia, IC de 95% para la diferencia
En estos resultados, la estimación de la diferencia en las medias de las poblaciones en las calificaciones de los hospitales es 21. Usted puede estar 95% seguro de que la media de las poblaciones está entre 14,22 y 27,78.
Paso 2: Determinar si la diferencia es estadísticamente significativa
- Valor p ≤ α: La diferencia entre las medias es estadísticamente significativa (Rechaza H0)
- Si el valor p es menor que o igual al nivel de significancia, la decisión es rechazar la hipótesis nula. Usted puede concluir que la diferencia entre las medias de las poblaciones no es igual a la diferencia hipotética. Si no especificó una diferencia hipotética, Minitab prueba si no hay diferencia entre las medias (Diferencia hipotetizada = 0). Utilice su conocimiento especializado para determinar si la diferencia es significativa desde el punto de vista práctico. Para obtener más información, vaya a Significancia estadística y práctica.
- Valor p > α: La diferencia entre las medias no es estadísticamente significativa (No puede rechazar H0)
- Si el valor p es mayor que el nivel de significancia, la decisión es que no se puede rechazar la hipótesis nula. Usted no tiene suficiente evidencia para concluir que la diferencia entre las medias de las poblaciones es estadísticamente significativa. Debe asegurarse de que su prueba tenga suficiente potencia para detectar una diferencia que es significativa desde el punto de vista práctico. Para obtener más información, vaya a Potencia y tamaño de la muestra para t de 2 muestra.
Prueba
| Hipótesis nula | H₀: μ₁ - µ₂ = 0 |
|---|---|
| Hipótesis alterna | H₁: μ₁ - µ₂ ≠ 0 |
| Valor T | GL | Valor p |
|---|---|---|
| 6.31 | 32 | 0.000 |
Resultado clave: Valor p
En estos resultados, la hipótesis nula indica que la diferencia en la calificación media entre dos hospitales es 0. Puesto que el valor p es menor que 0.00, que es menor que el nivel de significancia de 0.05, la decisión es rechazar la hipótesis nula y concluir que las calificaciones de los hospitales son diferentes.
Paso 3: Verificar si hay problemas en sus datos
Problemas con sus datos, tales como asimetría y valores atípicos, pueden afectar negativamente sus resultados. Utilice gráficas para buscar asimetría (examinando la dispersión de cada muestra) e identificar posibles valores atípicos.
Examine la dispersión de los datos para determinar si los datos parecen ser asimétricos.
Cuando los datos son asimétricos, la mayoría de los datos se ubican en la parte superior o inferior de la gráfica. Frecuentemente, es más fácil detectar la asimetría con un histograma o gráfica de caja.
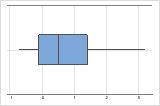
Asimétrico hacia la derecha
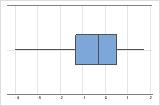
Asimétrico hacia la izquierda
La gráfica de caja con datos asimétricos hacia la derecha muestra tiempos de espera. La mayoría de los tiempos de espera son relativamente cortos y solo unos pocos tiempos de espera son largos. La gráfica de caja con datos asimétricos hacia la izquierda muestra datos de tiempo de falla. Unos pocos elementos fallan inmediatamente y muchos más fallan posteriormente.
Los datos marcadamente asimétricos pueden afectar la validez del valor p si sus muestras son pequeñas (cualquiera de las muestras tiene menos de 15 valores). Si sus datos son marcadamente asimétricos y tiene una muestra pequeña, considere aumentar el tamaño de la muestra.
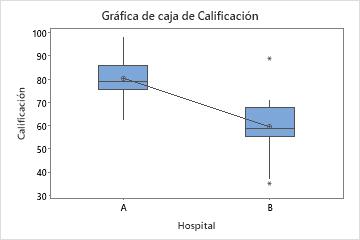
Salida de muestra
En estas gráficas de caja, los datos del Hospital B parecen ser muy asimétricos.
Identifique valores atípicos
Los valores atípicos, que son valores de datos que están muy alejados de otros valores de datos, pueden afectar fuertemente los resultados de su análisis. Frecuentemente, es más fácil identificar los valores atípicos en una gráfica de caja.
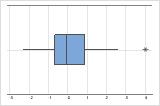
En una gráfica de caja, los asteriscos (*) denotan valores atípicos.
Trate de identificar la causa de cualquier valor atípico. Corrija cualquier error de entrada de datos o de medición. Considere eliminar los valores de datos asociados con eventos anormales y únicos (también conocidos como causas especiales). Luego, repita el análisis. Para obtener más información, vaya a Identificar valores atípicos.
Salida de muestra
En estas gráficas de caja, los datos del Hospital B tienen 2 valores atípicos.