La gráfica de probabilidad se ubica en la esquina superior derecha de la gráfica de revisión general de distribuciones.
Utilice la gráfica de probabilidad para evaluar en qué grado la distribución que usted seleccionó se ajusta a sus datos. Si los puntos siguen la línea ajustada, entonces es razonable utilizar esa distribución para modelar los datos.
Los puntos en la gráfica son los percentiles estimados basados en un método no paramétrico. Cuando usted detiene el cursor en un punto de datos, Minitab muestra el tiempo de falla observado y la probabilidad acumulada estimada.
La línea se basa en la distribución ajustada. Cuando usted detiene el cursor en la línea ajustada, Minitab muestra una tabla de percentiles de varios porcentajes.
El estadístico Anderson-Darling (ajust.) mide el ajuste de la distribución. Valores de Anderson-Darling sustancialmente más pequeños por lo general indican que la distribución se ajusta mejor a los datos. Sin embargo, leves diferencias podrían no ser relevantes desde el punto de vista práctico. Además, los valores calculados para distribuciones diferentes pudieran no ser comparables directamente. Por lo tanto, usted también debe utilizar la gráfica de probabilidad y otras informaciones para evaluar el ajuste de distribución.
Si usted utiliza el método de estimación alternativo —el método de mínimos cuadrados (LSXY)—, Minitab muestra un coeficiente de correlación de Pearson. El coeficiente de correlación es un número positivo que no puede ser mayor que 1. Valores de coeficientes de correlación más altos generalmente indican que la distribución provee un mejor ajuste a los datos.
Ejemplo de salida
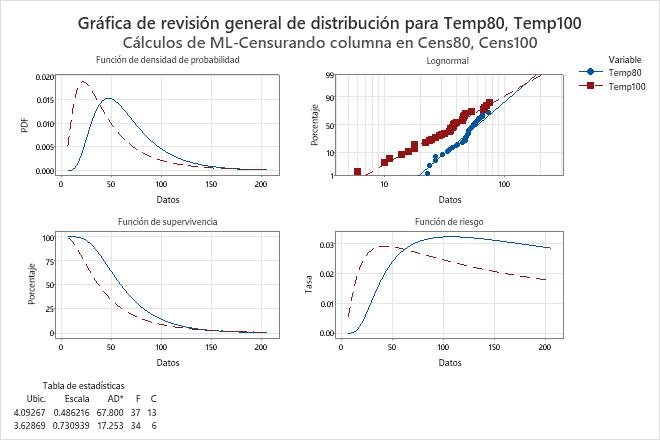
Interpretación
En la gráfica de probabilidad para los datos sobre bobinas de motor, las líneas ajustadas de ambas variables se basan en una distribución lognormal.
Para cada variable, los datos parecen seguir la línea ajustada. Por lo tanto, la distribución lognormal parece ser una distribución apropiada para modelar los datos.