En este tema
- Paso 1: Determine qué tan adecuadamente se ajusta el modelo a los datos
- Paso 2: Determine si la asociación entre la respuesta y el término es estadísticamente significativa
- Paso 3: Determine los riesgos relativos de los predictores
- Paso 4: Determine si el modelo satisface la hipótesis de riesgos proporcionales
Paso 1: Determine qué tan adecuadamente se ajusta el modelo a los datos
- Valor p ≤ α: El modelo se ajusta adecuadamente a los datos.
- Si el valor p es menor o igual al nivel de significancia, es posible concluir que el modelo se ajusta adecuadamente a los datos. Es necesario examinar si alguno de los términos es estadísticamente significativo y también garantizar que el modelo satisfaga la hipótesis de riesgos proporcionales.
- Valor p > α: No existe suficiente evidencia para concluir que el modelo se ajusta adecuadamente a los datos.
- Si el valor p es mayor que el nivel de significancia, no es posible concluir que el modelo se ajusta adecuadamente a los datos. Sería conveniente reajustar el modelo con términos diferentes.
Pruebas de bondad de ajuste
| Prueba | GL | Chi-cuadrada | Valor p |
|---|---|---|---|
| Relación de verosimilitud | 4 | 18.31 | 0.001 |
| Wald | 4 | 21.15 | 0.000 |
| Puntuación | 4 | 24.78 | 0.000 |
Resultados clave: Valor p
En estos resultados, los valores p para las 3 pruebas son inferiores a 0.05, por lo que es posible concluir que el modelo se ajusta adecuadamente a los datos.
Paso 2: Determine si la asociación entre la respuesta y el término es estadísticamente significativa
- Valor p ≤ α: La asociación es estadísticamente significativa
- Si el valor p es menor que o igual al nivel de significancia, es posible concluir que existe una asociación estadísticamente significativa entre la variable de respuesta y el término.
- Valor p > α: La asociación no es estadísticamente significativa
- Si el valor p es mayor que el nivel de significancia, no es posible concluir que existe una asociación estadísticamente significativa entre la variable de respuesta y el término. Le convendría reajustar el modelo sin el término.
- Si un factor aleatorio es significativo, es posible concluir que el factor tiene un efecto en el tiempo requerido para que ocurra el evento.
- Si un predictor continuo es significativo, es posible concluir que los cambios en el valor del predictor están asociados a los cambios en el riesgo de que el sujeto experimente el evento.
- Si un término de interacción es significativo, la relación entre un factor y la respuesta depende del nivel del resto de los factores incluidos en el término. En este caso, los efectos principales no deben interpretarse sin considerar el efecto de interacción.
- Si un término polinómico es significativo,es posible concluir que los datos contienen curvatura.
Análisis de Varianza
| Prueba de Wald | |||
|---|---|---|---|
| Fuente | GL | Chi-cuadrada | Valor p |
| Edad | 1 | 1.78 | 0.182 |
| Escenario | 3 | 17.92 | 0.000 |
Resultados clave: Valor p
En estos resultados, el valor p para la etapa es significativa a un nivel α de 0.05. Por lo tanto, es posible concluir que la etapa del cáncer tiene un efecto estadísticamente significativo en la supervivencia del paciente. Sin embargo, el valor p para la edad es 0.182, por lo que el efecto de la edad no es significativo a un nivel α de 0.05.
Paso 3: Determine los riesgos relativos de los predictores
- Variable categórica
-
En la tabla de riesgos relativos para predictores categóricos, Minitab etiqueta dos niveles de la variable categórica como Nivel A y Nivel B. El riesgo relativo describe la tasa de ocurrencia del evento para el nivel A en relación con el nivel B. Por ejemplo, en los siguientes resultados, el riesgo de experimentar el evento para los pacientes en el estadio IV es 5.5 veces mayor que el riesgo para los pacientes en el estadio I.
- Variable continua
- En la tabla riesgos relativos para predictores continuos, Minitab muestra la unidad de cambio y el riesgo relativo. El riesgo relativo describe el cambio en la tasa de riesgos para cada unidad de cambio en el valor del predictor. Por ejemplo, en los siguientes resultados un paciente tiene 1.02 veces más probabilidades de experimentar el evento por cada aumento de 1 año en su edad.
Es posible utilizar el intervalo de confianza para determinar si el riesgo relativo es estadísticamente significativo. Por lo general, si el intervalo de confianza contiene 1, no se puede concluir que el riesgo relativo sea estadísticamente significativo.
Riesgos relativos para predictores continuos
| Unidad de cambio | Riesgo relativo | IC de 95% | |
|---|---|---|---|
| Edad | 1 | 1.0192 | (0.9911, 1.0481) |
Riesgos relativos para predictores categóricos
| Nivel A | Nivel B | Riesgo relativo | IC de 95% |
|---|---|---|---|
| Escenario | |||
| II | I | 1.1503 | (0.4647, 2.8477) |
| III | I | 1.9010 | (0.9459, 3.8204) |
| IV | I | 5.5068 | (2.4086, 12.5901) |
| III | II | 1.6526 | (0.6819, 4.0049) |
| IV | II | 4.7872 | (1.7825, 12.8566) |
| IV | III | 2.8968 | (1.2952, 6.4788) |
Resultados clave: Riesgo relativo, IC de 95%
Paso 4: Determine si el modelo satisface la hipótesis de riesgos proporcionales
- Tabla de pruebas para detectar riesgos proporcionales
-
Utilice las pruebas para determinar si el modelo cumple con la hipótesis de riesgos proporcionales. La hipótesis nula es que el modelo cumple con la hipótesis para todos los predictores. Por lo general, un nivel de significancia (denotado como α o alfa) de 0.05 funciona adecuadamente. Un nivel de significancia de 0.05 indica un riesgo de 5% de concluir que el modelo explica la hipótesis cuando en realidad no es así.
Si el valor p es menor o igual al nivel de significancia, es posible concluir que el modelo no cumple la hipótesis de riesgos proporcionales. Si el valor p es mayor que el nivel de significancia, no es posible concluir que el modelo no cumple la hipótesis.
- Gráfica de Arjas
-
Utilice la gráfica de Arjas para determinar si el modelo cumple la hipótesis de riesgos proporcionales para un predictor categórico. Si las curvas en la gráfica difieren de la línea de 45 grados, entonces el modelo no cumple con la hipótesis de riesgos proporcionales para el predictor.
Si el modelo no cumple con la hipótesis para una variable, en su lugar, intente utilizar la variable como variable de estratificación.
- Gráfica de Andersen
-
Utilice la gráfica de Andersen para determinar si el modelo cumple la hipótesis de riesgos proporcionales para los diferentes estratos. Cada combinación de valores de una o más variables de estratificación define un estrato. La gráfica contiene una curva para cada estrato. Si el modelo cumple con la hipótesis, las curvas son líneas rectas a través del punto donde X = 0 e Y = 0. Si la tasa de riesgo inicial para un estrato es la misma que la tasa de riesgo inicial para el estrato en el eje X, entonces la curva sigue la línea de referencia de 45 grados en la gráfica.
Si el modelo no cumple con la hipótesis, considere si es necesario dividir los datos entre la variable de estratificación para la cual el modelo no cumple la hipótesis de riesgos proporcionales. Después, realice un análisis por separado en cada subconjunto de datos. Los análisis independientes proporcionan diferentes efectos para los predictores en cada subconjunto.
Pruebas para detectar riesgos proporcionales
| Término | GL | Correlación | Chi-cuadrada | Valor p |
|---|---|---|---|---|
| Edad | 1 | 0.1328 | 1.18 | 0.278 |
| Escenario | ||||
| II | 1 | -0.0104 | 0.01 | 0.940 |
| III | 1 | -0.2445 | 2.86 | 0.091 |
| IV | 1 | -0.1193 | 0.63 | 0.426 |
| General | 4 | — | 4.61 | 0.330 |
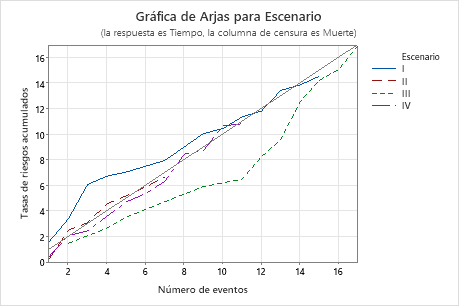
Resultados clave: Valor P, gráfica de Arjas
En estos resultados, los valores p para la prueba de riesgos proporcionales son todos los valores superiores a 0.05, por lo que no es posible concluir que el modelo no cumple la hipótesis de riesgos proporcionales.
La gráfica de Arjas muestra las tasas de riesgo acumulado en comparación con el número de eventos para cada nivel de Escenario. En esta gráfica de Arjas, las líneas generalmente siguen la línea de 45 grados, por lo que se puede concluir que el modelo cumple con la hipótesis de riesgos proporcionales para el predictor Escenario.