En este tema
- El efecto del formato de datos en la interpretación del R2 de desviación y del R2 de desviación ajustado
- Por qué la prueba de bondad de ajuste de desviación puede ser engañosa para datos de Respuesta binaria/Frecuencia.
- Por qué la prueba de bondad de ajuste de Pearson puede ser engañosa para datos de Respuesta binaria/Frecuencia
En regresión logística binaria, usted puede ingresar datos en dos formatos diferentes: formato de Respuesta binaria/Frecuencia y formato de Evento/Ensayo. La fiabilidad y la interpretación de algunos estadísticos en la salida dependen del formato de los datos. Para obtener más información sobre cuándo utilizar cada formato de datos, vaya a Cuándo utilizar cada formato de datos en regresión logística binaria.
El efecto del formato de datos en la interpretación del R2 de desviación y del R2 de desviación ajustado
Para regresión logística binaria, el formato de los datos afecta la forma en que usted interpreta los valores del R2 de desviación y del R2 de desviación ajustado. En el formato de Evento/Ensayo, cada valor observado representa la probabilidad del evento para todos los ensayos en esa fila de los datos. Usualmente, esta probabilidad representa muchos ensayos y se encuentra entre 0 y 1. En cambio, cada observación en el formato de Respuesta binaria/Frecuencia suele representar solo 1 ensayo. El valor observado para un solo ensayo es 1 ó 0.
En general, la diferencia en los formatos de datos hace que la desviación total en los datos sea diferente. Para datos de Evento/Ensayo, la desviación se relaciona con la discrepancia entre las probabilidades pronosticadas y las probabilidades observadas. Para el formato de Respuesta binaria/Frecuencia, la desviación se relaciona con la discrepancia entre las probabilidades observadas y el resultado de 0% o 100% de cada ensayo. El R2 de desviación y el R2 de desviación ajustado usualmente son más altos para datos en formato de Evento/Ensayo.
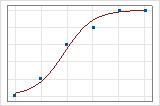
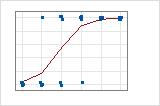
Una ilustración gráfica aclara la diferencia. En estas gráficas, los símbolos representan las observaciones en los datos y la curva representa los valores pronosticados en el modelo. Para datos de Evento/Ensayo, los símbolos se ubican cerca de la línea. El valor del R2 de desviación para los datos de Evento/Ensayo es aproximadamente 96%. El modelo pronostica muy bien las probabilidades promedio.
Para los datos de Respuesta binaria/Frecuencia, las observaciones se encuentran cerca de la línea pronosticada solo cuando la línea está cerca de 0% o 100%. El valor del R2 de desviación para los datos de Respuesta binaria/Frecuencia es aproximadamente 56%. La relación entre las probabilidades pronosticadas y los casos individuales no es tan fuerte.
Por qué la prueba de bondad de ajuste de desviación puede ser engañosa para datos de Respuesta binaria/Frecuencia.
Para regresión logística binaria, el formato de los datos afecta si las pruebas de bondad de ajuste de desviación son fiables. El valor p de la prueba de bondad de ajuste de desviación generalmente disminuye al igual que el número de ensayos por fila disminuye. Los datos en el formato de Respuesta binaria/Frecuencia usualmente tienen menos ensayos por fila. De esta forma, la prueba de bondad de ajuste de desviación probablemente indique un ajuste deficiente cuando los datos están en formato de Respuesta binaria/Frecuencia, incluso cuando el ajuste es adecuado. También es probable que la prueba de bondad de ajuste de desviación indique erróneamente un ajuste deficiente cuando los datos están en el formato de Evento/Ensayo, pero el número de ensayos por fila es pequeño.
La prueba de Hosmer-Lemeshow no depende del formato de los datos. Cuando los datos tienen pocos ensayos por fila, la prueba de Hosmer-Lemeshow es un indicador más fiable sobre qué tan bien se ajusta el modelo a los datos.
Compare estos dos conjuntos de resultados basados en los mismos datos en formatos diferentes. Para estos datos, la forma del modelo es correcta. La información de respuesta, los coeficientes y los resultados de la prueba de Hosmer-Lemeshow son iguales. La conclusión de la prueba de bondad de ajuste de desviación depende del formato de los datos.
En estos resultados, los datos están en el formato de Respuesta binaria/Frecuencia sin una columna de frecuencia. El análisis utiliza 500 filas de datos. Cada fila representa 1 ensayo. En el nivel de significancia de 0.05, el valor p de la prueba de bondad de ajuste de desviación indica que el modelo se ajusta deficientemente. Este valor p conduce a la conclusión incorrecta de que el formato del modelo es incorrecto. Si recolecta datos en el formato de Respuesta binaria/Frecuencia, la prueba de bondad de ajuste de desviación frecuentemente no es fiable.
Regresión logística binaria: Y vs. X
En estos resultados, los datos están en el formato de Evento/Ensayo. El análisis utiliza 5 filas de datos. Cada fila de datos representa 100 ensayos. En el nivel de significancia de 0.05, el valor p de la prueba de bondad de ajuste de desviación no encuentra evidencia de un modelo de ajuste deficiente. Si recolecta datos en formato de Evento/Ensayo, la prueba de bondad de ajuste de desviación es por lo general fiable.
Regresión logística binaria: Evento vs. X
Por qué la prueba de bondad de ajuste de Pearson puede ser engañosa para datos de Respuesta binaria/Frecuencia
Para regresión logística binaria, el formato de los datos afecta si la prueba de bondad de ajuste de Pearson es fiable. La aproximación a la distribución de chi-cuadrada que la prueba Pearson utiliza resulta inexacta cuando el número de eventos esperados por fila es pequeño. Los datos en el formato de Respuesta binaria/Frecuencia generalmente tienen menos ensayos por fila. Por lo tanto, es probable que la prueba de bondad de ajuste de Pearson resulte inexacta cuando los datos están en el formato de Respuesta binaria/Frecuencia.
La prueba de Hosmer-Lemeshow no depende del formato de los datos. Cuando los datos tienen pocos ensayos por fila, la prueba de Hosmer-Lemeshow es un indicador más fiable sobre qué tan bien se ajusta el modelo a los datos.
Compare estos dos conjuntos de resultados basados en los mismos datos en formatos diferentes. Para estos datos, la forma del modelo es incorrecta. El modelo verdadero contiene la interacción entre X1 y X2. La información de respuesta, los coeficientes y los resultados de la prueba de Hosmer-Lemeshow son iguales. La conclusión de la prueba de bondad de ajuste de Pearson depende del formato de los datos.
En estos resultados, los datos están en el formato de Respuesta binaria/Frecuencia con una columna de frecuencia. El análisis utiliza 18 filas de datos. Cada fila representa 250 ensayos de Bernoulli. En el nivel de significancia de 0.05, el valor p de la prueba de bondad de ajuste de Pearson indica que que el modelo se ajusta a los datos. El valor p conduce a la conclusión incorrecta de que el modelo es adecuado. Sio recolecta datos en el formato de Respuesta binaria/Frecuencia, la prueba de bondad de ajuste de Pearson no es fiable.
Regresión logística binaria: Y vs. X1, X2
En estos resultados, los datos están en el formato de Evento/Ensayo. El análisis utiliza 9 filas de datos. Cada fila de los datos representa 500 ensayos. En el nivel de significancia de 0.05, el valor p de la prueba de bondad de Pearson indica que el modelo no se ajusta a los datos. Si recolecta datos en el formato de Evento/Ensayo, la prueba de bondad de ajuste de Pearson generalmente es fiable.