En este tema
Paso 1. Determinar el número de componentes en el modelo
El objetivo con PLS es seleccionar un modelo con el número apropiado de componentes que tenga una capacidad predictiva adecuada. Cuando usted ajusta un modelo PLS, puede realizar una validación cruzada como ayuda para determinar el número óptimo de componentes en el modelo. Con la validación cruzada, Minitab selecciona el modelo con el valor más alto de R2 pronosticado. Si no utiliza validación cruzada, puede especificar el número de componentes que desea incluir en el modelo o usar el número predeterminado de componentes. El número predeterminado de componentes es 10 o el número de predictores incluidos en los datos, lo que sea menor. Examine la tabla Método para determinar cuántos componentes incluyó Minitab en el modelo. También puede examinar la gráfica Selección del modelo.
Cuando utilice PLS, seleccione un modelo con el menor número de componentes que expliquen una cantidad suficiente de la variabilidad en los predictores y las respuestas. Para determinar el mejor número de componentes para sus datos, examine la tabla Selección del modelo, incluyendo los valores de varianza de X, R2 y R2 pronosticado. El R2 pronosticado indica la capacidad predictiva del modelo y solo se muestra si usted realiza una validación cruzada.
En algunos casos, usted puede decidir usar un modelo diferente del modelo seleccionado inicialmente por Minitab. Si utilizó validación cruzada, compare el R2 y el R2 pronosticado. Consideremos un ejemplo donde retirar dos componentes del modelo que Minitab seleccionó solo reduce ligeramente el R2 pronosticado. Debido a que el R2 pronosticado disminuyó muy levemente, el modelo no está sobreajustado y es posible que usted decida que es el más conveniente para sus datos.
Un R2 pronosticado que sea sustancialmente menor que R2 puede indicar que el modelo está sobreajustado. Un modelo sobreajustado se produce cuando agrega términos o componentes de los efectos que no son importantes en la población, aunque pueden parecer importantes en los datos de la muestra. El modelo se adapta a los datos de la muestra y, por lo tanto, es posible que no sea útil para hacer predicciones acerca de la población.
Si no utiliza validación cruzada, puede examinar los valores de varianza de X en la tabla Selección del modelo para determinar cuánta varianza en la respuesta es explicada por cada modelo.
Método
| Validación cruzada | Dejar uno fuera |
|---|---|
| Componentes a evaluar | Conjunto |
| Número de componentes evaluados | 10 |
| Número de componentes seleccionados | 4 |
Método
| Validación cruzada | Ninguno |
|---|---|
| Componentes a calcular | Conjunto |
| Número de componentes calculados | 10 |
Resultado clave: Número de componentes
En estos resultados, en la primera tabla Método se utilizó validación cruzada y se seleccionó el modelo con 4 componentes. En la segunda tabla Método, no se usó validación cruzada. Minitab utiliza el modelo con 10 componentes, que es el valor predeterminado.
Selección y validación de modelo para Aroma
| Componentes | Varianza de X | Error | R-cuadrado | PRESS | R-cuadrado (pred.) |
|---|---|---|---|---|---|
| 1 | 0.158849 | 14.9389 | 0.637435 | 23.3439 | 0.433444 |
| 2 | 0.442267 | 12.2966 | 0.701564 | 21.0936 | 0.488060 |
| 3 | 0.522977 | 7.9761 | 0.806420 | 19.6136 | 0.523978 |
| 4 | 0.594546 | 6.6519 | 0.838559 | 18.1683 | 0.559056 |
| 5 | 5.8530 | 0.857948 | 19.2675 | 0.532379 | |
| 6 | 5.0123 | 0.878352 | 22.3739 | 0.456988 | |
| 7 | 4.3109 | 0.895374 | 24.0041 | 0.417421 | |
| 8 | 4.0866 | 0.900818 | 24.7736 | 0.398747 | |
| 9 | 3.5886 | 0.912904 | 24.9090 | 0.395460 | |
| 10 | 3.2750 | 0.920516 | 24.8293 | 0.397395 |
Resultado clave: Varianza de X, R-cuad., R-cuad. (pred)
En estos resultados, Minitab seleccionó el modelo con 4 componentes que tiene un valor de R2 pronosticado de aproximadamente 56%. Con base en la varianza de X, el modelo con 4 componentes explica casi el 60% de la varianza en los predictores. A medida que aumenta el número de componentes, también aumenta el valor de R2, pero el R2 pronosticado disminuye, lo que indica que es probable que los modelos con más componentes estén sobreajustados.
Paso 2. Determinar si los datos contienen valores atípicos o puntos de apalancamiento
Para determinar si el modelo se ajusta adecuadamente a los datos, debe examinar gráficas para tratar de detectar valores atípicos, puntos de apalancamiento y otros patrones. Si los datos contienen muchos valores atípicos o puntos de apalancamiento, es posible que el modelo no haga predicciones válidas.
- Valores atípicos: Observaciones con residuos estandarizados grandes que se encuentren fuera de las líneas de referencia horizontales de la gráfica.
- Puntos de apalancamiento: Las observaciones con valores de apalancamiento tienen puntuaciones de X alejadas del cero y se encuentran a la derecha de la línea de referencia vertical.
Para obtener más información sobre la gráfica de residuos vs. apalancamiento, vaya a Gráficas para Regresión de cuadrados mínimos parciales.
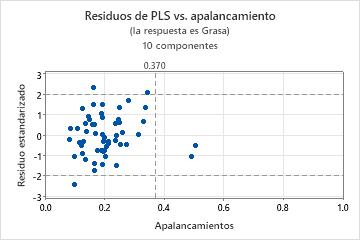
- Un patrón no lineal en los puntos, que indica que el modelo no puede ajustarse ni predecir los datos adecuadamente.
- Si realiza una validación cruzada, diferencias grandes en los valores ajustados y los valores ajustados con validación cruzada, que indican un punto de apalancamiento.
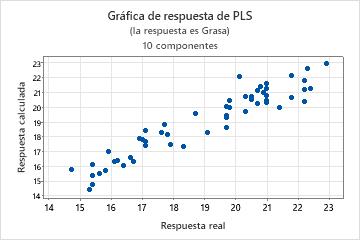
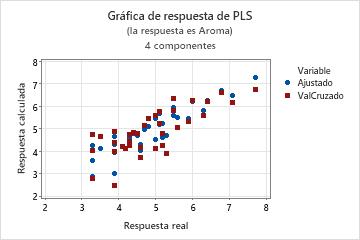
Paso 3. Validar el modelo PLS con un conjunto de datos de prueba
Con frecuencia, la regresión PLS se realiza en dos pasos. El primer paso, a veces denominado entrenamiento, consiste en calcular un modelo de regresión PLS para un conjunto de datos de muestra (también conocido como conjunto de datos de entrenamiento). El segundo paso consiste en validar este modelo con un conjunto diferente de datos, que suele llamarse conjunto de datos de prueba. Para validar el modelo con el conjunto de datos de prueba, ingrese las columnas de los datos de prueba en el cuadro de diálogo secundario Predicción. Minitab calcula los nuevos valores de respuesta para cada observación en el conjunto de datos de prueba y compara la respuesta pronosticada con la respuesta real. Con base en comparación, Minitab calcula el R2 de prueba, que indica la capacidad del modelo para predecir nuevas respuestas. Valores más altos del R2 de prueba indican que el modelo tiene una mayor capacidad predictiva.
Si utiliza validación cruzada, compare la prueba R2 con el R2-cuadrado pronosticado. Lo ideal es que estos valores sean similares. Una prueba R2 que es significativamente más pequeña que el R2 pronosticado indica que la validación cruzada es muy optimista acerca de la capacidad de predicción del modelo o que las dos muestras de datos pertenecen a poblaciones diferentes.
Si el conjunto de datos de prueba no incluye valores de respuesta, Minitab no calcula un R2 de prueba.
Respuesta pronosticada para las nuevas observaciones utilizando modelo para Grasa
| Fila | Ajuste | EE de ajuste | IC de 95% | IP de 95% |
|---|---|---|---|---|
| 1 | 18.7372 | 0.378459 | (17.9740, 19.5004) | (16.8612, 20.6132) |
| 2 | 15.3782 | 0.362762 | (14.6466, 16.1098) | (13.5149, 17.2415) |
| 3 | 20.7838 | 0.491134 | (19.7933, 21.7743) | (18.8044, 22.7632) |
| 4 | 14.3684 | 0.544761 | (13.2698, 15.4670) | (12.3328, 16.4040) |
| 5 | 16.6016 | 0.348485 | (15.8988, 17.3044) | (14.7494, 18.4538) |
| 6 | 20.7471 | 0.472648 | (19.7939, 21.7003) | (18.7861, 22.7080) |
Resultado clave: R2 de prueba
En estos resultados, el R2 de prueba es aproximadamente 76%. El R2 pronosticado para el conjunto de datos original es aproximadamente 78%. Puesto que estos valores son similares, usted puede concluir que el modelo tiene una capacidad predictiva adecuada.