En este tema
Modelo
Minitab calcula K – 1 funciones logit para un modelo con K categorías de respuesta. Por ejemplo, una respuesta con tres categorías (1, 2, 3) tiene dos funciones logit (evento de referencia = 3):
Fórmula
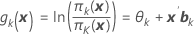
Notación
| Término | Description |
|---|---|
| gk(x) | función de enlace logit |
| θk | constante asociada con la késima categoría de respuesta distinta |
| xk | vector de variables predictoras |
| bk | vector de coeficientes asociados con la késimafunción logit |
Patrón de factor/covariable
Describe un conjunto individual de valores de factor/covariable en un conjunto de datos. Minitab calcula las probabilidades del evento, los residuos y otras medidas de diagnóstico para cada patrón de factor/covariable.
Por ejemplo, si un conjunto de datos incluye los factores sexo y raza y la covariable edad, la combinación de estos predictores puede contener tantos patrones diferentes de covariables como sujetos. Si un conjunto de datos solamente incluye los factores raza y sexo, cada uno codificado en dos niveles, solo hay cuatro patrones posibles de factor/covariable. Si usted ingresa los datos como frecuencias o como éxitos, ensayos o fracasos, cada fila contiene un patrón de factor/covariable.
Probabilidad del evento
Se denota como π. Para un modelo de tres categorías con las categorías 1, 2 y 3 (evento de referencia 3), las probabilidades condicionales son:
Fórmula
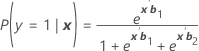
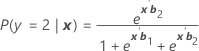
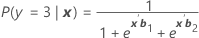
Y la probabilidad del evento es:
πk(x) = P(y = k|x) para k = 1, 2, 3. Cada probabilidad depende del vector de 2(p + 1) parámetros, b' = (b'1, b'2)
Log-verosimilitud
La función de log-verosimilitud se maximiza para producir valores óptimos de b. Para un modelo con 3 categorías de respuesta (referencia = 3), la función de log-verosimilitud es:
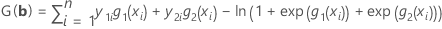
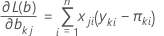
Las estimaciones de máxima verosimilitud se obtienen al establecer estas ecuaciones en cero y resolviendo b.
Notación
| Término | Description |
|---|---|
| k | 1, 2 |
| j | 0, 1, 2, ..., p |
| p | número de coeficientes en el modelo, sin incluir los coeficientes constantes |
| πki | πk(xi), con x0i para cada materia |
Coeficientes
Las estimaciones de máxima verosimilitud, también conocidas como estimaciones de parámetros. Si hay K valores de respuesta distintos, Minitab calcula K – 1 conjuntos de estimaciones de parámetros para cada predictor. Los efectos varían según la categoría de respuesta en comparación con el evento de referencia. Cada logit proporciona las diferencias estimadas en las probabilidades logarítmicas de una categoría de respuesta versus el evento de referencia. Los parámetros de las K – 1 ecuaciones determinan los parámetros de los logits al usar todos los demás pares de categorías de respuesta.
Los coeficientes estimados se calculan usando un método iterativo reponderado de mínimos cuadrados, que es equivalente a la estimación de máxima verosimilitud.1,2
Referencias
- D.W. Hosmer y S. Lemeshow (2000). Applied Logistic Regression. 2nd ed. John Wiley & Sons, Inc.
- P. McCullagh y J.A. Nelder (1992). Generalized Linear Model. Chapman & Hall.
Error estándar de los coeficientes
El error estándar asintótico, que indica la precisión del coeficiente estimado. Cuanto menor sea el error estándar, más precisa será la estimación.
Para obtener más información, véase [1] y [2].
- A. Agresti (1990). Categorical Data Analysis. John Wiley & Sons, Inc.
- P. McCullagh y J.A. Nelder (1992). Generalized Linear Model. Chapman & Hall.
Z
Z se utiliza para determinar si el predictor está significativamente relacionado con la respuesta. Valores absolutos más grandes de Z indican una relación significativa. El valor p indica donde se encuentra Z en la distribución normal.
Fórmula
Z = βi / error estándar
La fórmula para la constante es:
Z = θk / error estándar
Para muestras pequeñas, la prueba de relación de probabilidades puede ser una prueba de significancia más fiable.
Valor p (P)
Se utilizan en las pruebas de hipótesis como ayuda para decidir si se puede rechazar o no una hipótesis nula. El valor p es la probabilidad de obtener un estadístico de prueba que sea por lo menos tan extremo como el valor real calculado, si la hipótesis nula es verdadera. Un valor de corte que se utiliza comúnmente para el valor p es 0.05. Por ejemplo, si el valor p calculado de un estadístico de prueba es menor que 0.05, usted rechaza la hipótesis nula.
Relación de probabilidades
Útil en la interpretación de la relación entre un predictor y la respuesta.
La relación de probabilidades (q) puede ser cualquier número no negativo. Una relación de probabilidades de 1 sirve como base para la comparación. Si θ = 1, no hay ninguna asociación entre la respuesta y el predictor. Si θ > 1, las probabilidades de los eventos de la respuesta de comparación son mayores para el nivel de referencia del factor (o para niveles más altos de un predictor continuo). Si θ < 1, las probabilidades de los eventos de la respuesta de comparación son menores que el nivel de referencia del factor (o para niveles más altos de un predictor continuo). Los valores más alejados de 1 representan grados de asociación más fuertes.
Por ejemplo, para un modelo con tres categorías de respuesta (1, 2, 3) y un predictor, la relación de probabilidades especifica las probabilidades de la categoría de resultado k frente a la categoría de resultado utilizada como el evento de referencia (en este ejemplo, 3). La siguiente es una fórmula para la relación de probabilidades para un predictor con dos niveles: a y b.
Fórmula
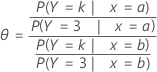
Notación
| Término | Description |
|---|---|
| k | categoría de resultado |
Intervalo de confianza
Fórmula
El intervalo de confianza de muestras grandes para βi es:
β i + Zα /2* (error estándar)
Para obtener el intervalo de confianza de la relación de probabilidades, eleve a una potencia los límites inferior y superior del intervalo de confianza. El intervalo proporciona el rango en el que podrían situarse las probabilidades para cada cambio de una unidad en el predictor.
Notación
| Término | Description |
|---|---|
| α | nivel de significancia |
Matriz de varianzas-covarianzas
Una matriz cuadrada con las dimensiones p +1 × (K – 1). La varianza de cada coeficiente se encuentra en la celda diagonal y la covarianza de cada par de coeficientes se encuentra en la celda adecuada adyacente a la diagonal. La varianza es el error estándar del coeficiente elevado al cuadrado.
La matriz de varianzas-covarianzas es asintótica y se obtiene a partir de la última iteración de la inversa de la matriz de información. La matriz de segundas derivadas parciales se utiliza para obtener la matriz de covarianzas.
Notación
| Término | Description |
|---|---|
| p | número de predictores |
| K | número de categorías en la respuesta |
Pearson
Un estadístico de resumen basado en los residuos de Pearson que indica qué tan bien se ajusta el modelo a los datos. Pearson no es útil cuando el número de valores distintos de la covariable es aproximadamente igual al número de observaciones, pero sí es útil cuando se tienen observaciones repetidas en el mismo nivel de la covariable. Estadísticos de prueba X2 más altos y valores p más bajos indican que el modelo podría no ajustarse adecuadamente a los datos.
La fórmula es:
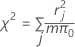
donde r = residuo de Pearson, m = número de ensayos en el jésimo patrón de factor/covariable y π0 = valor hipotético para la proporción.
Desviación
Un estadístico de resumen basado en los residuos de desviación que indica qué tan bien se ajusta el modelo a los datos. La desviación no es útil cuando el número de valores distintos de la covariable es aproximadamente igual al número de observaciones, pero sí es útil cuando se tienen observaciones repetidas en el mismo nivel de la covariable. Valores más altos de D y valores p más bajos indican que el modelo podría no ajustarse adecuadamente a los datos. Los grados de libertad para la prueba son (k - 1)* J − (p) donde k es el número de categorías en la respuesta, J es el número de patrones distintos de factor-covariable y p es el número de coeficientes.
La fórmula es:
D =2 Σ yik log p ik− 2 Σ yik log π ik
donde πik = probabilidad de la iésima observación para la késima categoría.