En este tema
Ajuste
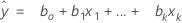
Notación
| Término | Description |
|---|---|
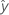 | valor ajustado |
| xk | késimo término. Cada término puede ser un solo predictor, un término polinómico o un término de interacción. |
| k | estimación del késimo coeficiente de regresión |
Error estándar del valor ajustado (EE ajuste)
El error estándar del valor ajustado en un modelo de regresión con un predictor es:

El error estándar del valor ajustado en un modelo de regresión con más de un predictor es:

Para la regresión ponderada, incluya la matriz de peso en la ecuación:

Cuando los datos tienen un conjunto de datos de prueba o una validación cruzada k-fold, las fórmulas son las mismas. El valor de s2 es de los datos de entrenamiento. La matriz de diseño y la matriz de peso también provienen de los datos de entrenamiento.
Notación
| Término | Description |
|---|---|
| s2 | mean square error |
| n | number of observations |
| x0 | new value of the predictor |
 | mean of the predictor |
| xi | i-ésimo predictor value |
| x0 | vector of values that produce the fitted values, one for each column in the design matrix, beginning with a 1 for the constant term |
| x'0 | transpose of the new vector of predictor values |
| X | design matrix |
| W | weight matrix |
Intervalo de confianza para un valor ajustado (IC)
Fórmula
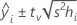
Para la regresión ponderada, la fórmula incluye las ponderaciones:
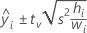
donde tv es el cuantil de 1–α/2 de la distribución t con v grados de libertad para un intervalo bilateral. Para un límite unilateral, tv es el cuantil de 1–α de la distribución t con v grados de libertad.
Cuando se utiliza un conjunto de datos de prueba o una validación cruzada de k pliegues, los grados de libertad y el cuadrado medio del error proceden del conjunto de datos de entrenamiento.
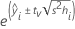
Notación
| Término | Description |
|---|---|
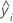 | fitted value |
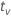 | quantile from the t distribution |
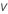 | degrees of freedom |
 | mean square error |
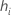 | leverage for the i-ésima observation |
| wi | weight for the i-ésima observation |
Residuos
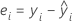
Notación
| Término | Description |
|---|---|
| yi | valor de la iésima respuesta observada |
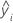 | iésimo valor ajustado para la respuesta |
Residuo estandarizado (Residuo est.)
Los residuos estandarizados también se denominan residuos "studentizados internamente".
Fórmula

Notación
| Término | Description |
|---|---|
| ei | i ésimo residuo |
| hi | i ésimo elemento diagonal de X(X'X)–1X' |
| s2 | cuadrado medio del error |
| X | matriz de diseño |
| X' | transpuesta de la matriz de diseño |
Residuo estandarizado (Resid est.) con validación
Fórmula

Para la regresión ponderada, la fórmula incluye la ponderación:
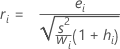
Notación
| Término | Description |
|---|---|
| ei | i-ésima residual in the validation data set |
| hi | leverage for the i-ésima validation row |
| s2 | mean square error for the training data set |
| wi | weight for the i-ésima observation in the validation data set |
Residuos eliminados (studentizados)
También conocidos como residuos studentizados externamente. La fórmula es:
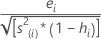
Otra presentación de esta fórmula es:

El modelo que estima la iésima observación, omite la iésimaobservación del conjunto de datos. Por lo tanto, la iésima observación no puede influir en la estimación. Cada residuo eliminado tiene una distribución t de Student con 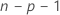 grados de libertad.
grados de libertad.
Notación
| Término | Description |
|---|---|
| ei | iésimo residuo |
| s(i)2 | cuadrado medio del error calculado sin la iésima observación |
| hi | iésimo elemento diagonal de X(X'X)–1X' |
| n | número de observaciones |
| p | número de términos, incluyendo la constante |
| SSE | suma de los cuadrados para el error |