En este tema
Apalancamientos (Hi)
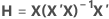
El apalancamiento de la iésima observación es el iésimo elemento diagonal, hi de H.. Si hi es grande, la iésima observación tiene predictores poco comunes (X1i, X2i, ..., Xpi). Es decir, los valores predictores están distantes del vector de medias 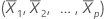 , usando la distancia de Mahalanobis.
, usando la distancia de Mahalanobis.
Los valores de apalancamiento están entre 0 y 1. Minitab identifica las observaciones con apalancamientos superiores a 3p/n o .99, el valor que sea menor, con una X en la tabla de observaciones poco comunes. Por lo general, usted examina los valores con apalancamientos grandes.
Notación
| Término | Description |
|---|---|
| X | matriz de diseño |
| hi | iésimo elemento diagonal de la matriz hat |
| p | número de términos en el modelo, incluyendo la constante |
| n | número de observaciones |
Apalancamientos (Hola) con validación
Fórmula

Para la regresión ponderada, la fórmula incluye la ponderación:
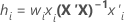
Notación
| Término | Description |
|---|---|
| X | design matrix for the rows in the training data set or the folds that act as the training data set |
| xi | the vector of predictors in the i-ésima validation row |
| wi | weight for the i-ésima validation row |
Distancia de Cook
La medida general, D, del impacto combinado de todos los coeficientes de regresión estimados sobre una observación. Minitab calcula D utilizando valores con apalancamiento y residuos estandarizados, y considera la posibilidad de que una observación sea poco común con respecto tanto a los valores de X como a los valores de Y. Las observaciones con valores grandes de D podrían ser valores atípicos.
Fórmula
La distancia de Cook es la distancia entre los coeficientes calculados con y sin la i ésima observación. Minitab calcula la distancia de Cook sin ajustar una nueva ecuación de regresión cada vez que se omite una observación. Este cálculo es:

Notación
| Término | Description |
|---|---|
| ei | iésimo residuo |
| hi | iésimo elemento diagonal de 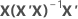 |
| p | número de parámetros del modelo, incluyendo la constante |
| s2 | cuadrado medio del error |
| b | vector de coeficientes |
| b(i) | vector de coeficientes calculado después de eliminar la iésima observación |
| X | matriz de diseño |
DFITS
Combina los valores de apalancamiento y de residuos studentizados (residuos t eliminados) en una medida general de qué tan poco común es una observación. DFITS mide la influencia de cada observación en los valores ajustados de un modelo de regresión y ANOVA. Las observaciones con valores grandes de DFITS podrían ser valores atípicos.
DFITS representa aproximadamente el número de desviaciones estándar que el valor ajustado cambia cuando cada observación es eliminada del conjunto de datos y se vuelve a ajustar el modelo. Minitab puede calcular DFITS sin ajustar una nueva ecuación de regresión cada vez que se omite una observación.
Fórmula

Notación
| Término | Description |
|---|---|
| ei | iésimo residuo |
| hi | iésimo elemento diagonal de 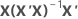 |
| X | matriz de diseño |
 | iésima respuesta ajustada |
 | valor ajustado calculado sin la iésima observación |
| MSE (i) | cuadrado medio del error calculado sin la iésima observación |
| n | número de observaciones |
| p | número de parámetros del modelo |
Factor de inflación de la varianza (FIV)
El FIV se puede obtener haciendo la regresión de cada predictor sobre los predictores restantes y registrando el valor de R2.
Fórmula
Para el predictor xj, el FIV es:

Notación
| Término | Description |
|---|---|
| R2(xj) | el coeficiente de determinación con xj como la variable de respuesta y los otros términos del modelo como los predictores |
Estadístico de Durbin-Watson
Evalúa la presencia de autocorrelación en los residuos al determinar si la correlación entre dos términos de error adyacentes es o no es igual a cero. La prueba se basa en el supuesto de que los errores son generados por un proceso autorregresivo de primer orden. Minitab parte del supuesto de que las observaciones están ordenadas significativamente, como un orden cronológico.

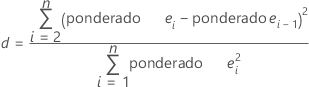
Notación
| Término | Description |
|---|---|
| ei | iésimo residuo |
| ei -1 | residuo de la observación anterior |
| n | número de observaciones |