En este tema
Familia exponencial y funciones de enlace
La extensión de los modelos lineales clásicos a modelos lineales generalizados consta de dos partes: una distribución de la familia exponencial y una función de enlace.
La familia exponencial
La primera parte extiende el modelo lineal a las variables de respuesta que son miembros de una familia grande de distribuciones llamada la familia exponencial. Los miembros de la familia exponencial de distribuciones tienen funciones de distribución de probabilidad para una respuesta observada con la siguiente forma general:
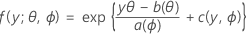
donde a(∙), b(∙) y c(∙) dependen de la distribución de la variable de respuesta. El parámetro θ es un parámetro de ubicación que suele mencionarse como el parámetro canónico y ϕ se denomina parámetro de dispersion. La función a(ϕ) por lo general tiene la forma a(ϕ)= ϕ/ ω, donde ω es una constante conocida o ponderación que puede variar de una observación a otra. (En Minitab, cuando se especifican ponderaciones, la función a(ϕ) se ajusta según corresponda.)
Los miembros de la familia exponencial pueden ser distribuciones discretas o distribuciones continuas. Las distribuciones normal y gamma son ejemplos de distribuciones continuas que son miembros de la familia exponencial. Las distribuciones binomial y de Poisson son ejemplos de distribuciones discretas que son miembros de la familia exponencial. La siguiente tabla contiene las características de algunas de estas distribuciones.
| Distribución | ϕ | b(θ) | a(φ) | c(y, ϕ) |
| Normal | σ2 | θ2/2 | φω |  |
| Binomial | 1 | 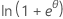 |
φ/ω | -ln(y!) |
| Poisson | 1 | exp(θ) | φ/ω |  |
La función de enlace
La segunda parte es la función de enlace. La función de enlace relaciona la media de la respuesta en la iésima observación con un predictor lineal que tiene esta forma:
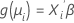
El modelo lineal clásico es un caso especial de esta formulación general donde la función de enlace es la función identidad.
La elección de la función de enlace en la segunda parte depende de la distribución específica de la familia exponencial de la primera parte. En particular, cada distribución de la familia exponencial tiene una función de enlace especial denominada función canónica de enlace. Esta función de enlace satisface la ecuación g (μi) = Xi'β= θ, donde θ es el parémetro canónico. La función canónica de enlace produce ciertas propiedades estadísticas deseables del modelo. Las estadísticas de bondad del ajuste se pueden usar para comparar ajustes utilizando diferentes funciones de enlace. Ciertas funciones de enlace se pueden utilizar por razones históricas o porque tienen un significado especial dentro de una disciplina. Por ejemplo, una ventaja de la función de enlace logit es que proporciona una estimación de las relaciones de probabilidades. Otro ejemplo es que la función de enlace normit presupone que hay una variable subyacente que sigue una distribución normal que se clasifica en categorías binarias.
Minitab provee tres funciones de enlace para cada clase de modelos. Las diferentes funciones de enlace permiten encontrar modelos que se ajustan adecuadamente a una variedad más amplia de datos.
Para los modelos binomiales, las funciones de enlace son logit, normit (también conocida como probit) y gompit (también denominada log-log complementario). Éstas son la inversa de la función de distribución logística acumulada estándar (logit), la inversa de la función de distribución normal acumulada estándar (normit) y la inversa de la función de distribución Gompertz (gompit). El logit es la función canónica de enlace para los modelos binomiales y, por lo tanto, el logit es la función de enlace predeterminada.
Para los modelos de Poisson, las funciones de enlace son el logaritmo natural, la raíz cuadrada y la identidad. El logaritmo natural es la función canónica de enlace para los modelos de Poisson y, por lo tanto, el logaritmo natural es la función de enlace predeterminada.
Las funciones de enlace se resumen a continuación:
| Modelo | Nombre | Función de enlace, g(μi) |
| Binomial | logit | 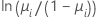 |
| Binomial | normit (probit) | 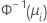 |
| Binomial | gompit (log-log complementario) |  |
| Poisson | logaritmo natural | 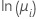 |
| Poisson | raíz cuadrada |  |
| Poisson | identidad | 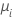 |
Notación
| Término | Description |
|---|---|
| μi | la respuesta media de la iésima fila |
| g(μi) | la función de enlace |
| X | el vector de las variables predictoras |
| β | el vector de los coeficientes asociado con los predictores |
 | la función de distribución acumulada inversa de la distribución normal |
Patrón de factor/covariable
Describe un conjunto individual de valores de factor/covariable en un conjunto de datos. Minitab calcula las probabilidades del evento, los residuos y otras medidas de diagnóstico para cada patrón de factor/covariable.
Por ejemplo, si un conjunto de datos incluye los factores sexo y raza y la covariable edad, la combinación de estos predictores puede contener tantos patrones diferentes de covariables como sujetos. Si un conjunto de datos solamente incluye los factores raza y sexo, cada uno codificado en dos niveles, solo hay cuatro patrones posibles de factor/covariable. Si usted ingresa los datos como frecuencias o como éxitos, ensayos o fracasos, cada fila contiene un patrón de factor/covariable.
Ponderaciones internas para Ajustar modelo logístico binario
Fórmula
- Logit
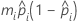
- Normit

- Gompit

Notación
| Término | Description |
|---|---|
| mi | the number of trials for the i-ésimo row |
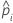 | the predicted probability for the design point in a binary logistic model |
| yi | the number of events for the i-ésimo row |
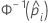 | the inverse cumulative distribution function of the standard normal distribution for the predicted probability in a binary logistic model |
Cómo elimina Minitab los predictores muy correlacionados de la ecuación de regresión en Ajustar modelo logístico binario
Sea rij el elemento de la matriz con barrido actual asociada con Xi y Xj.
Las variables se ingresan o se eliminan una a la vez. Xk es elegible para ingreso si es una variable independiente que no se encuentra actualmente en el modelo con rkk ≥ 1 (tolerancia con un valor predeterminado de 0.0001) y también para cada variable Xj que se encuentra actualmente en el modelo,

- Minitab aplica el método SWEEP (barrido) a la matriz de correlación, R, tratando a X1 … Xp como si fueran variables aleatorias.
- Para cualquier predictor continuo, Minitab compara el elemento rkk con la tolerancia; rkk ≥ tolerancia, donde k = 1 hasta p.
- Para cada variable Xj actualmente en el modelo, Minitab verifica que (rjj – rjk * (rkj / rkk)) * tolerancia ≤ 1.
Nota
Donde rkk, rjk, rjj son los elementos diagonales y fuera de la diagonal correspondientes para la variable Xj y Xk después de las operaciones SWEEP del paso k.
- De lo contrario, el predictor no pasa la prueba y es eliminado del modelo.
Nota
El valor de tolerancia predeterminado es 8.8e–12.
Nota
Usted puede usar el subcomando TOLERANCE con el comando de sesión GZLM para hacer que Minitab mantenga en el modelo un predictor que esté muy correlacionado con otro predictor. Sin embargo, bajar la tolerancia podría ser peligroso debido a la posibilidad de que se produzcan resultados numéricamente inexactos.