Nota
Este comando está disponible con el módulo del complemento para análisis predictivo. Haga doble clic aquí para obtener información sobre cómo activar el módulo.
Para el porcentaje de estadísticas de error, el valor depende del porcentaje de los residuos más grandes del cálculo. En las fórmulas siguientes, los cálculos suponen que los residuos están en orden según el valor absoluto, de modo que i - 1 representa el residuo con el mayor valor absoluto e i - N representa el residuo con el menor valor absoluto.
Cuando se utiliza la validación cruzada con k-fold, las estadísticas de entrenamiento incluyen los valores ajustados del árbol final para el conjunto de datos completo. Las estadísticas de prueba utilizan valores ajustados del proceso de validación que pueden tener árboles diferentes para cada pliegue.
Cuando se utiliza un conjunto de datos de prueba para la validación, las estadísticas de prueba utilizan valores ajustados solo para el conjunto de datos de prueba.
% MSE
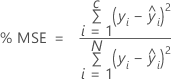
% MAD
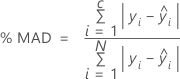
% MAPE
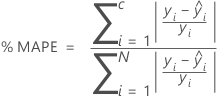
Notación
| Término | Description |
|---|---|
| c | conteo de residuos más grandes para el porcentaje |
| yi |  valor de respuesta observado valor de respuesta observado |
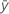 | respuesta media |
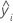 |  respuesta ajustada respuesta ajustada |
| N | número de filas |