Nota
Este comando está disponible con el Módulo de análisis predictivo. Haga doble clic aquí para obtener información sobre cómo activar el módulo.
Nota
Minitab muestra los resultados tanto del conjunto de datos de entrenamiento como de prueba. Los resultados de prueba indican si el modelo puede predecir adecuadamente los valores de respuesta para nuevas observaciones o resumir correctamente las relaciones entre la respuesta y las variables predictoras. Utilice los resultados de entrenamiento para evaluar el sobreajuste del modelo.
Total de predictores
El número total de predictores disponibles para el modelo TreeNet®. El total es la suma de los predictores continuos y categóricos que usted especifique.
Predictores importantes
El número de predictores importantes en el modelo TreeNet®. Los predictores importantes tienen puntuaciones de importancia mayores que 0.0. Puede utilizar la gráfica Importancia relativa de las variables para mostrar el orden de importancia relativa de las variables. Por ejemplo, supongamos que 10 de 20 predictores son importantes en el modelo, la gráfica Importancia relativa de las variables muestra las variables en orden de importancia.
Número de árboles cultivados
Por opción predeterminada, Minitab cultiva 300 árboles CART® pequeños para producir el modelo TreeNet®. Aunque este valor funciona bien para la exploración de los datos, considere cultivar más árboles para producir un modelo final. Para cambiar el número de árboles cultivados, vaya al cuadro de diálogo secundario Opciones.
Número óptimo de árboles
El número óptimo de árboles corresponde al valor más alto de R2 o al valor más bajo de MAD.
Cuando el número óptimo de árboles esté cerca del número máximo de árboles que el modelo cultiva, considere realizar un análisis con más árboles. Por lo tanto, si cultiva 300 árboles y el número óptimo determinado es 298, vuelva a construir el modelo con más árboles. Si el número óptimo sigue estando cerca del número máximo, continúe aumentando el número de árboles.
R-cuadrada
R2 es el porcentaje de variación en la respuesta explicado por el modelo. Los valores atípicos tienen un mayor efecto en R2 que en MAD y MAPE.
Cuando se utiliza un método de validación, la tabla incluye una estadística de R2 para el conjunto de datos de entrenamiento y una estadística de R2 para el conjunto de datos de prueba. Cuando el método de validación es la validación cruzada con k-fold, el conjunto de datos de prueba es cada grupo cuando la construcción del modelo excluye ese grupo. La estadística de R2 de prueba suele ser una mejor medida de cómo funciona el modelo para nuevos datos.
Interpretación
Utilice R2 para determinar qué tan bien se ajusta el modelo a los datos. Cuanto mayor sea el valor de R2, mejor se ajusta el modelo a los datos. R2 siempre está entre 0% y 100%.
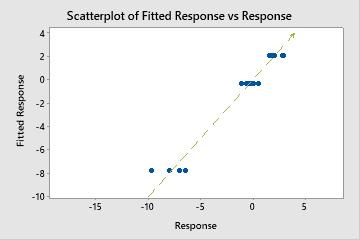
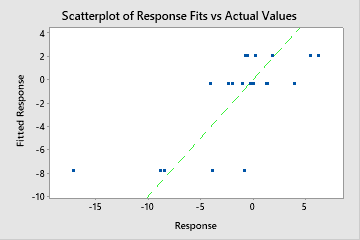
Un R2 de prueba que es sustancialmente menor que el R2de entrenamiento indica que el modelo podría no predecir los valores de respuesta para nuevos casos tan adecuadamente como se ajusta al conjunto de datos actual.
Raíz del error cuadrático medio (RMSE)
La raíz del error cuadrático medio (RMSE) mide la exactitud del modelo. Los valores atípicos tienen un mayor efecto en la RMSE que en la MAD y el MAPE.
Cuando se utiliza un método de validación, la tabla incluye una estadística RMSE para el conjunto de datos de entrenamiento y una estadística RMSE para el conjunto de datos de prueba. Cuando el método de validación es la validación cruzada con k-fold, el conjunto de datos de prueba es cada grupo cuando la construcción del modelo excluye ese grupo. La estadística RMSE de prueba suele ser una mejor medida de cómo funciona el modelo para nuevos datos.
Interpretación
Se utiliza para comparar los ajustes de diferentes modelos. Los valores más pequeños indican un mejor ajuste. Una RMSE de prueba que es sustancialmente mayor que la RMSE de entrenamiento indica que el modelo podría no predecir los valores de respuesta para nuevos casos tan adecuadamente como se ajusta al conjunto de datos actual.
Error cuadrático medio (MSE)
El error cuadrático medio (MSE) mide la exactitud del modelo. Los valores atípicos tienen un mayor efecto en el MSE que en la MAD y el MAPE.
Cuando se utiliza un método de validación, la tabla incluye una estadística MSE para el conjunto de datos de entrenamiento y una estadística MSE para el conjunto de datos de prueba. Cuando el método de validación es la validación cruzada con k-fold, el conjunto de datos de prueba es cada grupo cuando la construcción del modelo excluye ese grupo. La estadística MSE de prueba suele ser una mejor medida de cómo funciona el modelo para nuevos datos.
Interpretación
Se utiliza para comparar los ajustes de diferentes modelos. Los valores más pequeños indican un mejor ajuste. Un MSE de prueba que es sustancialmente mayor que el MSE de entrenamiento indica que el modelo podría no predecir los valores de respuesta para nuevos casos tan adecuadamente como se ajusta al conjunto de datos actual.
Desviación absoluta media (MAD)
La desviación absoluta media (MAD) expresa la exactitud en las mismas unidades que los datos, lo que ayuda a conceptualizar la cantidad de error. Los valores atípicos tienen menos efecto en la MAD que en R2, la RMSE y el MSE.
Cuando se utiliza un método de validación, la tabla incluye una estadística MAD para el conjunto de datos de entrenamiento y una estadística MAD para el conjunto de datos de prueba. Cuando el método de validación es la validación cruzada con k-fold, el conjunto de datos de prueba es cada grupo cuando la construcción del modelo excluye ese grupo. La estadística MAD de prueba suele ser una mejor medida de cómo funciona el modelo para nuevos datos.
Interpretación
Se utiliza para comparar los ajustes de diferentes modelos. Los valores más pequeños indican un mejor ajuste. Un MAD de prueba que es sustancialmente mayor que el MAD de entrenamiento indica que el modelo podría no predecir los valores de respuesta para nuevos casos tan adecuadamente como se ajusta al conjunto de datos actual.
Error porcentual absoluto medio (MAPE)
El error porcentual absoluto medio (MAPE) expresa la exactitud como un porcentaje del error. Dado que el MAPE es un porcentaje, puede ser más fácil de entender que las otras estadísticas de medición de exactitud. Por ejemplo, si el MAPE, en promedio, es 0.05, la relación promedio entre el error ajustado y el valor real en todos los casos es de 5%. Los valores atípicos tienen menos efecto en el MAPE que en el R2, la RMSE y el MSE.
Sin embargo, a veces puede ver un valor MAPE muy grande aunque el modelo parezca ajustarse bien a los datos. Examine la gráfica de valores de respuesta ajustados vs. reales para ver si hay valores de datos cercanos a 0. Dado que el MAPE divide el error absoluto entre los datos reales, los valores cercanos a 0 pueden inflar en gran medida el MAPE.
Cuando se utiliza un método de validación, la tabla incluye una estadística MAPE para el conjunto de datos de entrenamiento y una estadística MAPE para el conjunto de datos de prueba. Cuando el método de validación es la validación cruzada con k-fold, el conjunto de datos de prueba es cada grupo cuando la construcción del modelo excluye ese grupo. La estadística MAPE de prueba suele ser una mejor medida de cómo funciona el modelo para nuevos datos.
Interpretación
Se utiliza para comparar los ajustes de diferentes modelos. Los valores más pequeños indican un mejor ajuste. Un MAPE de prueba que es sustancialmente mayor que el MAPE de entrenamiento indica que el modelo podría no predecir los valores de respuesta para nuevos casos tan adecuadamente como se ajusta al conjunto de datos actual.