Nota
Este comando está disponible con el Módulo de análisis predictivo. Haga clic aquí para obtener más información sobre cómo activar el módulo.
Un equipo de investigadores recopila datos sobre los factores que afectan una característica de calidad de los pretzels horneados. Las variables incluyen la configuración del proceso, como herramienta de mezcla, y las propiedades del grano, como proteína de harina.
Como parte de la exploración inicial de los datos, los investigadores deciden utilizar Descubrir predictores clave modelos de comparación mediante la eliminación secuencial de predictores sin importancia para identificar los predictores clave. Los investigadores esperan identificar predictores clave que tengan grandes efectos en la característica de calidad y obtener más información sobre las relaciones entre la característica de calidad y los predictores clave.
- Abra los datos de muestra, aceptabilidad_pretzel.MWX.
- Elija .
- En la lista desplegable, seleccione Respuesta binaria.
- En Respuesta, ingrese 'Pretzel aceptable'.
- En Response event, seleccione 1 para indicar que el pretzel es aceptable.
- En Predictores continuos, ingrese 'proteína de harina'-'Densidad a granel'.
- En Predictores categóricos, ingrese 'herramienta de mezcla'-'método kiln'.
- Clic Eliminación de predictores.
- En Número máximo de pasos de eliminación el archivo 29.
- Haga clic en Aceptar en cada cuadro de diálogo.
Interpretar los resultados
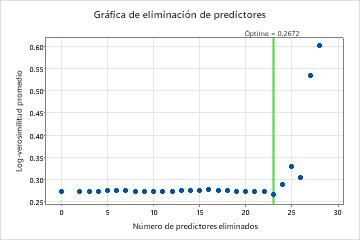
Para este análisis, Minitab Statistical Software compara 28 modelos. El número de pasos es menor que el número máximo de pasos porque el Estabilidad de espuma predictor tiene una puntuación de importancia de 0 en el primer modelo, por lo que el algoritmo elimina 2 variables en el primer paso. El asterisco de la columna Modelo de la tabla Evaluación de modelos muestra que el modelo con el valor más pequeño del estadístico promedio –loglikelihood es el modelo 23. Los resultados que siguen a la tabla de evaluación del modelo son para el modelo 23.
Aunque el modelo 23 tiene el valor más pequeño del estadístico promedio –logverosimilitud, otros modelos tienen valores similares. El equipo puede hacer clic Seleccionar modelo alternativo para generar resultados para otros modelos desde la tabla Evaluación de modelos.
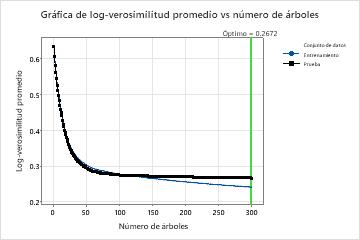
En los resultados del Modelo 23, la gráfica Average –Loglikelihood vs. Number of Trees muestra que el número óptimo de árboles es casi el número de árboles en el análisis. El equipo puede hacer clic Ajustar hiperparámetros para aumentar el número de árboles y ver si los cambios en otros hiperparámetros mejoran el rendimiento del modelo.
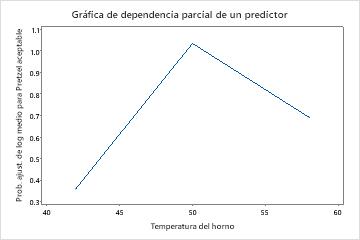
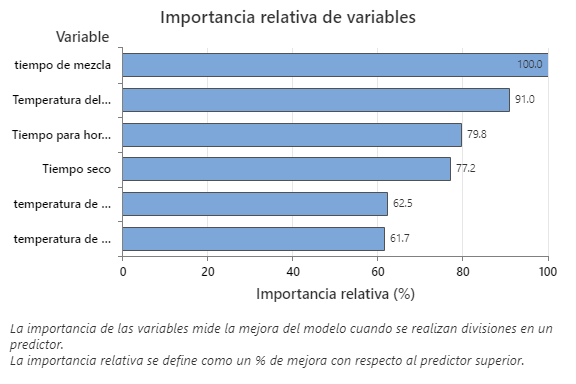
La gráfica Importancia relativa de las variables presenta los predictores en el orden de su efecto en la mejora del modelo cuando se realizan divisiones en un predictor sobre la secuencia de árboles. La variable predictora más importante es tiempo de mezcla. Si la importancia de la variable predictora principal, tiempo de mezcla, es del 100%, entonces la siguiente variable importante, Temperatura del horno, tiene una contribución del 91.0%. Esto significa que Temperatura del horno es un 91.0% tan importante como tiempo de mezcla.
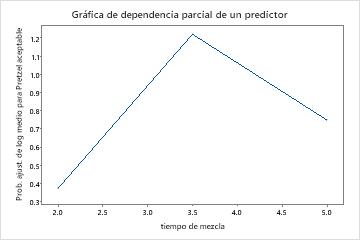
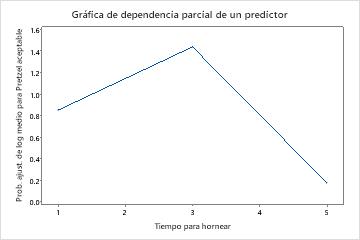
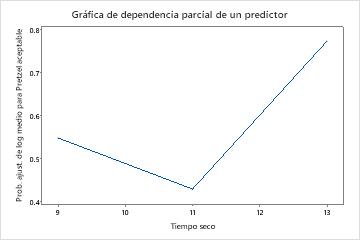
Utilice las gráficas de dependencia parcial para obtener información sobre cómo las variables o pares de variables importantes afectan los valores de respuesta ajustados. Los valores de respuesta ajustados están se encuentran en la escala semi-logarítmica. Las gráficas de dependencia parcial muestran si la relación entre la respuesta y una variable es lineal, monótona o más compleja.
Los gráficos de dependencia parcial de un predictor muestran que los valores medios para tiempo de mezcla, Temperatura del horno y Tiempo para hornear aumentan las probabilidades de un pretzel aceptable. Un valor medio de Tiempo seco disminuye las probabilidades de un pretzel aceptable. Los investigadores pueden seleccionar producir gráficos para otras variables.
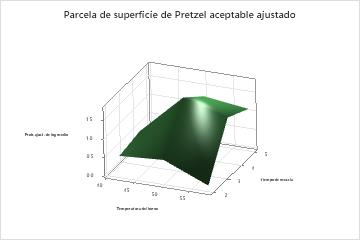
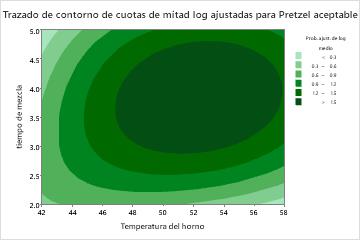
El gráfico de dependencia parcial de dos predictores muestra tiempo de mezcla Temperatura del horno una relación más compleja entre las dos variables y la respuesta. Si bien los valores medios de tiempo de mezcla y Temperatura del horno aumentan las probabilidades de un pretzel aceptable, el gráfico muestra que las mejores probabilidades ocurren cuando ambas variables están en valores medios. Los investigadores pueden seleccionar producir gráficos para otros pares de variables.
Método
| Criterio para seleccionar un número óptimo de árboles | Máxima logverosimilitud |
|---|---|
| Validación del modelo | 70/30% conjuntos de entrenamiento/prueba |
| Tasa de aprendizaje | 0.05 |
| Método de selección de submuestras | Completamente aleatorio |
| Fracción de submuestra | 0.5 |
| Máximo de nodos terminales por árbol | 6 |
| Tamaño mínimo del nodo terminal | 3 |
| Número de predictores seleccionados para la división de nodos | Número total de predictores = 29 |
| Filas utilizadas | 5000 |
Información de respuesta binaria
| Entrenamiento | Prueba | ||||
|---|---|---|---|---|---|
| Variable | Clase | Conteo | % | Conteo | % |
| Pretzel aceptable | 1 (Evento) | 2160 | 61.82 | 943 | 62.62 |
| 0 | 1334 | 38.18 | 563 | 37.38 | |
| Todo | 3494 | 100.00 | 1506 | 100.00 | |
Selección del modelo eliminando predictores no importantes
| Modelo | Número óptimo de árboles | Log-verosimilitud promedio | Número de predictores | Predictores eliminados |
|---|---|---|---|---|
| 1 | 268 | 0.273936 | 29 | Ninguno |
| 2 | 268 | 0.274186 | 27 | Estabilidad de espuma, Densidad a granel |
| 3 | 234 | 0.273843 | 26 | Concentración gelificación mín. |
| 4 | 233 | 0.274350 | 25 | Modo horno 2 |
| 5 | 232 | 0.274943 | 24 | método kiln |
| 6 | 273 | 0.275553 | 23 | Modo horno 1 |
| 7 | 244 | 0.274811 | 22 | velocidad de mezcla |
| 8 | 268 | 0.274258 | 21 | Modo horno 3 |
| 9 | 272 | 0.274185 | 20 | Superficie en reposo |
| 10 | 232 | 0.274077 | 19 | temperatura de hornear 3 |
| 11 | 287 | 0.273598 | 18 | herramienta de mezcla |
| 12 | 227 | 0.274358 | 17 | temperatura de hornear 1 |
| 13 | 276 | 0.275374 | 16 | Tiempo de descanso |
| 14 | 272 | 0.276082 | 15 | Agua |
| 15 | 268 | 0.275595 | 14 | Concentración cáustica |
| 16 | 268 | 0.277810 | 13 | capacidad de hinchazón |
| 17 | 253 | 0.276436 | 12 | Estabilidad de emulsión |
| 18 | 231 | 0.276159 | 11 | actividad de emulsión |
| 19 | 268 | 0.273537 | 10 | Capacidad de absorción de agua |
| 20 | 260 | 0.273455 | 9 | Capacidad absorción de aceite |
| 21 | 299 | 0.272848 | 8 | proteína de harina |
| 22 | 278 | 0.272629 | 7 | Capacidad de espuma |
| 23* | 299 | 0.267184 | 6 | tamaño de la harina |
| 24 | 297 | 0.288621 | 5 | temperatura de hornear 2 |
| 25 | 234 | 0.330342 | 4 | Tiempo seco |
| 26 | 290 | 0.305993 | 3 | temperatura de gelatinización |
| 27 | 245 | 0.534345 | 2 | Tiempo para hornear |
| 28 | 146 | 0.599837 | 1 | Temperatura del horno |
Resumen del modelo
| Total de predictores | 6 |
|---|---|
| Predictores importantes | 6 |
| Número de árboles cultivados | 300 |
| Número óptimo de árboles | 299 |
| Estadísticas | Entrenamiento | Prueba |
|---|---|---|
| Logverosimilitud promedio | 0.2418 | 0.2672 |
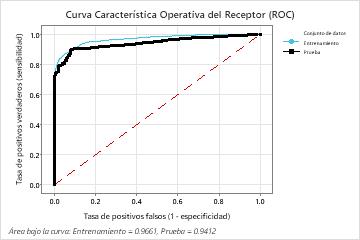
| Área bajo la curva ROC | 0.9661 | 0.9412 |
| IC de 95% | (0.9608, 0.9713) | (0.9295, 0.9529) |
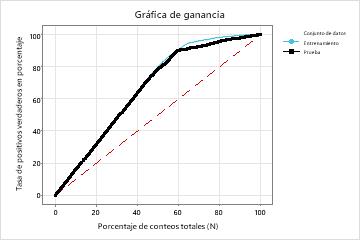
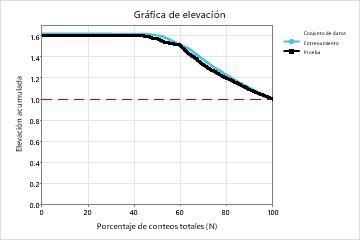
| Elevación | 1.6176 | 1.5970 |
| Tasa de clasificación errónea | 0.0970 | 0.0963 |
Matriz de confusión
| Clase de predicción (entrenamiento) | ||||||||
|---|---|---|---|---|---|---|---|---|
| Clase de predicción (prueba) | ||||||||
| Clase real | Conteo | 1 | 0 | % Correcto | Conteo | 1 | 0 | % Correcto |
| 1 (Evento) | 2160 | 1942 | 218 | 89.91 | 943 | 846 | 97 | 89.71 |
| 0 | 1334 | 121 | 1213 | 90.93 | 563 | 48 | 515 | 91.47 |
| Todo | 3494 | 2063 | 1431 | 90.30 | 1506 | 894 | 612 | 90.37 |
| Estadísticas | Entrenamiento (%) | Prueba (%) |
|---|---|---|
| Tasa de positivos verdaderos (sensibilidad o potencia) | 89.91 | 89.71 |
| Tasa de positivos falsos (error tipo I) | 9.07 | 8.53 |
| Tasa de negativos falsos (error tipo II) | 10.09 | 10.29 |
| Tasa de negativos verdaderos (especificidad) | 90.93 | 91.47 |
Clasificación errónea
| Entrenamiento | Prueba | |||||
|---|---|---|---|---|---|---|
| Conteo | Clasificado erróneamente | % Error | Conteo | Clasificado erróneamente | % Error | |
| Clase real | ||||||
| 1 (Evento) | 2160 | 218 | 10.09 | 943 | 97 | 10.29 |
| 0 | 1334 | 121 | 9.07 | 563 | 48 | 8.53 |
| Todo | 3494 | 339 | 9.70 | 1506 | 145 | 9.63 |