Nota
Este comando está disponible con el Módulo de análisis predictivo. Haga doble clic aquí para obtener información sobre cómo activar el módulo.
Variables importantes
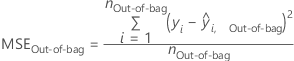
| Término | Description |
|---|---|
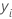 | valor de la variable de respuesta para la fila i |
 | número de filas que aparecen en los datos out-of-bag en todo el bosque |
 | predicción out-of-bag para la fila i |
Después, permute aleatoriamente los valores de una variable, xm a través de los datos out-of-bag. Deje iguales los valores de respuesta y los demás valores predictores. A continuación, siga los mismos pasos para calcular el error cuadrático medio de los datos permutados,  .
.
La importancia para la variable xm proviene de la diferencia de los dos errores cuadráticos medios:
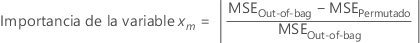
Minitab redondea los valores menores que 10–7 a 0.

Predicciones out-of-bag y de prueba
Los cálculos pronosticados para las siguientes medidas de precisión del modelo dependen del método de validación. Las predicciones out-of-bag provienen únicamente de los árboles donde una fila está out-of-bag. Para un árbol determinado, j, en el análisis, realice la predicción de los datos out-of-bag con el árbol. Repita la predicción para cada árbol del bosque. A continuación, calcule el promedio de las predicciones out-of-bag para cada fila que aparece al menos una vez en los datos out-of-bag. Para la evaluación del modelo con los datos out-of-bag, el promedio de la variable de respuesta es el promedio en todas las filas de los datos out-of-bag.
Para el conjunto de datos de prueba, use cada árbol del bosque para predecir cada valor del conjunto de datos de prueba. A continuación, promedie las predicciones de todos los árboles para obtener la predicción del modelo. Para la evaluación del modelo con el conjunto de prueba, la respuesta promedio es el promedio de filas del conjunto de prueba.
R-cuadrada
El cálculo de R2 utiliza los datos out-of-bag o los datos de prueba. Las predicciones difieren en estos dos casos. En general, la fórmula para R2 tiene la siguiente forma:

Raíz del error cuadrático medio (RMSE)

Error cuadrático medio (MSE)
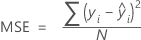
Desviación absoluta media (MAD)
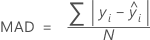
Error porcentual absoluto medio (MAPE)

Notación
| Término | Description |
|---|---|
| yi |  valor de respuesta observado valor de respuesta observado |
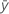 | respuesta media |
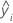 | valor de respuesta pronosticada para la fila 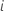 |
| N | número de filas |