Nota
Este comando está disponible con el Módulo de análisis predictivo. Haga clic aquí para obtener más información sobre cómo activar el módulo.
Un modelo de Random Forests® es un enfoque para resolver problemas de clasificación y regresión. El enfoque es más preciso y más robusto para los cambios en las variables predictoras que un árbol de clasificación o regresión individual. Una descripción amplia y general del proceso es que Minitab Statistical Software crea un árbol individual a partir de una muestra de la secuencia de arranque. Minitab selecciona de manera aleatoria un número menor de predictores del número total de predictores para evaluar el mejor divisor en cada nodo. Minitab repite este proceso para ampliar muchos árboles. En el caso de la clasificación, la clasificación de cada árbol es un voto para la clasificación pronosticada. Para una fila determinada de los datos, la clase con más votos es la clase pronosticada para esa fila en el conjunto de datos.
Para construir un árbol de clasificación, el algoritmo utiliza el criterio de Gini para medir la impureza de los nodos. Para la aplicación de escritorio, cada árbol crece hasta que un nodo es imposible de dividir o un nodo alcanza el número mínimo de casos para dividir un nodo interno. El número mínimo de casos es una opción para el análisis. Para la aplicación web, el análisis agrega la restricción de que cada árbol tiene un límite de 4.000 nodos terminales. Para obtener más detalles sobre la construcción de un árbol de clasificación, vaya a Método de división de nodos: Clasificación CART®. A continuación se detallan los detalles específicos de Random Forests® .
Ejemplos de Bootstrap
Para construir cada árbol, el algoritmo selecciona una muestra aleatoria con reemplazo (muestra de arranque) del conjunto de datos completo. Normalmente, cada ejemplo de arranque es diferente y puede contener un número diferente de filas únicas del conjunto de datos original. Si solo utiliza la validación fuera de bolsa, el tamaño predeterminado de la muestra de arranque es el tamaño del conjunto de datos original. Si divide la muestra en un conjunto de entrenamiento y un conjunto de prueba, el tamaño predeterminado de la muestra de arranque es el mismo que el tamaño del conjunto de entrenamiento. En cualquier caso, tiene la opción de especificar que la muestra de arranque sea menor que el tamaño predeterminado. En promedio, una muestra de arranque contiene aproximadamente 2/3 de las filas de datos. Las filas únicas de datos que no están en la muestra de arranque son los datos fuera de bolsa para la validación.
Selección aleatoria de predictores
En cada nodo del árbol, el algoritmo selecciona aleatoriamente un subconjunto del número total de predictores, 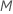 , para evaluar como divisores. De forma predeterminada, el algoritmo elige
, para evaluar como divisores. De forma predeterminada, el algoritmo elige  predictores a evaluar en cada nodo. Tiene la opción de elegir un número diferente de predictores para evaluar, de 1 a
predictores a evaluar en cada nodo. Tiene la opción de elegir un número diferente de predictores para evaluar, de 1 a 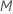 . Si eliges
. Si eliges 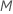 predictores, el algoritmo evalúa cada predictor en cada nodo, lo que da como resultado un análisis con el nombre "bosque de arranque".
predictores, el algoritmo evalúa cada predictor en cada nodo, lo que da como resultado un análisis con el nombre "bosque de arranque".
En un análisis que utiliza un subconjunto de predictores en cada nodo, los predictores evaluados suelen ser diferentes en cada nodo. La evaluación de diferentes predictores hace que los árboles del bosque estén menos correlacionados entre sí. Los árboles menos correlacionados crean un efecto de aprendizaje lento para que las predicciones mejoren a medida que se crean más árboles.
Validación con datos "out-of-bag”
Las filas únicas de datos que no forman parte del proceso de creación de árboles para un árbol determinado son los datos out-of-bag. Los cálculos para medir el rendimiento del modelo, como la probabilidad logarítmica media, utilizan los datos out-of-bag. Para obtener más información, vaya a Métodos y fórmulas para el resumen del modelo en Clasificación Random Forests®.
Para un árbol determinado del bosque, un voto de clase para una fila en los datos fuera de bolsa es la clase pronosticada para la fila del árbol único. La clase pronosticada para una fila en los datos fuera de bolsa es la clase con el voto más alto en todos los árboles del bosque.
La probabilidad de clase pronosticada para una fila en los datos fuera de bolsa es la relación entre el número de votos de la clase y el total de votos de la fila. La validación del modelo utiliza las clases pronosticadas, las probabilidades de clase pronosticadas y los valores de respuesta reales para todas las filas que aparecen al menos una vez en los datos fuera de bolsa.
Determinación de la clase pronosticada para una fila en el conjunto de entrenamiento
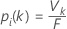
donde V k es el número de árboles que votan que la fila i está en la clase k y F es el número de árboles en el bosque.