Para determinar qué tan bien se ajusta el modelo a los datos, examine los estadísticos de la tabla Resumen del modelo.
Total de predictores
El número total de predictores disponibles para el modelo. Esta es la suma de los predictores continuos y los predictores categóricos que especifique.
Predictores importantes
El número de predictores importantes en el modelo. Los predictores importantes son las variables que tienen al menos 1 función base en el modelo.
Interpretación
Puede utilizar la gráfica de Importancia relativa de las variables para mostrar el orden de Importancia relativa de las variables. Por ejemplo, supongamos que 10 de 20 predictores tienen funciones base en el modelo, la gráfica Importancia relativa de la variable muestra las variables en orden de importancia.
Número máximo de funciones básicas
El número de funciones básicas que el algoritmo crea para buscar el modelo óptimo.
Interpretación
De forma predeterminada, Minitab Statistical Software establece el número máximo de funciones básicas en 30. Considere un valor mayor cuando 30 funciones básicas parecen demasiado pequeñas para los datos. Por ejemplo, considere un valor mayor cuando cree que más de 30 predictores son importantes.
Número óptimo de funciones básicas
El número de funciones básicas en el modelo óptimo.
Interpretación
Después de que el análisis estima el modelo con el número máximo de funciones base, el análisis utiliza un procedimiento de eliminación hacia atrás para eliminar las funciones base del modelo. Uno por uno, el análisis elimina la función base que menos contribuye al ajuste del modelo. En cada paso, el análisis calcula el valor del criterio de optimalidad para el análisis, ya sea R-cuadrado o desviación absoluta media. Una vez completado el procedimiento de eliminación, el número óptimo de funciones base es el número del procedimiento de eliminación que produce el valor óptimo del criterio.
R-cuadrado
R2 es el porcentaje de variación en la respuesta explicado por el modelo. Los valores atípicos tienen un mayor efecto en el R2 que en la MAD y el MAPE.
Cuando se utiliza un método de validación, la tabla incluye un estadístico R2 para el conjunto de datos de entrenamiento y un estadístico R2 para el conjunto de datos de prueba. Cuando el método de validación es la validación cruzada de k pliegues, el conjunto de datos de prueba es cada pliegue cuando la construcción del modelo excluye ese pliegue. El estadístico R2 de prueba suele ser una mejor medida de cómo funciona el modelo para nuevos datos.
Interpretación
Utilice R2 para determinar qué tan bien se ajusta el modelo a los datos. Cuanto mayor sea el valor de R2, mejor se ajusta el modelo a los datos. R2 siempre se encuentra entre 0% y 100%.
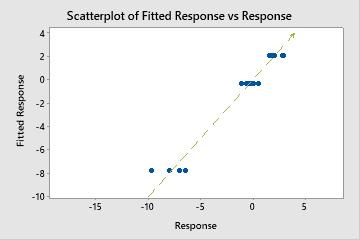
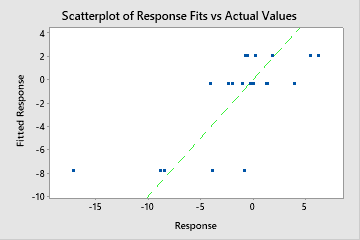
Un R2 de prueba que es sustancialmente menor que el R2de entrenamiento indica que el modelo podría no predecir los valores de respuesta para nuevos casos tan adecuadamente como se ajusta al conjunto de datos actual.
Raíz de los cuadrados medios del error (RMSE)
La raíz de los cuadrados medios del error (RMSE) mide la exactitud del modelo. Los valores atípicos tienen un mayor efecto en la RMSE que en la MAD y el MAPE.
Cuando se utiliza un método de validación, la tabla incluye un estadístico RMSE para el conjunto de datos de entrenamiento y un estadístico RMSE para el conjunto de datos de prueba. Cuando el método de validación es la validación cruzada de k pliegues, el conjunto de datos de prueba es cada pliegue cuando la construcción del modelo excluye ese pliegue. El estadístico RMSE de prueba suele ser una mejor medida de cómo funciona el modelo para nuevos datos.
Interpretación
Se utiliza para comparar los ajustes de diferentes modelos. Valores más pequeños indican un mejor ajuste. Una RMSE de prueba que es sustancialmente menor que la RMSE de entrenamiento indica que el modelo podría no predecir los valores de respuesta para nuevos casos tan adecuadamente como se ajusta al conjunto de datos actual.
Cuadrado medio del error (MSE)
El cuadrado medio del error (MSE) mide la exactitud del modelo. Los valores atípicos tienen un mayor efecto en el MSE que en la MAD y el MAPE.
Cuando se utiliza un método de validación, la tabla incluye un estadístico MSE para el conjunto de datos de entrenamiento y un estadístico MSE para el conjunto de datos de prueba. Cuando el método de validación es la validación cruzada de k pliegues, el conjunto de datos de prueba es cada pliegue cuando la construcción del modelo excluye ese pliegue. El estadístico MSE de prueba suele ser una mejor medida de cómo funciona el modelo para nuevos datos.
Interpretación
Se utiliza para comparar los ajustes de diferentes modelos. Valores más pequeños indican un mejor ajuste. Un MSE de prueba que es sustancialmente menor que el MSE de entrenamiento indica que el modelo podría no predecir los valores de respuesta para nuevos casos tan adecuadamente como se ajusta al conjunto de datos actual.
Desviación absoluta media (MAD)
La desviación absoluta media (MAD) expresa la exactitud en las mismas unidades que los datos, lo que ayuda a conceptualizar la cantidad de error. Los valores atípicos tienen menos efecto en la MAD que en el R2, la RMSE y el MSE.
Cuando se utiliza un método de validación, la tabla incluye un estadístico MAD para el conjunto de datos de entrenamiento y un estadístico MAD para el conjunto de datos de prueba. Cuando el método de validación es la validación cruzada de k pliegues, el conjunto de datos de prueba es cada pliegue cuando la construcción del modelo excluye ese pliegue. El estadístico MAD de prueba suele ser una mejor medida de cómo funciona el modelo para nuevos datos.
Interpretación
Se utiliza para comparar los ajustes de diferentes modelos. Valores más pequeños indican un mejor ajuste. Un MAD de prueba que es sustancialmente menor que el MAD de entrenamiento indica que el modelo podría no predecir los valores de respuesta para nuevos casos tan adecuadamente como se ajusta al conjunto de datos actual.