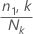El procedimiento para los puntos de la curva ROC depende del método de validación. Para una variable de respuesta multinomial, Minitab muestra múltiples gráficas que tratan a cada clase como el evento a su vez.
Conjunto de datos de entrenamiento o sin validación
Para la gráfica de un conjunto de datos de entrenamiento, cada punto de la gráfica representa un nodo terminal del árbol. El nodo terminal con la mayor probabilidad de evento es el primer punto de la gráfica y aparece más a la izquierda. Los otros nodos terminales están en orden decreciente de probabilidad de evento.
Utilice el siguiente proceso para buscar las coordenadas X e Y de la gráfica.
Calcule la probabilidad de evento de cada nodo terminal:
donde
n1,k es el número de eventos en el késimo nodo
Nk es el número de casos en el késimo nodo
Jerarquice los nodos terminales de mayor a menor probabilidad de evento.
Utilice cada probabilidad de evento como un valor umbral. Para un valor umbral específico, los casos con una probabilidad de evento estimada mayor que o igual al valor umbral obtienen 1 como la clase pronosticada, 0 en caso contrario. A continuación, puede formar una tabla 2x2 para todos los casos con clases observadas como filas y clases pronosticadas como columnas para calcular la tasa de falsos positivos y la tasa de verdaderos positivos para cada nodo terminal. Las tasas de falsos positivos son las coordenadas x para la gráfica. Las tasas de verdaderos positivos son las coordenadas y.
Por ejemplo, supongamos que la tabla siguiente resume un árbol con 4 nodos terminales:
A: Nodo terminal
B: Número de eventos
C: Número de no eventos
D: Número de casos
E: Valor umbral (B/D)
4
18
12
30
0.60
1
25
42
67
0.37
3
12
44
56
0.21
2
4
32
36
0.11
Totales
59
130
189
A continuación, las siguientes son las 4 tablas correspondientes con sus respectivas tasas de falsos positivos y tasas de verdaderos positivos a 2 decimales:
Utilice los mismos pasos que el procedimiento del conjunto de datos de entrenamiento, pero calcule la probabilidad de evento de los casos para el conjunto de datos de prueba.
Prueba con validación cruzada de k pliegues
El procedimiento para definir las coordenadas x e y en la gráfica de curvas ROC con validación cruzada de k pliegues tiene un paso adicional. Este paso crea muchas probabilidades de evento distintas. Por ejemplo, supongamos que el diagrama de árbol contiene 4 nodos terminales. Tenemos validación cruzada de 10 pliegues A continuación, para el i-ésimo pliegue, se utiliza la parte 9/10 de los datos para estimar las probabilidades del evento para los casos en el pliegue i. Cuando este proceso se repite para cada pliegue, el número máximo de probabilidades del evento distintas es de 4 *10 = 40. Después de eso, ordene todas las probabilidades de eventos distintos en orden decreciente. Utilice las probabilidades de eventos como cada uno de los valores umbrales para asignar clases pronosticadas para los casos de todo el conjunto de datos. Después de este paso, los pasos de 3 al final para el procedimiento del conjunto de datos de entrenamiento se aplican para encontrar las coordenadas x e y.