En este tema
Componentes principales
En el método de extracción de componentes principales, las jésimas influencias son los coeficientes ajustados de los jésimos componentes principales. Los factores se relacionan con los primeros m componentes. En la solución no rotada, usted puede interpretar los factores como interpretaría los componentes en el análisis de componentes principales. Sin embargo, después de la rotación, ya no puede interpretar los factores de manera similar a los componentes principales.
El análisis factorial de componentes principales de la matriz de correlación de la muestra R (o la matriz de covarianzas S) se especifica en términos de sus pares valor propio-vector propio (λi, ei), i = 1, ...,p y λ1 ≤ λ2 ≤ ... ≤ λp. Sea m < p el número de factores comunes. La matriz de influencias de los factores estimadas es una matriz p × m, L, cuya iésima columna es  , i = 1, ..., m.
, i = 1, ..., m.
Máxima verosimilitud
El método de máxima verosimilitud estima las influencias de los factores, presuponiendo que los datos siguen una distribución normal multivariada. Como su nombre implica, este método halla estimaciones de las influencias de los factores y varianzas únicas maximizando la función de verosimilitud asociada con el modelo normal multivariado. De manera equivalente, esto se realiza minimizando una expresión que involucre las varianzas de los residuos. El algoritmo itera hasta que se halla un mínimo o se alcanza el número máximo especificado de iteraciones (el valor predeterminado es 25).
Minitab utiliza un algoritmo con base en Joreskog,1,2 con algunos ajustes para mejorar la convergencia. Proporcionamos un breve resumen del algoritmo a continuación.
Supongamos que tenemos p variables y deseamos ajustar un modelo con m factores. Sea R la matriz de correlación p × p de las variables, L la matriz de influencias de los factores p × m y Ψ una matriz diagonal p × p cuyos elementos diagonales son las varianzas únicas, Ψi. Luego debemos hallar valores para L y Ψ que maximizan la función de verosimilitud, f(L,Ψ). Esto involucra un procedimiento de dos pasos, primero hallar un valor para Ψ y luego para L.
Usted puede especificar indirectamente el valor inicial de Ψ. En el cuadro de diálogo secundario Análisis factorial - Opciones, ingrese la columna que contiene los valores iniciales de las comunalidades en Utilizar estimaciones iniciales de comunalidad en. Minitab luego calcula los elementos diagonales de Ψ como (1 − comunalidades).
Para un valor fijo de Ψ, maximizamos f(L,Ψ) con respecto a L. Esto es un simple cálculo de matriz. El valor de L luego se sustituye en f(L,Ψ). Ahora f se puede ver como una función de Ψ. Una simple transformación de esta función da
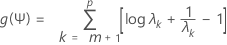
donde λ1 < λ2 < ... λp son valores propios de Ψ R- 1Ψ. Luego minimizamos g(Ψ), utilizando un procedimiento de Newton-Raphson. Esto proporciona una estimación de Ψ, que entonces se sustituye en la verosimilitud f(L,Ψ). Luego la verosimilitud se maximiza de nuevo con respecto a L. Después se calcula un nuevo valor para g(Ψ), y así sucesivamente. Por opción predeterminada, las iteraciones continúan hasta 25 pasos si no se alcanza convergencia. Si el algoritmo no converge en 25 pasos, se recomienda que cambie el número máximo predeterminado de iteraciones en el cuadro de diálogo secundario Opciones.
La convergencia se alcanza en el paso n, si cualquiera de los siguientes enunciados es verdadero:
- La función g(Ψ) no cambia mucho entre pasos consecutivos. Específicamente, si:
- | [g(Ψ) en el paso n] − [g(Ψ) en el paso (n − 1)] | < 10-6
- Ninguna de las varianzas únicas cambia mucho entre pasos consecutivos. Específicamente, si:
- | ln(Ψi en el paso n) − ln(Ψi en el paso n − 1) | < K2,
para todos los i = 1, ... , p, donde Ψi el iésimo elemento diagonal de Ψ, es la varianza única que corresponde a la variable i.
El valor de K2 se puede especificar en Convergencia en el cuadro de diálogo secundario Opciones. Por opción predeterminada, el valor es 0.005.
Elija Todos y las iteraciones de MLE en el cuadro de diálogo secundario Resultados para mostrar información sobre cada iteración. Se muestra el valor de la función objetivo, g(Ψ), luego el máximo cambia en ln(Ψi). Si, en una iteración, el valor de g(Ψ) no disminuye, entonces se toma un paso más pequeño (de la mitad del tamaño). Se continúa con los medios pasos hasta que g(Ψ) disminuye o se toman 25 medios pasos. El número de medios pasos se muestra. Si g(Ψ) no disminuye en 25 medios pasos, el algoritmo se detiene y se muestra un mensaje.
Se utiliza una matriz de segundas derivadas en la minimización de g(Ψ). Esta matriz no siempre es definida positiva. Si no lo es, se usa una aproximación. Se muestra un asterisco en los resultados cuando Minitab utiliza la matriz exacta.
Al minimizar la función g(Ψ), es posible hallar valores del elemento diagonal de Ψ que son 0 o negativos. Para evitar esto, el algoritmo de Minitab coloca bordes a los elementos diagonales de Ψ distantes de 0. Específicamente, si una varianza única Ψi es menor que K2, se establece en K2. K2 es el valor establecido en Convergencia en el cuadro de diálogo secundario Opciones.
Cuando el algoritmo converge, se realiza una verificación final en las varianzas únicas. Si cualquiera de las varianzas únicas es menor que K2, se establecen en 0. La comunalidad correspondiente es entonces igual a 1. Este resultado se denomina un caso de Heywood y Minitab muestra un mensaje para informar al usuario de este resultado. Los algoritmos de optimización, como el utilizado para el análisis factorial de máxima verosimilitud, pueden dar diferentes respuestas con cambios menores en la entrada. Por ejemplo, si usted cambia unos pocos puntos de datos, cambia los valores iniciales en Utilizar estimaciones iniciales de comunalidad en o cambia el criterio de convergencia en Convergencia, podría ver diferencias en los resultados del análisis factorial. Esto es especialmente verdadero si la solución se encuentra en un lugar relativamente plano en la superficie de máxima verosimilitud.
Rotación de las influencias
Una rotación ortogonal es una transformación ortogonal de las influencias de los factores que permite una interpretación más fácil de las influencias de los factores. Las influencias rotadas mantienen la matriz de correlación o covarianzas, las varianzas específicas y las comunalidades. Debido a que las comunalidades cambian, la varianza que representa cada factor y la proporción correspondiente cambian.
La rotación coloca los ejes cerca de tantos puntos como sea posible y asocia cada grupo de variables con un factor. Sin embargo, en algunos casos, una variable está cerca de más de un eje y se asocia por lo tanto con más de un factor.
Usted puede escoger entre cuatro métodos de rotación:
- Equimax - maximiza la varianza de las influencias cuadradas dentro de las variables y los factores.
- Varimax - maximiza la varianza de las influencias cuadradas dentro de los factores. Este método simplifica las columnas de la matriz de influencias y es el método de rotación más ampliamente utilizado. Para facilitar la interpretación, con este método se intenta hacer que las influencias sean grandes o pequeñas.
- Quartimax - maximiza la varianza de las influencias cuadradas dentro de las variables. Este método simplifica las filas de la matriz de influencias.
- Orthomax con γ - rotación que comprende las tres anteriores, dependiendo del valor del parámetro gamma (0 - 1).
Modelo de análisis factorial
El modelo de análisis factorial es:
X = μ + L F + e
donde X es el vector de mediciones p x 1, μ es el vector de medias p x 1, L es una matriz de influencias p × m, F es un vector de factores comunes m × 1 y e es un vector de residuos p × 1. Aquí, p representa el número de mediciones sobre un individuo o elemento y m representa el número de factores comunes. Se presupone que F y e son independientes y las F individuales son independientes unas de otras. La media de F y e son 0, Cov(F) = I, la matriz de identidad y Cov(e) = Ψ, una matriz diagonal. Los supuestos sobre independencia de las F hacen que este sea un método de factores ortogonales.
En el modelo de análisis factorial, la matriz de covarianzas p × p de los datos, X, se calcula de la siguiente manera:
Cov(X) = L L' + Ψ
donde L es la matriz de influencias p × m y Ψ es una matriz diagonal p × p. El iésimo elemento diagonal de L L', la suma de las influencias cuadradas, se denomina la iésima comunalidad. Los valores de comunalidad se pueden considerar como el porcentaje de variabilidad explicada por los factores comunes. El iésimo elemento diagonal de Ψ se denomina la iésima varianza específica o unicidad. La varianza específica es la porción de variabilidad no explicada por los factores comunes. Los tamaños de las comunalidades y/o varianzas específicas se pueden utilizar para evaluar la bondad de ajuste.
Influencias
Fórmula
Cuando se utiliza el método de componentes principales, la matriz de las influencias estimadas de los factores, L, viene dada por:
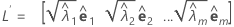
Cuando se utiliza el método de máxima verosimilitud, la matriz de las influencias de los factores se obtiene a través de un proceso iterativo.
Notación
| Término | Description |
|---|---|
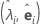 | pares valor propio-vector propio |
Comunalidades
Fórmula
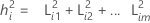
donde i = 1, 2 ... p
Notación
| Término | Description |
|---|---|
| L | matriz de influencias de factores |
Varianza
Variabilidad en los datos explicada por cada factor. La varianza es igual al valor propio si usted utiliza componentes principales para extraer factores y no rotar las influencias.
% Var
Fórmula
Cuando se utiliza una matriz de correlación, la proporción de varianza explicada por el jésimo factor se calcula de la siguiente manera:
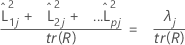
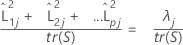
Notación
| Término | Description |
|---|---|
| L | matriz de influencias de factores |
| λj | jésimo valor propio |
| tr(R) | rastreo de matriz de correlación |
| tr(S) | rastreo matriz de covarianzas |
Coeficientes
Fórmula
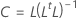
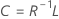
R es la matriz de correlación. Si la matriz para factores es la matriz de covarianza, R se sustituye por la matriz de covarianza.
Notación
| Término | Description |
|---|---|
| L | matriz de influencias de factores |
Puntuaciones
Fórmula
F = ZC
Notación
| Término | Description |
|---|---|
| F | matriz de puntuaciones de factores |
| Z | datos estandarizados |
| C | matriz de coeficientes de puntuación de factores |