En este tema
Distancia al cuadrado
Distancia al cuadrado de Mahalanobis - Forma general
La distancia al cuadrado (también denominada distancia de Mahalanobis) desde la observación x hasta el centro (media) del grupo t para la función discriminante lineal viene dada por la siguiente forma general:

Distancia al cuadrado de Mahalanobis - Función cuadrática
La distancia al cuadrado de Mahalanobis desde x hasta el grupo t para la función discriminante cuadrática se calcula de la siguiente manera:

Distancia al cuadrado generalizada - Función lineal
La distancia al cuadrado generalizada desde x hasta el grupo t para la función discriminante lineal se calcula de la siguiente manera:
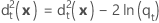
Distancia al cuadrado generalizada - Función cuadrática
La distancia al cuadrado generalizada desde x hasta el grupo t para la función discriminante cuadrática se calcula de la siguiente manera:

Probabilidad posterior
La probabilidad posterior de que x pertenezca al grupo t se calcula de la siguiente manera:
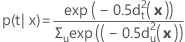
Puntuaciones discriminantes lineales
Las puntuaciones discriminantes lineales se calculan de la siguiente manera:

Notación
| Término | Description |
|---|---|
| x | vector de columnas de longitud p que contiene los valores de los predictores para esta observación (este vector de columnas se almacena como una fila) |
| p | número de predictores |
| n | número total de observaciones |
| t | subíndice de grupo |
| nt | número de observaciones en el grupo t |
| qt | la probabilidad previa del grupo t, que es igual a nt/n |
| Sp | matriz de covarianza agrupada para el análisis discriminante lineal |
| Si | matriz de covarianza del grupo i para el análisis discriminante cuadrático |
| mt | vector de columnas de longitud p que contiene las medias de los predictores calculadas a partir de los datos en el grupo t |
| St | matriz de covarianza del grupo t |
| |St| | determinante de St |
Función discriminante lineal

Para una x dada, esta regla asigna x al grupo con la mayor función discriminante lineal.
Notación
| Término | Description |
|---|---|
| x | vector de columnas de longitud p que contiene los valores de los predictores para esta observación (este vector de columnas se almacena como una fila) |
| mi | vector de columnas de longitud p que contiene las medias de los predictores calculadas a partir de los datos en el grupo i |
| Sp | matriz de covarianza agrupada |
| ln pi | logaritmo natural de la probabilidad previa del grupo i |
Distancia al cuadrado generalizada

Notación
| Término | Description |
|---|---|
| x | vector de columnas de longitud p que contiene los valores de los predictores para esta observación (este vector de columnas se almacena como una fila) |
| mi | vector de columnas de longitud p que contiene las medias de los predictores calculadas a partir de los datos en el grupo i |
| Sp | matriz de covarianza agrupada f |
| ln pi | logaritmo natural de la probabilidad previa del grupo i |
Probabilidad posterior
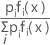
La probabilidad posterior más grande es equivalente al valor más grande de ln [pi fi (x)]


Notación
| Término | Description |
|---|---|
| pi | probabilidad previa del grupo i |
| fi(x) | la densidad conjunta para los datos en el grupo i (con los parámetros de población sustituidos por las estimaciones de la muestra) |