En este tema
Paso 1: Examinar los niveles de similitud y de distancia
En cada paso del proceso de amalgamación, vea los conglomerados que se forman y examine sus niveles de similitud y distancia. Cuanto mayor sea el nivel de similitud, más similares serán las observaciones de cada conglomerado. Cuanto menor sea el nivel de distancia, más cerca estarán las observaciones en cada conglomerado.
Lo ideal sería que los conglomerados tuvieran un nivel de similitud relativamente alto y un nivel de distancia relativamente bajo. Sin embargo, esa meta se debe equilibrar con tener un número razonable y práctico de conglomerados.
Pasos de amalgamación
| Paso | Número de conglomerados | Nivel de semejanzal | Nivel de distancia | Conglomerados incorporados | Nuevo conglomerado | Número de obs. en el conglomerado nuevo | |
|---|---|---|---|---|---|---|---|
| 1 | 19 | 96.6005 | 0.16275 | 13 | 16 | 13 | 2 |
| 2 | 18 | 95.4642 | 0.21715 | 17 | 20 | 17 | 2 |
| 3 | 17 | 95.2648 | 0.22669 | 6 | 9 | 6 | 2 |
| 4 | 16 | 92.9178 | 0.33905 | 17 | 18 | 17 | 3 |
| 5 | 15 | 90.5296 | 0.45339 | 11 | 15 | 11 | 2 |
| 6 | 14 | 90.3124 | 0.46378 | 12 | 19 | 12 | 2 |
| 7 | 13 | 88.2431 | 0.56285 | 2 | 14 | 2 | 2 |
| 8 | 12 | 88.2431 | 0.56285 | 5 | 8 | 5 | 2 |
| 9 | 11 | 85.9744 | 0.67146 | 6 | 10 | 6 | 3 |
| 10 | 10 | 83.0639 | 0.81080 | 7 | 13 | 7 | 3 |
| 11 | 9 | 83.0639 | 0.81080 | 1 | 3 | 1 | 2 |
| 12 | 8 | 81.4039 | 0.89027 | 2 | 17 | 2 | 5 |
| 13 | 7 | 79.8185 | 0.96617 | 6 | 11 | 6 | 5 |
| 14 | 6 | 78.7534 | 1.01716 | 4 | 12 | 4 | 3 |
| 15 | 5 | 66.2112 | 1.61760 | 2 | 5 | 2 | 7 |
| 16 | 4 | 62.0036 | 1.81904 | 1 | 6 | 1 | 7 |
| 17 | 3 | 41.0474 | 2.82229 | 1 | 4 | 1 | 10 |
| 18 | 2 | 40.1718 | 2.86421 | 2 | 7 | 2 | 10 |
| 19 | 1 | 0.0000 | 4.78739 | 1 | 2 | 1 | 20 |
Resultados clave: Nivel similitud, nivel de distancia
En estos resultados, los datos contienen un total de 20 observaciones. En el paso 1, dos conglomerados (las observaciones 13 y 16 de la hoja de trabajo) se unen para formar un nuevo conglomerado. Este paso crea 19 conglomerados en los datos, con un nivel de similitud de 96.6005 y un nivel de distancia de 0.16275. Aunque el nivel de similitud es alto y el nivel de distancia es bajo, el número de conglomerados es demasiado alto como para ser útil. En cada paso posterior, a medida que se forman nuevos conglomerados, el nivel de similitud disminuye y el nivel de distancia aumenta. En el paso final, todas las observaciones se unen en un único conglomerado.
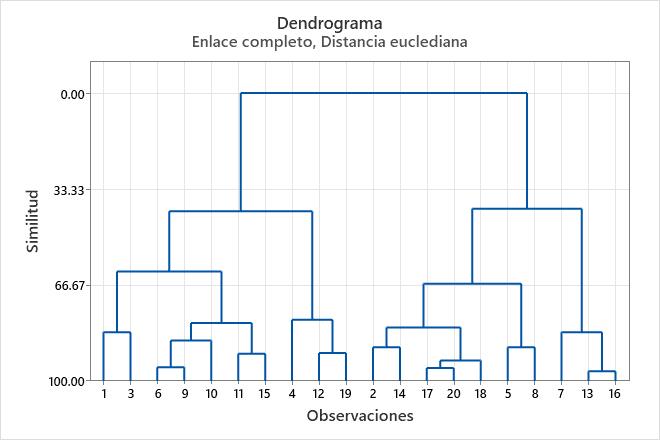
Para ver los niveles de similitud en el dendrograma, coloque el puntero del ratón sobre una línea horizontal en el diagrama de árbol, en Minitab.
Paso 2: Determinar las agrupaciones finales para los datos
Utilice el nivel de similitud de los conglomerados que se unen en cada paso como ayuda para determinar las agrupaciones finales para los datos.Busque un cambio abrupto en el nivel de similitud entre los pasos. El paso que precede al cambio abrupto en la similitud puede representar un punto de corte adecuado para la partición final. Para la partición final, los conglomerados deben tener un nivel de similitud razonablemente alto. También debería utilizar su conocimiento práctico de los datos para determinar las agrupaciones finales que tienen más sentido para su aplicación.
Por ejemplo, la siguiente tabla de amalgamación muestra que el nivel de similitud disminuye en incrementos de aproximadamente 3 o menos hasta el paso 15. La similitud disminuye en más de 20 (de 62.0036 a 41.0474) en los pasos 16 y 17, cuando el número de conglomerados cambia de 4 a 3. Estos resultados indican que 4 conglomerados pueden ser suficientes para la partición final. Si esta agrupación tiene sentido intuitivo, entonces es probable que sea una elección adecuada.
Pasos de amalgamación
| Paso | Número de conglomerados | Nivel de semejanzal | Nivel de distancia | Conglomerados incorporados | Nuevo conglomerado | Número de obs. en el conglomerado nuevo | |
|---|---|---|---|---|---|---|---|
| 1 | 19 | 96.6005 | 0.16275 | 13 | 16 | 13 | 2 |
| 2 | 18 | 95.4642 | 0.21715 | 17 | 20 | 17 | 2 |
| 3 | 17 | 95.2648 | 0.22669 | 6 | 9 | 6 | 2 |
| 4 | 16 | 92.9178 | 0.33905 | 17 | 18 | 17 | 3 |
| 5 | 15 | 90.5296 | 0.45339 | 11 | 15 | 11 | 2 |
| 6 | 14 | 90.3124 | 0.46378 | 12 | 19 | 12 | 2 |
| 7 | 13 | 88.2431 | 0.56285 | 2 | 14 | 2 | 2 |
| 8 | 12 | 88.2431 | 0.56285 | 5 | 8 | 5 | 2 |
| 9 | 11 | 85.9744 | 0.67146 | 6 | 10 | 6 | 3 |
| 10 | 10 | 83.0639 | 0.81080 | 7 | 13 | 7 | 3 |
| 11 | 9 | 83.0639 | 0.81080 | 1 | 3 | 1 | 2 |
| 12 | 8 | 81.4039 | 0.89027 | 2 | 17 | 2 | 5 |
| 13 | 7 | 79.8185 | 0.96617 | 6 | 11 | 6 | 5 |
| 14 | 6 | 78.7534 | 1.01716 | 4 | 12 | 4 | 3 |
| 15 | 5 | 66.2112 | 1.61760 | 2 | 5 | 2 | 7 |
| 16 | 4 | 62.0036 | 1.81904 | 1 | 6 | 1 | 7 |
| 17 | 3 | 41.0474 | 2.82229 | 1 | 4 | 1 | 10 |
| 18 | 2 | 40.1718 | 2.86421 | 2 | 7 | 2 | 10 |
| 19 | 1 | 0.0000 | 4.78739 | 1 | 2 | 1 | 20 |
Resultados clave: Nivel de similitud, número de conglomerados
La decisión acerca de la agrupación final también se conoce como cortar el dendrograma. Cortar el dendrograma es similar a trazar una línea horizontal a lo largo del dendrograma para especificar la agrupación final. Por ejemplo, para cortar este dendrograma en cuatro conglomerados, imagine trazar una línea horizontal alrededor de la mitad del eje vertical, justo por debajo del nivel de similitud de aproximadamente 41.
Paso 3: Examinar la partición final
Después de determinar las agrupaciones finales en el paso 2, vuelva a ejecutar el análisis y especifique el número de conglomerados (o el nivel de similitud) de la partición final. Minitab muestra la tabla de la partición final, que muestra las características de cada conglomerado incluido en la partición final. Por ejemplo, la distancia promedio desde el centroide proporciona una medida de la variabilidad de las observaciones dentro de cada conglomerado.
Nota
Para obtener más información sobre estos estadísticos, vaya a Partición final.
Partición final
| Número de observaciones | Dentro de la suma de cuadrados del conglomerado | Distancia promedio desde el centroide | Distancia máxima desde centroide | |
|---|---|---|---|---|
| Conglomerado1 | 7 | 3.25713 | 0.612540 | 1.12081 |
| Conglomerado2 | 7 | 2.72247 | 0.581390 | 0.95186 |
| Conglomerado3 | 3 | 0.55977 | 0.398964 | 0.54907 |
| Conglomerado4 | 3 | 0.37116 | 0.326533 | 0.48848 |
Centroides de grupo
| Variable | Conglomerado1 | Conglomerado2 | Conglomerado3 | Conglomerado4 | Centroide principal |
|---|---|---|---|---|---|
| Sexo | 0.97468 | -0.97468 | 0.97468 | -0.97468 | -0.0000000 |
| Altura | -1.00352 | 1.01283 | -0.37277 | 0.35105 | 0.0000000 |
| Peso | -0.90672 | 0.93927 | -0.86797 | 0.79203 | -0.0000000 |
| Pref mano | 0.63808 | 0.63808 | -1.48885 | -1.48885 | 0.0000000 |
Las distancias entre los centroides de conglomerados
| Conglomerado1 | Conglomerado2 | Conglomerado3 | Conglomerado4 | |
|---|---|---|---|---|
| Conglomerado1 | 0.00000 | 3.35759 | 2.21882 | 3.61171 |
| Conglomerado2 | 3.35759 | 0.00000 | 3.67557 | 2.23236 |
| Conglomerado3 | 2.21882 | 3.67557 | 0.00000 | 2.66074 |
| Conglomerado4 | 3.61171 | 2.23236 | 2.66074 | 0.00000 |
Resultados clave: Partición final, dendrograma
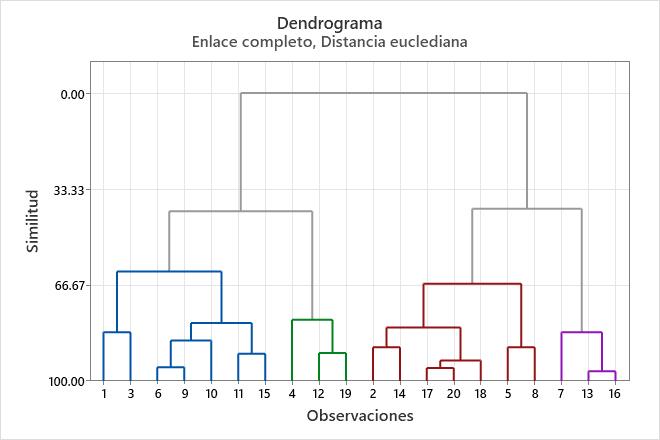
Este dendrograma se creó usando una partición final de 4 conglomerados, lo cual ocurre a un nivel de similitud de aproximadamente 40. El primer conglomerado (extremo izquierdo) se compone de siete observaciones (las observaciones de filas 1, 3, 6, 9, 10, 11 y 15 de la hoja de trabajo). El segundo conglomerado, inmediatamente a la derecha, se compone de 3 observaciones (las observaciones de las filas 4, 12 y 19 de la hoja de trabajo). El tercer grupo se compone de 7 observaciones (las observaciones de las filas 2, 14, 17, 20, 18, 5 y 8). El cuarto conglomerado, en el extremo derecho, se compone de 3 observaciones (las observaciones de las filas 7, 13 y 16). Si se cortara el dendrograma más arriba, entonces habría menos conglomerados finales, pero su nivel de similitud sería menor. Si se cortara el dendrograma más abajo, entonces el nivel de similitud sería mayor, pero habría más conglomerados finales.