En este tema
Método de estimación
Usted puede seleccionar Máxima verosimilitud restringida (REML) o Máxima verosimilitud (ML). Por lo general, se utiliza Máxima verosimilitud restringida (REML) porque el estimador de los componentes de la varianza por REML es aproximadamente insesgado, mientras que el estimador de máxima verosimilitud (ML) es sesgado. Sin embargo, el sesgo se vuelve más pequeño cuando los tamaños de las muestras son grandes.
Utilice Máxima verosimilitud (ML) si necesita comprobar si un modelo anidado con un menor número de términos de efecto fijo es tan adecuado como su modelo de referencia correspondiente que tiene más términos de efecto fijo, dado que ambos modelos tengan el mismo número de términos aleatorios y estructura de varianza del error. Específicamente, sea  la -2 log verosimilitud del modelo completo y
la -2 log verosimilitud del modelo completo y  la -2 log verosimilitud del modelo más pequeño.
la -2 log verosimilitud del modelo más pequeño.
Bajo la hipótesis nula, asintóticamente, 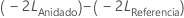 sigue una distribución de chi-cuadrada con grados de libertad iguales a la diferencia en el número de parámetros para los términos de efecto fijo entre el modelo de referencia y el modelo anidado. Puede utilizar la prueba de relación de verosimilitud para determinar si un subconjunto de términos de efecto fijo puede eliminarse del modelo de referencia.
sigue una distribución de chi-cuadrada con grados de libertad iguales a la diferencia en el número de parámetros para los términos de efecto fijo entre el modelo de referencia y el modelo anidado. Puede utilizar la prueba de relación de verosimilitud para determinar si un subconjunto de términos de efecto fijo puede eliminarse del modelo de referencia.
Para obtener más información sobre la prueba de relación de verosimilitud de parámetros fijos en un modelo de efectos mixtos, consulte a B. T. West, K.B. Welch y A.T. Gałecki (2007). Linear Mixed Models: A Practical Guide Using Statistical Software, First Edition. Chapman and Hall/CRC (34–36).
Método de prueba para efectos fijos
Comúnmente se utiliza Aproximación de Kenward-Roger porque los cálculos incluyen un ajuste que reduce el sesgo ocasionado por los tamaños de muestra pequeños. También puede utilizar Aproximación de Satterthwaite. En general, cuanto más grande sea el tamaño de la muestra, menor será la diferencia entre los dos métodos.
Ponderaciones
En Ponderaciones, ingrese una columna numérica de ponderaciones para todos los valores de respuesta. Utilice Ponderaciones si la varianza del error aleatorio dentro de los valores de respuesta no es constante. En cambio, para cada valor de respuesta, la varianza es igual a la inversa de la ponderación correspondiente multiplicada por una constante.
Las ponderaciones deben ser mayores que o iguales a cero. La columna de ponderaciones debe tener el mismo número de filas que la columna de respuestas.
Nivel de confianza para todos los intervalos
Ingrese el nivel de confianza para todos los intervalos de confianza incluidos en la salida.
Por lo general, un nivel de confianza de 95% funciona adecuadamente. Un nivel de confianza de 95% indica que, si usted tomara 100 muestras aleatorias de la población para un parámetro de interés, los intervalos de confianza para aproximadamente 95 de las muestras contendrían el verdadero valor del parámetro desconocido. Para un conjunto determinado de datos, un nivel de confianza más bajo produce un intervalo más estrecho y un nivel de confianza más alto produce un intervalo más amplio.
Nota
Para mostrar los intervalos de confianza, debe ir al cuadro de diálogo secundario Resultados y, en Presentación de resultados, seleccione Tablas expandidas.
Tipo de intervalo de confianza
Usted puede seleccionar un intervalo bilateral o un borde unilateral. Para el mismo intervalo de confianza, un borde está más cerca de la estimación de punto que del intervalo. El borde superior no proporciona un valor inferior probable. El borde inferior no proporciona un valor superior probable.
- Bilateral
-
- Utilice un intervalo de confianza bilareral para estimar los valores probables inferior y superior para el parámetro de interés.
- Límite inferior
-
- Utilice un límite de confianza inferior para estimar un valor inferior probable para el parámetro de interés.
- Límite superior
-
- Utilice un límite de confianza superior para estimar un valor superior probable para el parámetro de interés.
Medias
Usted puede mostrar las medias ajustadas de los efectos principales, las interacciones de dos factores o todos los términos incluidos en el modelo en la salida. Alternativamente, puede mostrar las medias de un subconjunto de estos términos o ningún término.
Si selecciona Términos especificados, utilice el botón I = Calcular las medas del término del término para identificar los términos. Seleccione un término en la lista y luego presione el botón. Un I indica que se mostrará la media del término. Si un término que espera ver en la lista no aparece, tendrá que agregarlo al modelo.